 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSF-Flow: Sound field magnitude estimation via flow matching guided by sparse measurements
May 11, 2026Reconstructing a 3D sound field from sparse microphone measurements is a fundamental yet ill-posed problem, which we address through Acoustic Transfer Function (ATF) magnitude estimation. ATF magnitude encapsulates key perceptual and acoustic properties of a physical space with applications in room characterization and correction. Although recent generative paradigms such as Flow Matching (FM) have achieved state-of-the-art performance in speech and music generation, their potential in spatial audio remains underexplored. We propose a novel framework for 3D ATF magnitude reconstruction as a guided generation task, with a 3D U-Net conditioned by a permutation-invariant set encoder. This architecture enables reconstruction from an arbitrary number of sparse inputs while leveraging the stable and efficient training properties of FM. Experimental results demonstrate that SF-Flow achieves accurate reconstruction up to \SI{1}{kHz}, trains substantially faster than the autoencoder baseline, and improves significantly with dataset size.
Phase-Retrieval-Based Physics-Informed Neural Networks For Acoustic Magnitude Field Reconstruction
Jan 27, 2026We propose a method for estimating the magnitude distribution of an acoustic field from spatially sparse magnitude measurements. Such a method is useful when phase measurements are unreliable or inaccessible. Physics-informed neural networks (PINNs) have shown promise for sound field estimation by incorporating constraints derived from governing partial differential equations (PDEs) into neural networks. However, they do not extend to settings where phase measurements are unavailable, as the loss function based on the governing PDE relies on phase information. To remedy this, we propose a phase-retrieval-based PINN for magnitude field estimation. By representing the magnitude and phase distributions with separate networks, the PDE loss can be computed based on the reconstructed complex amplitude. We demonstrate the effectiveness of our phase-retrieval-based PINN through experimental evaluation.
IdolSongsJp Corpus: A Multi-Singer Song Corpus in the Style of Japanese Idol Groups
Jul 02, 2025Japanese idol groups, comprising performers known as "idols," are an indispensable part of Japanese pop culture. They frequently appear in live concerts and television programs, entertaining audiences with their singing and dancing. Similar to other J-pop songs, idol group music covers a wide range of styles, with various types of chord progressions and instrumental arrangements. These tracks often feature numerous instruments and employ complex mastering techniques, resulting in high signal loudness. Additionally, most songs include a song division (utawari) structure, in which members alternate between singing solos and performing together. Hence, these songs are well-suited for benchmarking various music information processing techniques such as singer diarization, music source separation, and automatic chord estimation under challenging conditions. Focusing on these characteristics, we constructed a song corpus titled IdolSongsJp by commissioning professional composers to create 15 tracks in the style of Japanese idol groups. This corpus includes not only mastered audio tracks but also stems for music source separation, dry vocal tracks, and chord annotations. This paper provides a detailed description of the corpus, demonstrates its diversity through comparisons with real-world idol group songs, and presents its application in evaluating several music information processing techniques.
Discrete Speech Unit Extraction via Independent Component Analysis
Jan 11, 2025



Self-supervised speech models (S3Ms) have become a common tool for the speech processing community, leveraging representations for downstream tasks. Clustering S3M representations yields discrete speech units (DSUs), which serve as compact representations for speech signals. DSUs are typically obtained by k-means clustering. Using DSUs often leads to strong performance in various tasks, including automatic speech recognition (ASR). However, even with the high dimensionality and redundancy of S3M representations, preprocessing S3M representations for better clustering remains unexplored, even though it can affect the quality of DSUs. In this paper, we investigate the potential of linear preprocessing methods for extracting DSUs. We evaluate standardization, principal component analysis, whitening, and independent component analysis (ICA) on DSU-based ASR benchmarks and demonstrate their effectiveness as preprocessing for k-means. We also conduct extensive analyses of their behavior, such as orthogonality or interpretability of individual components of ICA.
DNN-based ensemble singing voice synthesis with interactions between singers
Sep 16, 2024



We propose a singing voice synthesis (SVS) method for a more unified ensemble singing voice by modeling interactions between singers. Most existing SVS methods aim to synthesize a solo voice, and do not consider interactions between singers, i.e., adjusting one's own voice to the others' voices. Since the production of ensemble voices from solo singing voices ignores the interactions, it can degrade the unity of the vocal ensemble. Therefore, we propose a SVS that reproduces the interactions. It is based on an architecture that uses musical scores of multiple voice parts, and loss functions that simulate the interactions' effect to acoustic features. Experimental results show that our methods improve the unity of the vocal ensemble.
Physics-Informed Machine Learning For Sound Field Estimation
Aug 27, 2024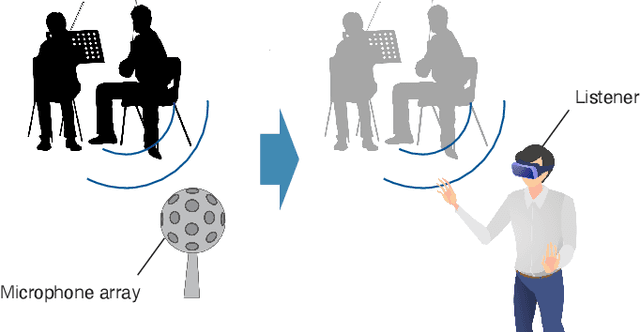
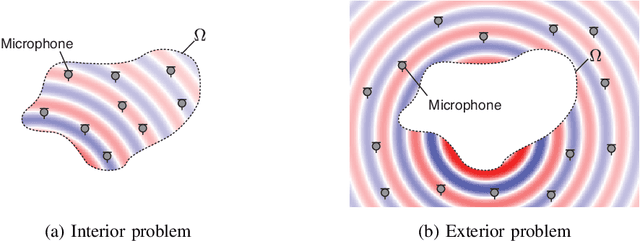
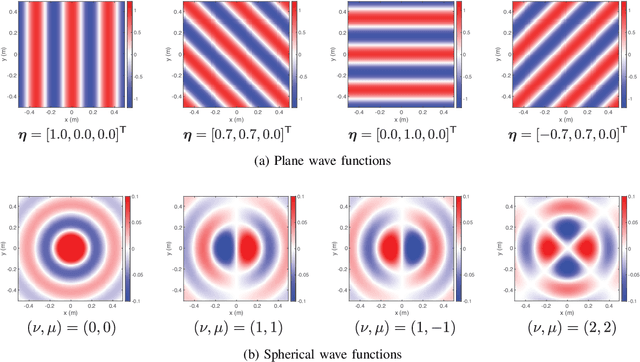
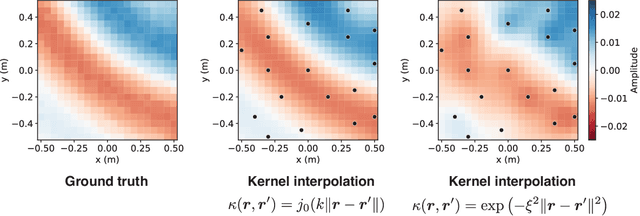
The area of study concerning the estimation of spatial sound, i.e., the distribution of a physical quantity of sound such as acoustic pressure, is called sound field estimation, which is the basis for various applied technologies related to spatial audio processing. The sound field estimation problem is formulated as a function interpolation problem in machine learning in a simplified scenario. However, high estimation performance cannot be expected by simply applying general interpolation techniques that rely only on data. The physical properties of sound fields are useful a priori information, and it is considered extremely important to incorporate them into the estimation. In this article, we introduce the fundamentals of physics-informed machine learning (PIML) for sound field estimation and overview current PIML-based sound field estimation methods.
Neural Blind Source Separation and Diarization for Distant Speech Recognition
Jun 12, 2024



This paper presents a neural method for distant speech recognition (DSR) that jointly separates and diarizes speech mixtures without supervision by isolated signals. A standard separation method for multi-talker DSR is a statistical multichannel method called guided source separation (GSS). While GSS does not require signal-level supervision, it relies on speaker diarization results to handle unknown numbers of active speakers. To overcome this limitation, we introduce and train a neural inference model in a weakly-supervised manner, employing the objective function of a statistical separation method. This training requires only multichannel mixtures and their temporal annotations of speaker activities. In contrast to GSS, the trained model can jointly separate and diarize speech mixtures without any auxiliary information. The experiments with the AMI corpus show that our method outperforms GSS with oracle diarization results regarding word error rates. The code is available online.
Self-Supervised Speech Representations are More Phonetic than Semantic
Jun 12, 2024



Self-supervised speech models (S3Ms) have become an effective backbone for speech applications. Various analyses suggest that S3Ms encode linguistic properties. In this work, we seek a more fine-grained analysis of the word-level linguistic properties encoded in S3Ms. Specifically, we curate a novel dataset of near homophone (phonetically similar) and synonym (semantically similar) word pairs and measure the similarities between S3M word representation pairs. Our study reveals that S3M representations consistently and significantly exhibit more phonetic than semantic similarity. Further, we question whether widely used intent classification datasets such as Fluent Speech Commands and Snips Smartlights are adequate for measuring semantic abilities. Our simple baseline, using only the word identity, surpasses S3M-based models. This corroborates our findings and suggests that high scores on these datasets do not necessarily guarantee the presence of semantic content.
Real-time Speech Extraction Using Spatially Regularized Independent Low-rank Matrix Analysis and Rank-constrained Spatial Covariance Matrix Estimation
Mar 19, 2024


Real-time speech extraction is an important challenge with various applications such as speech recognition in a human-like avatar/robot. In this paper, we propose the real-time extension of a speech extraction method based on independent low-rank matrix analysis (ILRMA) and rank-constrained spatial covariance matrix estimation (RCSCME). The RCSCME-based method is a multichannel blind speech extraction method that demonstrates superior speech extraction performance in diffuse noise environments. To improve the performance, we introduce spatial regularization into the ILRMA part of the RCSCME-based speech extraction and design two regularizers. Speech extraction experiments demonstrated that the proposed methods can function in real time and the designed regularizers improve the speech extraction performance.
Sampling-Frequency-Independent Universal Sound Separation
Sep 22, 2023



This paper proposes a universal sound separation (USS) method capable of handling untrained sampling frequencies (SFs). The USS aims at separating arbitrary sources of different types and can be the key technique to realize a source separator that can be universally used as a preprocessor for any downstream tasks. To realize a universal source separator, there are two essential properties: universalities with respect to source types and recording conditions. The former property has been studied in the USS literature, which has greatly increased the number of source types that can be handled by a single neural network. However, the latter property (e.g., SF) has received less attention despite its necessity. Since the SF varies widely depending on the downstream tasks, the universal source separator must handle a wide variety of SFs. In this paper, to encompass the two properties, we propose an SF-independent (SFI) extension of a computationally efficient USS network, SuDoRM-RF. The proposed network uses our previously proposed SFI convolutional layers, which can handle various SFs by generating convolutional kernels in accordance with an input SF. Experiments show that signal resampling can degrade the USS performance and the proposed method works more consistently than signal-resampling-based methods for various SFs.