 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Token Spaces under Generator Shift in AI-Generated Music Detection
Jun 07, 2026AI-generated music detectors can appear robust on standard benchmark splits, yet their deployments require transfer to generator sources absent during training. We study this problem with source-restricted evaluation on \textsc{MoM-open}, an open reconstruction of MoM-CLAM that replaces the non-redistributable real corpus with FMA and MTG-Jamendo while preserving the fake-generator protocol. To isolate the role of representation, we introduce \textsc{CoMoE}, a compact fixed classifier for comparing heterogeneous audio token spaces while keeping the downstream architecture and training recipe unchanged. Experiments show that standard and real-source-restricted splits are nearly saturated, whereas fake-source restriction exposes large differences between token spaces: X-Codec tokens are strongest when training on Udio alone, while MERT-derived tokens are stronger when training on Suno-v3.5 alone. These results suggest that codec-style discrete token spaces should be treated as a primary experimental axis under generator shift in AI-generated music detection. Our code and data are available at https://github.com/MAAP-LAB/CoMoE.
AnimeScore: A Preference-Based Dataset and Framework for Evaluating Anime-Like Speech Style
Mar 12, 2026Evaluating 'anime-like' voices currently relies on costly subjective judgments, yet no standardized objective metric exists. A key challenge is that anime-likeness, unlike naturalness, lacks a shared absolute scale, making conventional Mean Opinion Score (MOS) protocols unreliable. To address this gap, we propose AnimeScore, a preference-based framework for automatic anime-likeness evaluation via pairwise ranking. We collect 15,000 pairwise judgments from 187 evaluators with free-form descriptions, and acoustic analysis reveals that perceived anime-likeness is driven by controlled resonance shaping, prosodic continuity, and deliberate articulation rather than simple heuristics such as high pitch. We show that handcrafted acoustic features reach a 69.3% AUC ceiling, while SSL-based ranking models achieve up to 90.8% AUC, providing a practical metric that can also serve as a reward signal for preference-based optimization of generative speech models.
Analytic Study of Text-Free Speech Synthesis for Raw Audio using a Self-Supervised Learning Model
Dec 04, 2024



We examine the text-free speech representations of raw audio obtained from a self-supervised learning (SSL) model by analyzing the synthesized speech using the SSL representations instead of conventional text representations. Since raw audio does not have paired speech representations as transcribed texts do, obtaining speech representations from unpaired speech is crucial for augmenting available datasets for speech synthesis. Specifically, the proposed speech synthesis is conducted using discrete symbol representations from the SSL model in comparison with text representations, and analytical examinations of the synthesized speech have been carried out. The results empirically show that using text representations is advantageous for preserving semantic information, while using discrete symbol representations is superior for preserving acoustic content, including prosodic and intonational information.
Analyzing The Language of Visual Tokens
Nov 07, 2024



With the introduction of transformer-based models for vision and language tasks, such as LLaVA and Chameleon, there has been renewed interest in the discrete tokenized representation of images. These models often treat image patches as discrete tokens, analogous to words in natural language, learning joint alignments between visual and human languages. However, little is known about the statistical behavior of these visual languages - whether they follow similar frequency distributions, grammatical structures, or topologies as natural languages. In this paper, we take a natural-language-centric approach to analyzing discrete visual languages and uncover striking similarities and fundamental differences. We demonstrate that, although visual languages adhere to Zipfian distributions, higher token innovation drives greater entropy and lower compression, with tokens predominantly representing object parts, indicating intermediate granularity. We also show that visual languages lack cohesive grammatical structures, leading to higher perplexity and weaker hierarchical organization compared to natural languages. Finally, we demonstrate that, while vision models align more closely with natural languages than other models, this alignment remains significantly weaker than the cohesion found within natural languages. Through these experiments, we demonstrate how understanding the statistical properties of discrete visual languages can inform the design of more effective computer vision models.
A Pilot Study of GSLM-based Simulation of Foreign Accentuation Only Using Native Speech Corpora
Jul 16, 2024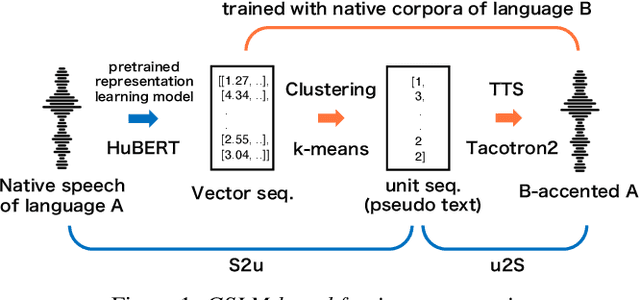

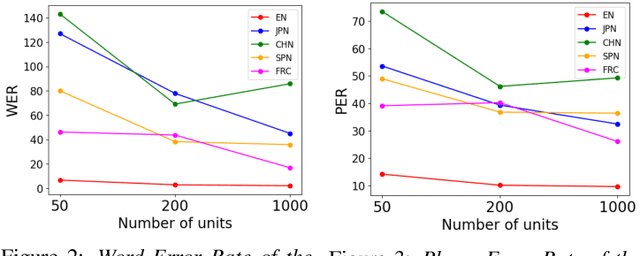

We propose a method of simulating the human process of foreign accentuation using Generative Spoken Language Model (GSLM) only with native speech corpora. When one listens to spoken words of a foreign language and repeats them, the repeated speech is often with the accent of that listener's L1. This is said to be because the spoken words are mentally represented as a sequence of phonological units of the L1, and those units are used for oral reproduction. We simulate this process by inputting speech of language A into GSLM of language B to add B's accent onto the input speech. The process of running ASR of the L1 for foreign input speech and giving the ASR result to TTS of the L1 can be viewed as a naive implementation of this approach. The results of our experiments show that the synthesized accent of the output speech is highly natural, compared to real samples of A generated by speakers whose L1 is B, and that the degree of accentuation is controllable.
Do learned speech symbols follow Zipf's law?
Sep 18, 2023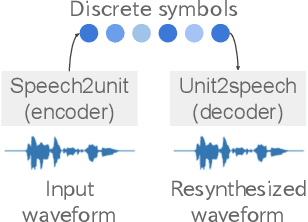
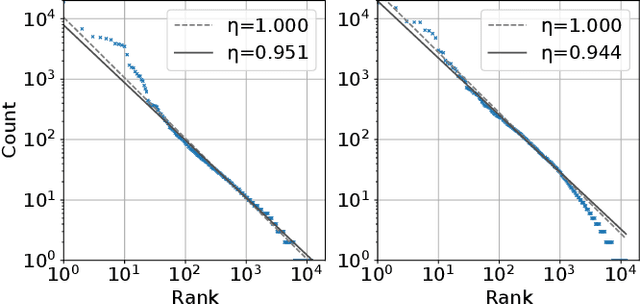
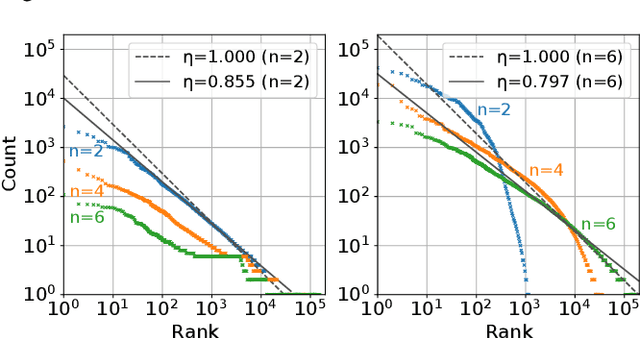
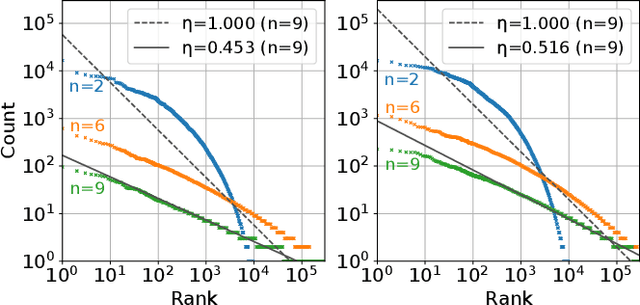
In this study, we investigate whether speech symbols, learned through deep learning, follow Zipf's law, akin to natural language symbols. Zipf's law is an empirical law that delineates the frequency distribution of words, forming fundamentals for statistical analysis in natural language processing. Natural language symbols, which are invented by humans to symbolize speech content, are recognized to comply with this law. On the other hand, recent breakthroughs in spoken language processing have given rise to the development of learned speech symbols; these are data-driven symbolizations of speech content. Our objective is to ascertain whether these data-driven speech symbols follow Zipf's law, as the same as natural language symbols. Through our investigation, we aim to forge new ways for the statistical analysis of spoken language processing.
How Generative Spoken Language Modeling Encodes Noisy Speech: Investigation from Phonetics to Syntactics
Jun 01, 2023



We examine the speech modeling potential of generative spoken language modeling (GSLM), which involves using learned symbols derived from data rather than phonemes for speech analysis and synthesis. Since GSLM facilitates textless spoken language processing, exploring its effectiveness is critical for paving the way for novel paradigms in spoken-language processing. This paper presents the findings of GSLM's encoding and decoding effectiveness at the spoken-language and speech levels. Through speech resynthesis experiments, we revealed that resynthesis errors occur at the levels ranging from phonology to syntactics and GSLM frequently resynthesizes natural but content-altered speech.