 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pilot Study of GSLM-based Simulation of Foreign Accentuation Only Using Native Speech Corpora
Paper and Code
Jul 16, 2024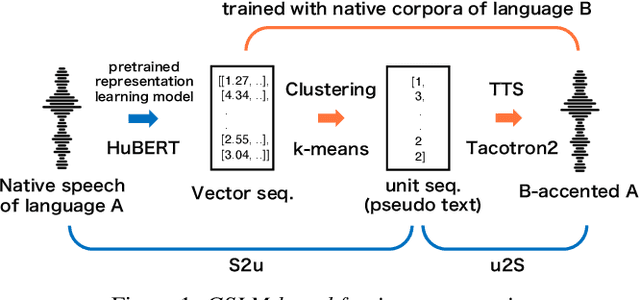

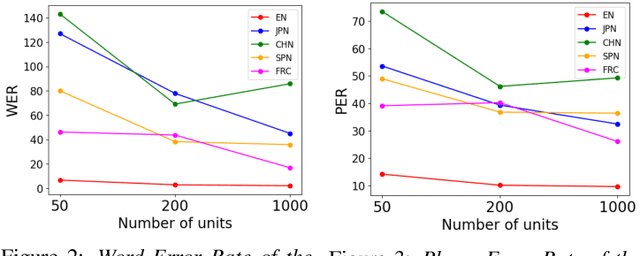

We propose a method of simulating the human process of foreign accentuation using Generative Spoken Language Model (GSLM) only with native speech corpora. When one listens to spoken words of a foreign language and repeats them, the repeated speech is often with the accent of that listener's L1. This is said to be because the spoken words are mentally represented as a sequence of phonological units of the L1, and those units are used for oral reproduction. We simulate this process by inputting speech of language A into GSLM of language B to add B's accent onto the input speech. The process of running ASR of the L1 for foreign input speech and giving the ASR result to TTS of the L1 can be viewed as a naive implementation of this approach. The results of our experiments show that the synthesized accent of the output speech is highly natural, compared to real samples of A generated by speakers whose L1 is B, and that the degree of accentuation is controllable.