 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo learned speech symbols follow Zipf's law?
Sep 18, 2023
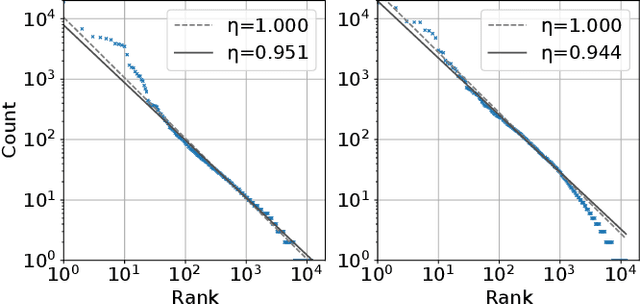
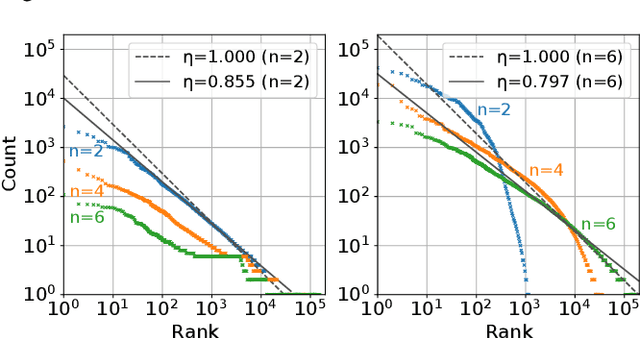
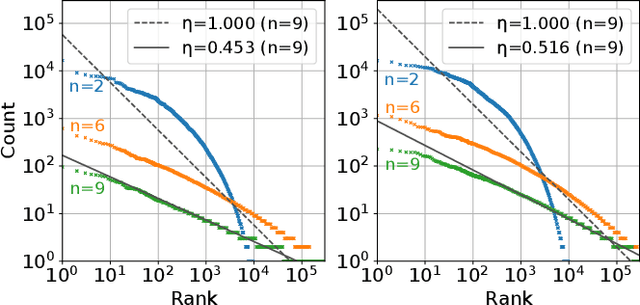
In this study, we investigate whether speech symbols, learned through deep learning, follow Zipf's law, akin to natural language symbols. Zipf's law is an empirical law that delineates the frequency distribution of words, forming fundamentals for statistical analysis in natural language processing. Natural language symbols, which are invented by humans to symbolize speech content, are recognized to comply with this law. On the other hand, recent breakthroughs in spoken language processing have given rise to the development of learned speech symbols; these are data-driven symbolizations of speech content. Our objective is to ascertain whether these data-driven speech symbols follow Zipf's law, as the same as natural language symbols. Through our investigation, we aim to forge new ways for the statistical analysis of spoken language processing.