 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
Jan 23, 2026Modern Vision-Language Models (VLMs) remain poorly characterized in multi-step visual interactions, particularly in how they integrate perception, memory, and action over long horizons. We introduce VisGym, a gymnasium of 17 environments for evaluating and training VLMs. The suite spans symbolic puzzles, real-image understanding, navigation, and manipulation, and provides flexible controls over difficulty, input representation, planning horizon, and feedback. We also provide multi-step solvers that generate structured demonstrations, enabling supervised finetuning. Our evaluations show that all frontier models struggle in interactive settings, achieving low success rates in both the easy (46.6%) and hard (26.0%) configurations. Our experiments reveal notable limitations: models struggle to effectively leverage long context, performing worse with an unbounded history than with truncated windows. Furthermore, we find that several text-based symbolic tasks become substantially harder once rendered visually. However, explicit goal observations, textual feedback, and exploratory demonstrations in partially observable or unknown-dynamics settings for supervised finetuning yield consistent gains, highlighting concrete failure modes and pathways for improving multi-step visual decision-making. Code, data, and models can be found at: https://visgym.github.io/.
Puzzled by Puzzles: When Vision-Language Models Can't Take a Hint
May 29, 2025Rebus puzzles, visual riddles that encode language through imagery, spatial arrangement, and symbolic substitution, pose a unique challenge to current vision-language models (VLMs). Unlike traditional image captioning or question answering tasks, rebus solving requires multi-modal abstraction, symbolic reasoning, and a grasp of cultural, phonetic and linguistic puns. In this paper, we investigate the capacity of contemporary VLMs to interpret and solve rebus puzzles by constructing a hand-generated and annotated benchmark of diverse English-language rebus puzzles, ranging from simple pictographic substitutions to spatially-dependent cues ("head" over "heels"). We analyze how different VLMs perform, and our findings reveal that while VLMs exhibit some surprising capabilities in decoding simple visual clues, they struggle significantly with tasks requiring abstract reasoning, lateral thinking, and understanding visual metaphors.
REOrdering Patches Improves Vision Models
May 29, 2025Sequence models such as transformers require inputs to be represented as one-dimensional sequences. In vision, this typically involves flattening images using a fixed row-major (raster-scan) order. While full self-attention is permutation-equivariant, modern long-sequence transformers increasingly rely on architectural approximations that break this invariance and introduce sensitivity to patch ordering. We show that patch order significantly affects model performance in such settings, with simple alternatives like column-major or Hilbert curves yielding notable accuracy shifts. Motivated by this, we propose REOrder, a two-stage framework for discovering task-optimal patch orderings. First, we derive an information-theoretic prior by evaluating the compressibility of various patch sequences. Then, we learn a policy over permutations by optimizing a Plackett-Luce policy using REINFORCE. This approach enables efficient learning in a combinatorial permutation space. REOrder improves top-1 accuracy over row-major ordering on ImageNet-1K by up to 3.01% and Functional Map of the World by 13.35%.
LISAT: Language-Instructed Segmentation Assistant for Satellite Imagery
May 05, 2025Segmentation models can recognize a pre-defined set of objects in images. However, models that can reason over complex user queries that implicitly refer to multiple objects of interest are still in their infancy. Recent advances in reasoning segmentation--generating segmentation masks from complex, implicit query text--demonstrate that vision-language models can operate across an open domain and produce reasonable outputs. However, our experiments show that such models struggle with complex remote-sensing imagery. In this work, we introduce LISAt, a vision-language model designed to describe complex remote-sensing scenes, answer questions about them, and segment objects of interest. We trained LISAt on a new curated geospatial reasoning-segmentation dataset, GRES, with 27,615 annotations over 9,205 images, and a multimodal pretraining dataset, PreGRES, containing over 1 million question-answer pairs. LISAt outperforms existing geospatial foundation models such as RS-GPT4V by over 10.04 % (BLEU-4) on remote-sensing description tasks, and surpasses state-of-the-art open-domain models on reasoning segmentation tasks by 143.36 % (gIoU). Our model, datasets, and code are available at https://lisat-bair.github.io/LISAt/
Generate, but Verify: Reducing Hallucination in Vision-Language Models with Retrospective Resampling
Apr 17, 2025Vision-Language Models (VLMs) excel at visual understanding but often suffer from visual hallucinations, where they generate descriptions of nonexistent objects, actions, or concepts, posing significant risks in safety-critical applications. Existing hallucination mitigation methods typically follow one of two paradigms: generation adjustment, which modifies decoding behavior to align text with visual inputs, and post-hoc verification, where external models assess and correct outputs. While effective, generation adjustment methods often rely on heuristics and lack correction mechanisms, while post-hoc verification is complicated, typically requiring multiple models and tending to reject outputs rather than refine them. In this work, we introduce REVERSE, a unified framework that integrates hallucination-aware training with on-the-fly self-verification. By leveraging a new hallucination-verification dataset containing over 1.3M semi-synthetic samples, along with a novel inference-time retrospective resampling technique, our approach enables VLMs to both detect hallucinations during generation and dynamically revise those hallucinations. Our evaluations show that REVERSE achieves state-of-the-art hallucination reduction, outperforming the best existing methods by up to 12% on CHAIR-MSCOCO and 28% on HaloQuest. Our dataset, model, and code are available at: https://reverse-vlm.github.io.
Higher-Order Binding of Language Model Virtual Personas: a Study on Approximating Political Partisan Misperceptions
Apr 16, 2025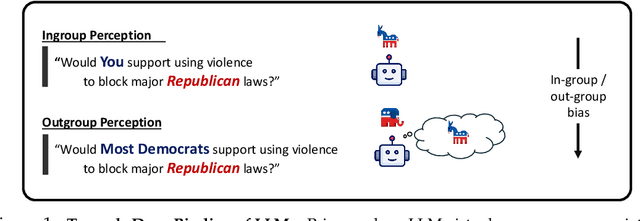
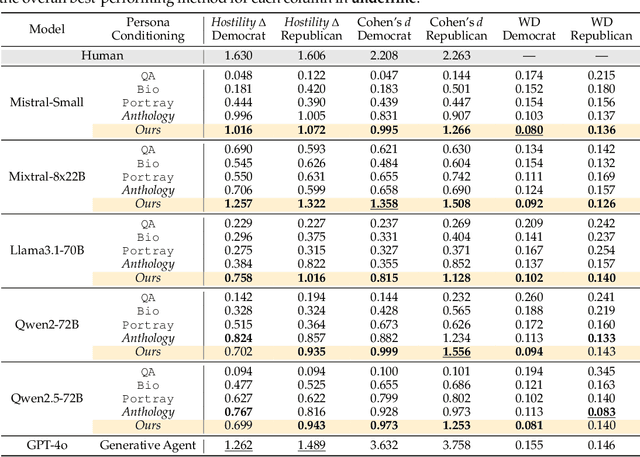

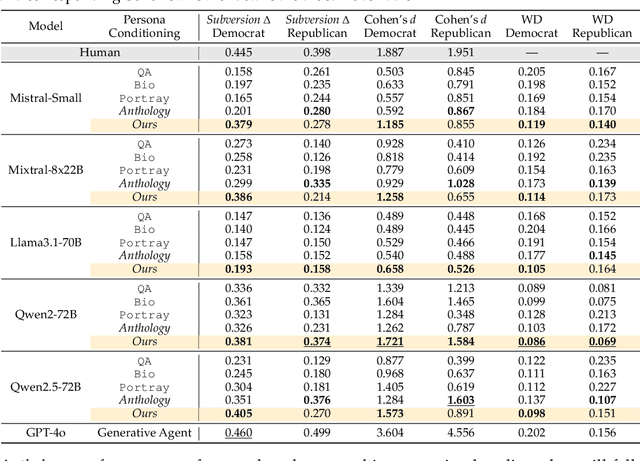
Large language models (LLMs) are increasingly capable of simulating human behavior, offering cost-effective ways to estimate user responses during the early phases of survey design. While previous studies have examined whether models can reflect individual opinions or attitudes, we argue that a \emph{higher-order} binding of virtual personas requires successfully approximating not only the opinions of a user as an identified member of a group, but also the nuanced ways in which that user perceives and evaluates those outside the group. In particular, faithfully simulating how humans perceive different social groups is critical for applying LLMs to various political science studies, including timely topics on polarization dynamics, inter-group conflict, and democratic backsliding. To this end, we propose a novel methodology for constructing virtual personas with synthetic user ``backstories" generated as extended, multi-turn interview transcripts. Our generated backstories are longer, rich in detail, and consistent in authentically describing a singular individual, compared to previous methods. We show that virtual personas conditioned on our backstories closely replicate human response distributions (up to an 87\% improvement as measured by Wasserstein Distance) and produce effect sizes that closely match those observed in the original studies. Altogether, our work extends the applicability of LLMs beyond estimating individual self-opinions, enabling their use in a broader range of human studies.
TULIP: Towards Unified Language-Image Pretraining
Mar 19, 2025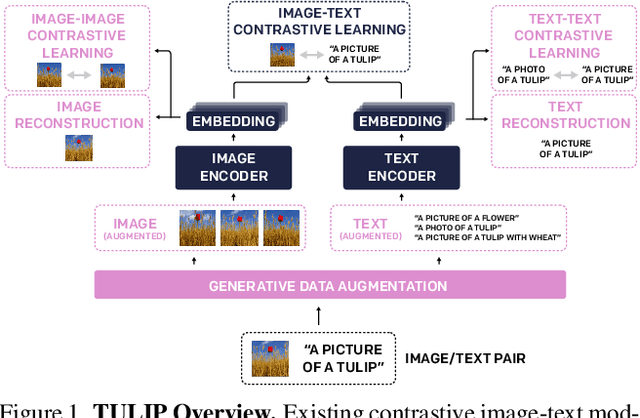
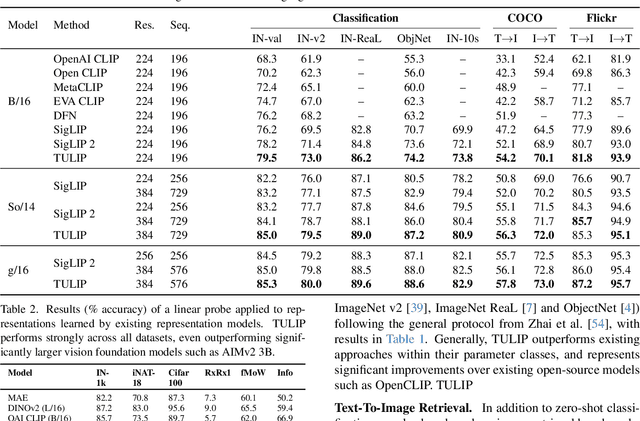
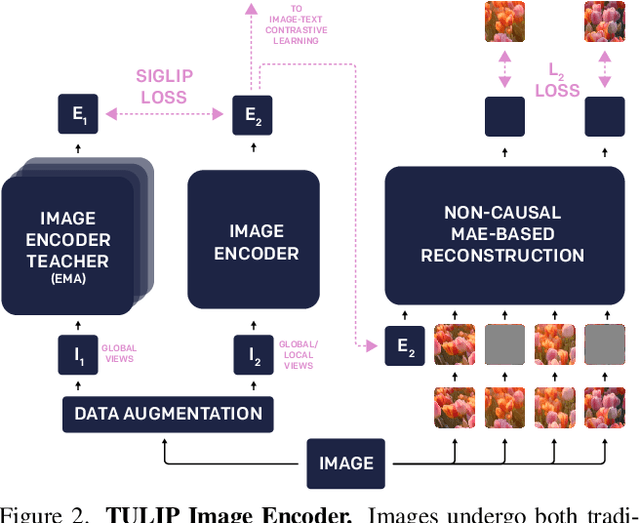
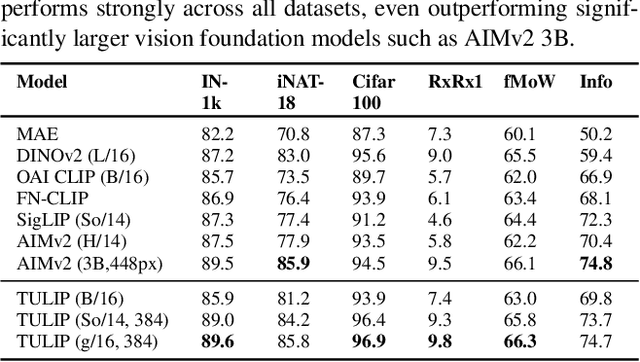
Despite the recent success of image-text contrastive models like CLIP and SigLIP, these models often struggle with vision-centric tasks that demand high-fidelity image understanding, such as counting, depth estimation, and fine-grained object recognition. These models, by performing language alignment, tend to prioritize high-level semantics over visual understanding, weakening their image understanding. On the other hand, vision-focused models are great at processing visual information but struggle to understand language, limiting their flexibility for language-driven tasks. In this work, we introduce TULIP, an open-source, drop-in replacement for existing CLIP-like models. Our method leverages generative data augmentation, enhanced image-image and text-text contrastive learning, and image/text reconstruction regularization to learn fine-grained visual features while preserving global semantic alignment. Our approach, scaling to over 1B parameters, outperforms existing state-of-the-art (SOTA) models across multiple benchmarks, establishing a new SOTA zero-shot performance on ImageNet-1K, delivering up to a $2\times$ enhancement over SigLIP on RxRx1 in linear probing for few-shot classification, and improving vision-language models, achieving over $3\times$ higher scores than SigLIP on MMVP. Our code/checkpoints are available at https://tulip-berkeley.github.io
Enough Coin Flips Can Make LLMs Act Bayesian
Mar 06, 2025Large language models (LLMs) exhibit the ability to generalize given few-shot examples in their input prompt, an emergent capability known as in-context learning (ICL). We investigate whether LLMs utilize ICL to perform structured reasoning in ways that are consistent with a Bayesian framework or rely on pattern matching. Using a controlled setting of biased coin flips, we find that: (1) LLMs often possess biased priors, causing initial divergence in zero-shot settings, (2) in-context evidence outweighs explicit bias instructions, (3) LLMs broadly follow Bayesian posterior updates, with deviations primarily due to miscalibrated priors rather than flawed updates, and (4) attention magnitude has negligible effect on Bayesian inference. With sufficient demonstrations of biased coin flips via ICL, LLMs update their priors in a Bayesian manner.
Analyzing The Language of Visual Tokens
Nov 07, 2024



With the introduction of transformer-based models for vision and language tasks, such as LLaVA and Chameleon, there has been renewed interest in the discrete tokenized representation of images. These models often treat image patches as discrete tokens, analogous to words in natural language, learning joint alignments between visual and human languages. However, little is known about the statistical behavior of these visual languages - whether they follow similar frequency distributions, grammatical structures, or topologies as natural languages. In this paper, we take a natural-language-centric approach to analyzing discrete visual languages and uncover striking similarities and fundamental differences. We demonstrate that, although visual languages adhere to Zipfian distributions, higher token innovation drives greater entropy and lower compression, with tokens predominantly representing object parts, indicating intermediate granularity. We also show that visual languages lack cohesive grammatical structures, leading to higher perplexity and weaker hierarchical organization compared to natural languages. Finally, we demonstrate that, while vision models align more closely with natural languages than other models, this alignment remains significantly weaker than the cohesion found within natural languages. Through these experiments, we demonstrate how understanding the statistical properties of discrete visual languages can inform the design of more effective computer vision models.
An Efficient Self-Learning Framework For Interactive Spoken Dialog Systems
Sep 16, 2024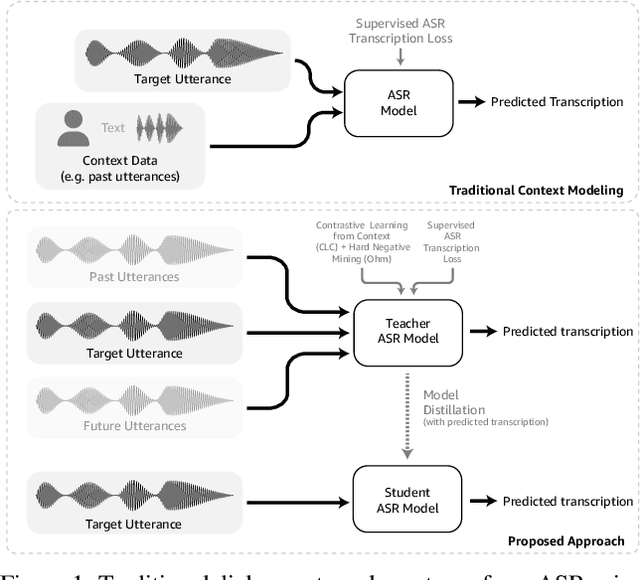

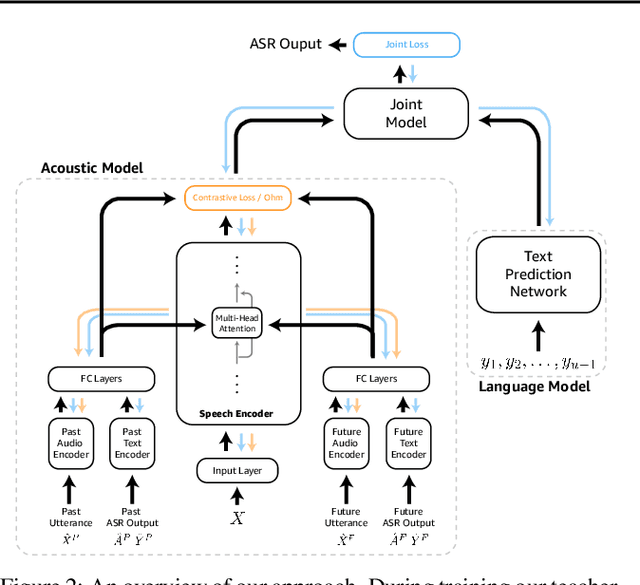
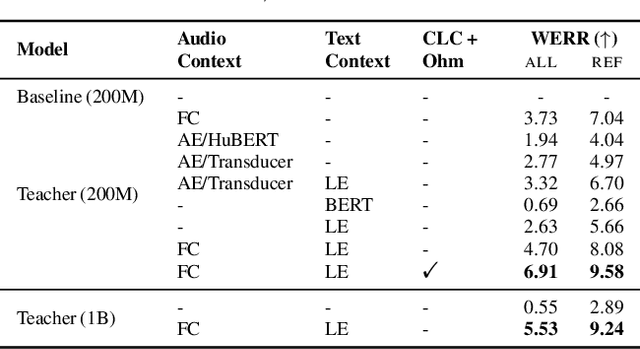
Dialog systems, such as voice assistants, are expected to engage with users in complex, evolving conversations. Unfortunately, traditional automatic speech recognition (ASR) systems deployed in such applications are usually trained to recognize each turn independently and lack the ability to adapt to the conversational context or incorporate user feedback. In this work, we introduce a general framework for ASR in dialog systems that can go beyond learning from single-turn utterances and learn over time how to adapt to both explicit supervision and implicit user feedback present in multi-turn conversations. We accomplish that by leveraging advances in student-teacher learning and context-aware dialog processing, and designing contrastive self-supervision approaches with Ohm, a new online hard-negative mining approach. We show that leveraging our new framework compared to traditional training leads to relative WER reductions of close to 10% in real-world dialog systems, and up to 26% on public synthetic data.