 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Self-Learning Framework For Interactive Spoken Dialog Systems
Sep 16, 2024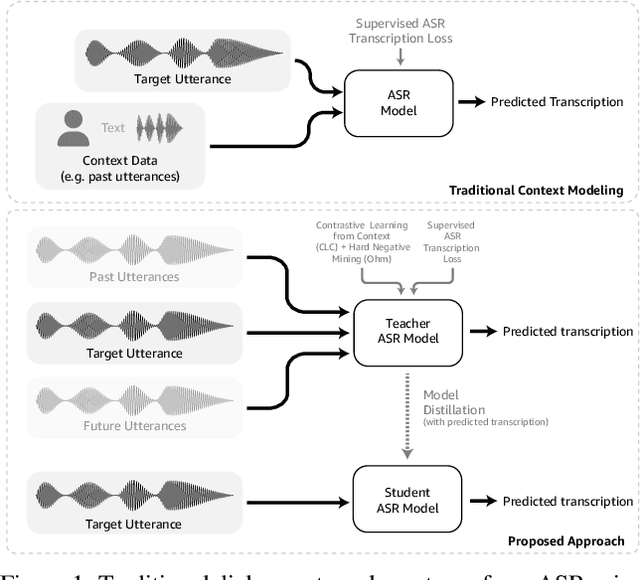

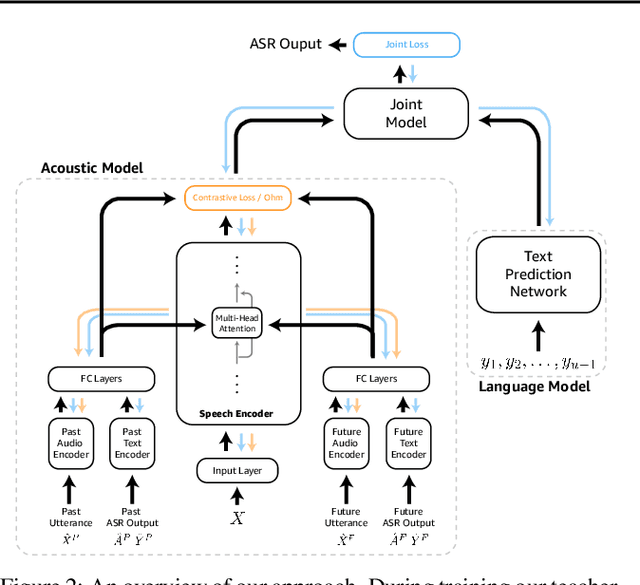
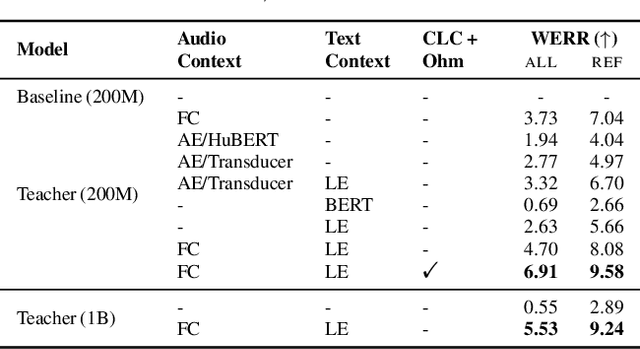
Dialog systems, such as voice assistants, are expected to engage with users in complex, evolving conversations. Unfortunately, traditional automatic speech recognition (ASR) systems deployed in such applications are usually trained to recognize each turn independently and lack the ability to adapt to the conversational context or incorporate user feedback. In this work, we introduce a general framework for ASR in dialog systems that can go beyond learning from single-turn utterances and learn over time how to adapt to both explicit supervision and implicit user feedback present in multi-turn conversations. We accomplish that by leveraging advances in student-teacher learning and context-aware dialog processing, and designing contrastive self-supervision approaches with Ohm, a new online hard-negative mining approach. We show that leveraging our new framework compared to traditional training leads to relative WER reductions of close to 10% in real-world dialog systems, and up to 26% on public synthetic data.
Task Oriented Dialogue as a Catalyst for Self-Supervised Automatic Speech Recognition
Jan 04, 2024



While word error rates of automatic speech recognition (ASR) systems have consistently fallen, natural language understanding (NLU) applications built on top of ASR systems still attribute significant numbers of failures to low-quality speech recognition results. Existing assistant systems collect large numbers of these unsuccessful interactions, but these systems usually fail to learn from these interactions, even in an offline fashion. In this work, we introduce CLC: Contrastive Learning for Conversations, a family of methods for contrastive fine-tuning of models in a self-supervised fashion, making use of easily detectable artifacts in unsuccessful conversations with assistants. We demonstrate that our CLC family of approaches can improve the performance of ASR models on OD3, a new public large-scale semi-synthetic meta-dataset of audio task-oriented dialogues, by up to 19.2%. These gains transfer to real-world systems as well, where we show that CLC can help to improve performance by up to 6.7% over baselines. We make OD3 publicly available at https://github.com/amazon-science/amazon-od3 .
Knowledge Distillation and Data Selection for Semi-Supervised Learning in CTC Acoustic Models
Aug 10, 2020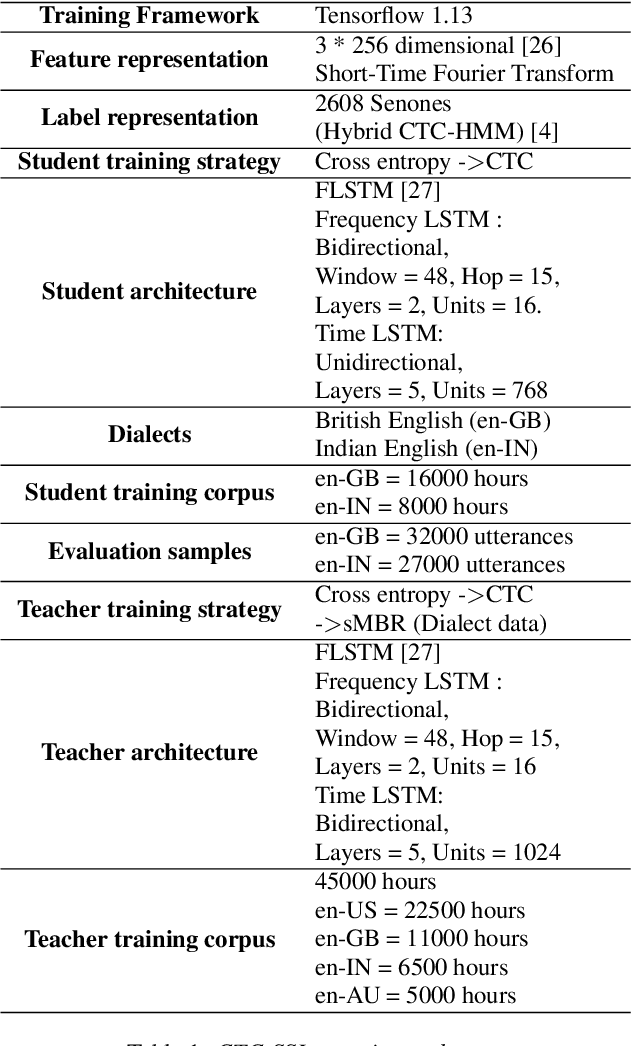
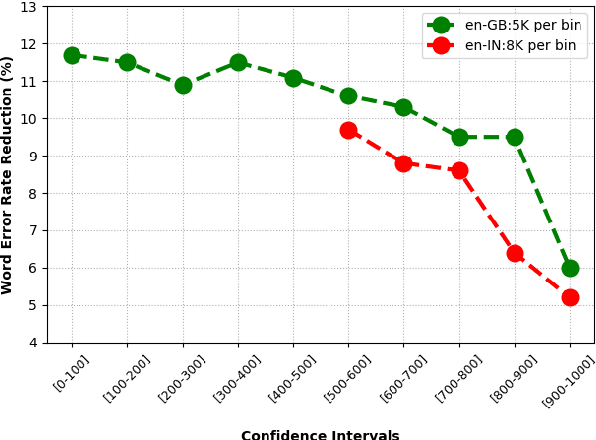
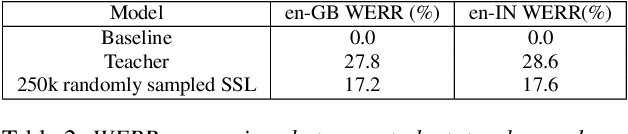
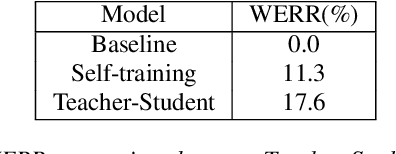
Semi-supervised learning (SSL) is an active area of research which aims to utilize unlabelled data in order to improve the accuracy of speech recognition systems. The current study proposes a methodology for integration of two key ideas: 1) SSL using connectionist temporal classification (CTC) objective and teacher-student based learning 2) Designing effective data-selection mechanisms for leveraging unlabelled data to boost performance of student models. Our aim is to establish the importance of good criteria in selecting samples from a large pool of unlabelled data based on attributes like confidence measure, speaker and content variability. The question we try to answer is: Is it possible to design a data selection mechanism which reduces dependence on a large set of randomly selected unlabelled samples without compromising on Word Error Rate (WER)? We perform empirical investigations of different data selection methods to answer this question and quantify the effect of different sampling strategies. On a semi-supervised ASR setting with 40000 hours of carefully selected unlabelled data, our CTC-SSL approach gives 17% relative WER improvement over a baseline CTC system trained with labelled data. It also achieves on-par performance with CTC-SSL system trained on order of magnitude larger unlabeled data based on random sampling.