 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Self-Learning Framework For Interactive Spoken Dialog Systems
Sep 16, 2024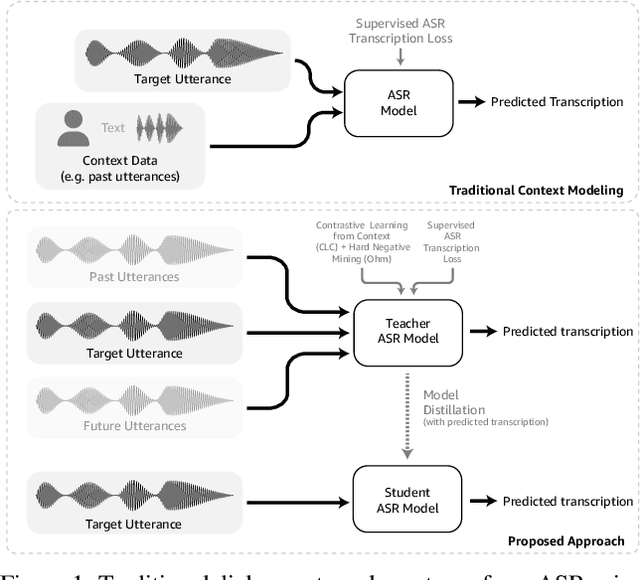

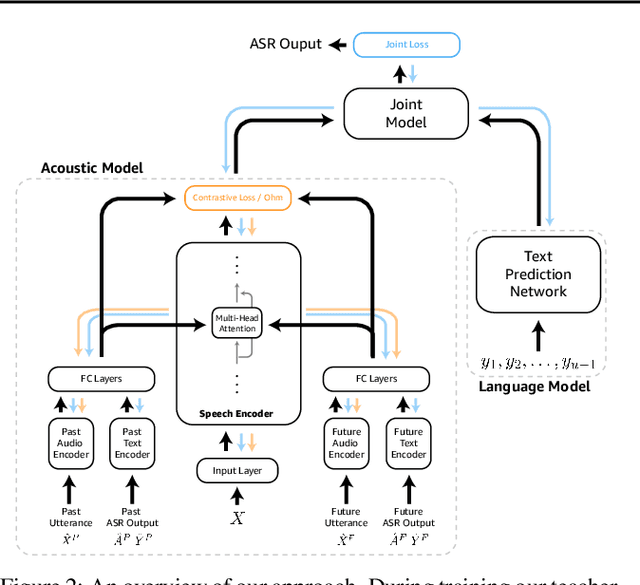
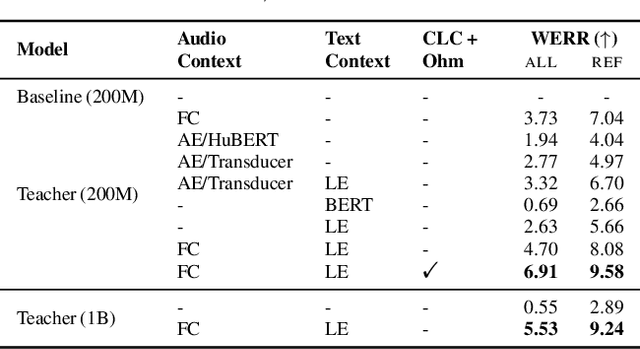
Dialog systems, such as voice assistants, are expected to engage with users in complex, evolving conversations. Unfortunately, traditional automatic speech recognition (ASR) systems deployed in such applications are usually trained to recognize each turn independently and lack the ability to adapt to the conversational context or incorporate user feedback. In this work, we introduce a general framework for ASR in dialog systems that can go beyond learning from single-turn utterances and learn over time how to adapt to both explicit supervision and implicit user feedback present in multi-turn conversations. We accomplish that by leveraging advances in student-teacher learning and context-aware dialog processing, and designing contrastive self-supervision approaches with Ohm, a new online hard-negative mining approach. We show that leveraging our new framework compared to traditional training leads to relative WER reductions of close to 10% in real-world dialog systems, and up to 26% on public synthetic data.
Multi-Stage Multi-Modal Pre-Training for Automatic Speech Recognition
Mar 28, 2024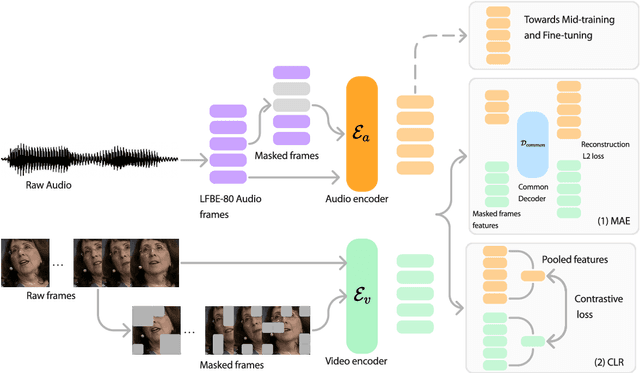
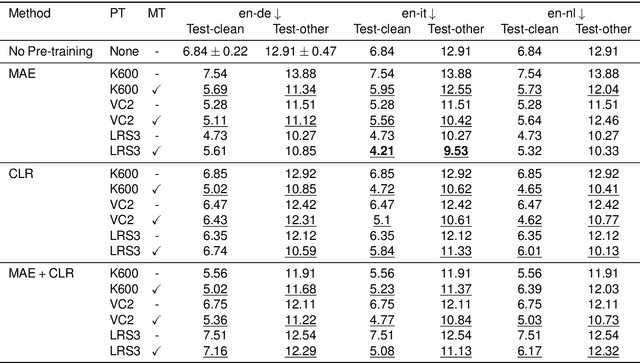
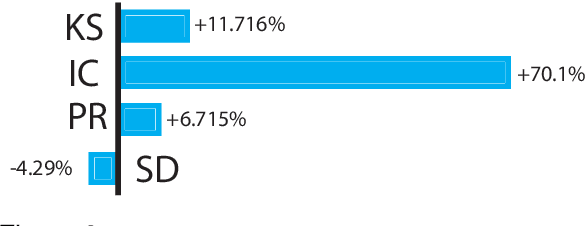
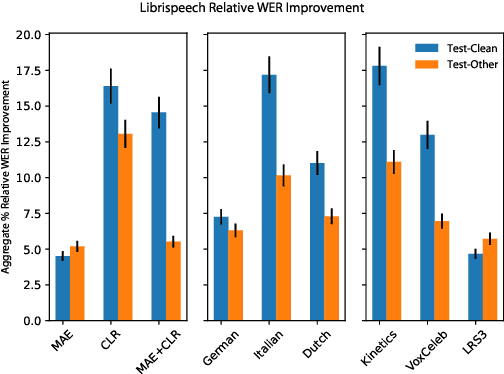
Recent advances in machine learning have demonstrated that multi-modal pre-training can improve automatic speech recognition (ASR) performance compared to randomly initialized models, even when models are fine-tuned on uni-modal tasks. Existing multi-modal pre-training methods for the ASR task have primarily focused on single-stage pre-training where a single unsupervised task is used for pre-training followed by fine-tuning on the downstream task. In this work, we introduce a novel method combining multi-modal and multi-task unsupervised pre-training with a translation-based supervised mid-training approach. We empirically demonstrate that such a multi-stage approach leads to relative word error rate (WER) improvements of up to 38.45% over baselines on both Librispeech and SUPERB. Additionally, we share several important findings for choosing pre-training methods and datasets.
Paralinguistics-Enhanced Large Language Modeling of Spoken Dialogue
Jan 17, 2024Large Language Models (LLMs) have demonstrated superior abilities in tasks such as chatting, reasoning, and question-answering. However, standard LLMs may ignore crucial paralinguistic information, such as sentiment, emotion, and speaking style, which are essential for achieving natural, human-like spoken conversation, especially when such information is conveyed by acoustic cues. We therefore propose Paralinguistics-enhanced Generative Pretrained Transformer (ParalinGPT), an LLM that utilizes text and speech modalities to better model the linguistic content and paralinguistic attributes of spoken dialogue. The model takes the conversational context of text, speech embeddings, and paralinguistic attributes as input prompts within a serialized multitasking multimodal framework. Specifically, our framework serializes tasks in the order of current paralinguistic attribute prediction, response paralinguistic attribute prediction, and response text generation with autoregressive conditioning. We utilize the Switchboard-1 corpus, including its sentiment labels as the paralinguistic attribute, as our spoken dialogue dataset. Experimental results indicate the proposed serialized multitasking method outperforms typical sequence classification techniques on current and response sentiment classification. Furthermore, leveraging conversational context and speech embeddings significantly improves both response text generation and sentiment prediction. Our proposed framework achieves relative improvements of 6.7%, 12.0%, and 3.5% in current sentiment accuracy, response sentiment accuracy, and response text BLEU score, respectively.
Towards ASR Robust Spoken Language Understanding Through In-Context Learning With Word Confusion Networks
Jan 05, 2024



In the realm of spoken language understanding (SLU), numerous natural language understanding (NLU) methodologies have been adapted by supplying large language models (LLMs) with transcribed speech instead of conventional written text. In real-world scenarios, prior to input into an LLM, an automated speech recognition (ASR) system generates an output transcript hypothesis, where inherent errors can degrade subsequent SLU tasks. Here we introduce a method that utilizes the ASR system's lattice output instead of relying solely on the top hypothesis, aiming to encapsulate speech ambiguities and enhance SLU outcomes. Our in-context learning experiments, covering spoken question answering and intent classification, underline the LLM's resilience to noisy speech transcripts with the help of word confusion networks from lattices, bridging the SLU performance gap between using the top ASR hypothesis and an oracle upper bound. Additionally, we delve into the LLM's robustness to varying ASR performance conditions and scrutinize the aspects of in-context learning which prove the most influential.
Task Oriented Dialogue as a Catalyst for Self-Supervised Automatic Speech Recognition
Jan 04, 2024



While word error rates of automatic speech recognition (ASR) systems have consistently fallen, natural language understanding (NLU) applications built on top of ASR systems still attribute significant numbers of failures to low-quality speech recognition results. Existing assistant systems collect large numbers of these unsuccessful interactions, but these systems usually fail to learn from these interactions, even in an offline fashion. In this work, we introduce CLC: Contrastive Learning for Conversations, a family of methods for contrastive fine-tuning of models in a self-supervised fashion, making use of easily detectable artifacts in unsuccessful conversations with assistants. We demonstrate that our CLC family of approaches can improve the performance of ASR models on OD3, a new public large-scale semi-synthetic meta-dataset of audio task-oriented dialogues, by up to 19.2%. These gains transfer to real-world systems as well, where we show that CLC can help to improve performance by up to 6.7% over baselines. We make OD3 publicly available at https://github.com/amazon-science/amazon-od3 .
Multimodal Attention Merging for Improved Speech Recognition and Audio Event Classification
Dec 22, 2023



Training large foundation models using self-supervised objectives on unlabeled data, followed by fine-tuning on downstream tasks, has emerged as a standard procedure. Unfortunately, the efficacy of this approach is often constrained by both limited fine-tuning compute and scarcity in labeled downstream data. We introduce Multimodal Attention Merging (MAM), an attempt that facilitates direct knowledge transfer from attention matrices of models rooted in high resource modalities, text and images, to those in resource-constrained domains, speech and audio, employing a zero-shot paradigm. MAM reduces the relative Word Error Rate (WER) of an Automatic Speech Recognition (ASR) model by up to 6.70%, and relative classification error of an Audio Event Classification (AEC) model by 10.63%. In cases where some data/compute is available, we present Learnable-MAM, a data-driven approach to merging attention matrices, resulting in a further 2.90% relative reduction in WER for ASR and 18.42% relative reduction in AEC compared to fine-tuning.
JAB: Joint Adversarial Prompting and Belief Augmentation
Nov 16, 2023



With the recent surge of language models in different applications, attention to safety and robustness of these models has gained significant importance. Here we introduce a joint framework in which we simultaneously probe and improve the robustness of a black-box target model via adversarial prompting and belief augmentation using iterative feedback loops. This framework utilizes an automated red teaming approach to probe the target model, along with a belief augmenter to generate instructions for the target model to improve its robustness to those adversarial probes. Importantly, the adversarial model and the belief generator leverage the feedback from past interactions to improve the effectiveness of the adversarial prompts and beliefs, respectively. In our experiments, we demonstrate that such a framework can reduce toxic content generation both in dynamic cases where an adversary directly interacts with a target model and static cases where we use a static benchmark dataset to evaluate our model.
Generative Speech Recognition Error Correction with Large Language Models and Task-Activating Prompting
Oct 10, 2023We explore the ability of large language models (LLMs) to act as speech recognition post-processors that perform rescoring and error correction. Our first focus is on instruction prompting to let LLMs perform these task without fine-tuning, for which we evaluate different prompting schemes, both zero- and few-shot in-context learning, and a novel task activation prompting method that combines causal instructions and demonstration to increase its context windows. Next, we show that rescoring only by in-context learning with frozen LLMs achieves results that are competitive with rescoring by domain-tuned LMs, using a pretrained first-pass recognition system and rescoring output on two out-of-domain tasks (ATIS and WSJ). By combining prompting techniques with fine-tuning we achieve error rates below the N-best oracle level, showcasing the generalization power of the LLMs.
Low-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition
Sep 26, 2023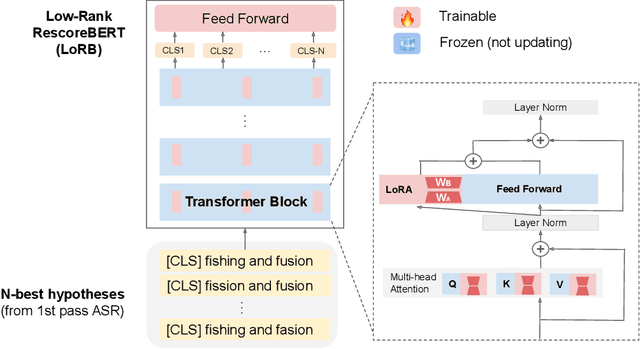
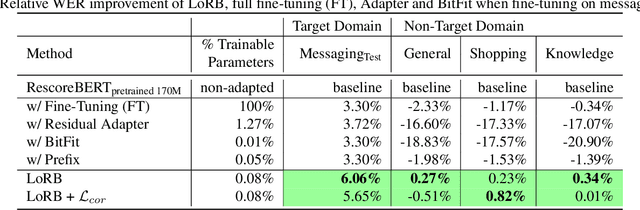
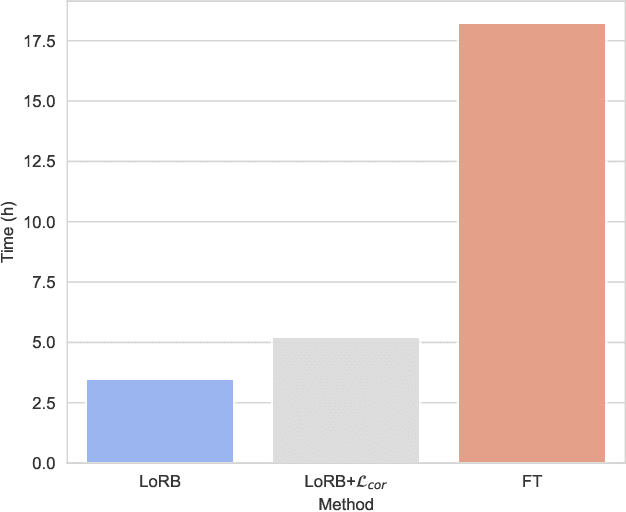
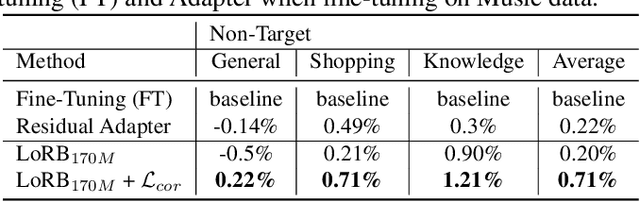
We propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.
FLIRT: Feedback Loop In-context Red Teaming
Aug 08, 2023



Warning: this paper contains content that may be inappropriate or offensive. As generative models become available for public use in various applications, testing and analyzing vulnerabilities of these models has become a priority. Here we propose an automatic red teaming framework that evaluates a given model and exposes its vulnerabilities against unsafe and inappropriate content generation. Our framework uses in-context learning in a feedback loop to red team models and trigger them into unsafe content generation. We propose different in-context attack strategies to automatically learn effective and diverse adversarial prompts for text-to-image models. Our experiments demonstrate that compared to baseline approaches, our proposed strategy is significantly more effective in exposing vulnerabilities in Stable Diffusion (SD) model, even when the latter is enhanced with safety features. Furthermore, we demonstrate that the proposed framework is effective for red teaming text-to-text models, resulting in significantly higher toxic response generation rate compared to previously reported numbers.