 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Self-Learning Framework For Interactive Spoken Dialog Systems
Sep 16, 2024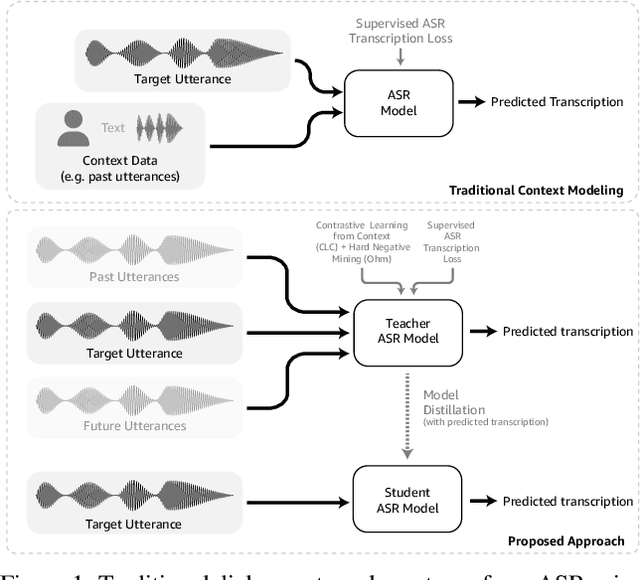

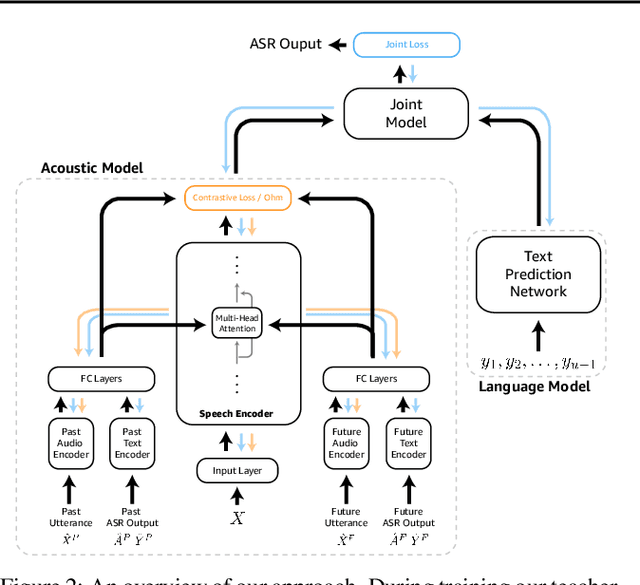
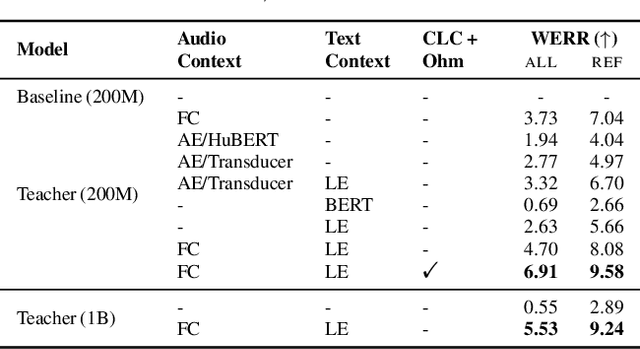
Dialog systems, such as voice assistants, are expected to engage with users in complex, evolving conversations. Unfortunately, traditional automatic speech recognition (ASR) systems deployed in such applications are usually trained to recognize each turn independently and lack the ability to adapt to the conversational context or incorporate user feedback. In this work, we introduce a general framework for ASR in dialog systems that can go beyond learning from single-turn utterances and learn over time how to adapt to both explicit supervision and implicit user feedback present in multi-turn conversations. We accomplish that by leveraging advances in student-teacher learning and context-aware dialog processing, and designing contrastive self-supervision approaches with Ohm, a new online hard-negative mining approach. We show that leveraging our new framework compared to traditional training leads to relative WER reductions of close to 10% in real-world dialog systems, and up to 26% on public synthetic data.
Using Optimal Transport as Alignment Objective for fine-tuning Multilingual Contextualized Embeddings
Oct 06, 2021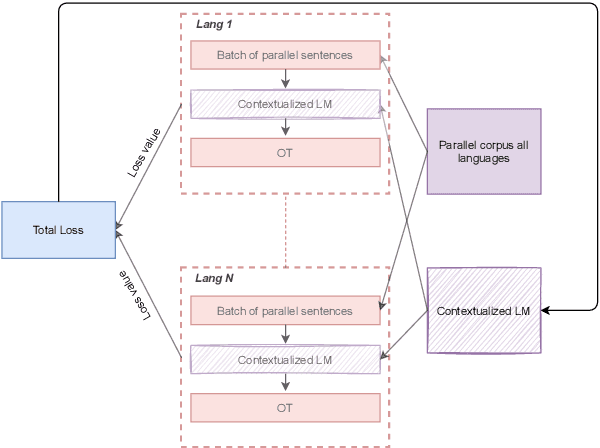
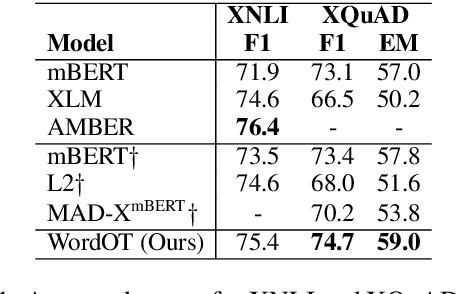

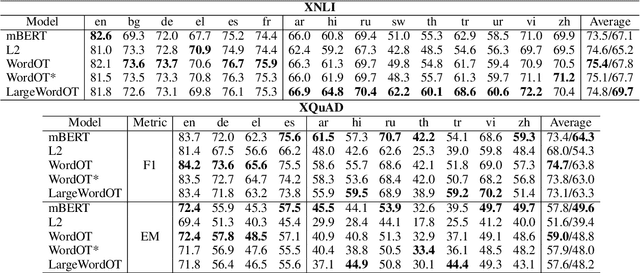
Recent studies have proposed different methods to improve multilingual word representations in contextualized settings including techniques that align between source and target embedding spaces. For contextualized embeddings, alignment becomes more complex as we additionally take context into consideration. In this work, we propose using Optimal Transport (OT) as an alignment objective during fine-tuning to further improve multilingual contextualized representations for downstream cross-lingual transfer. This approach does not require word-alignment pairs prior to fine-tuning that may lead to sub-optimal matching and instead learns the word alignments within context in an unsupervised manner. It also allows different types of mappings due to soft matching between source and target sentences. We benchmark our proposed method on two tasks (XNLI and XQuAD) and achieve improvements over baselines as well as competitive results compared to similar recent works.
An Empirical Study on Robustness to Spurious Correlations using Pre-trained Language Models
Aug 11, 2020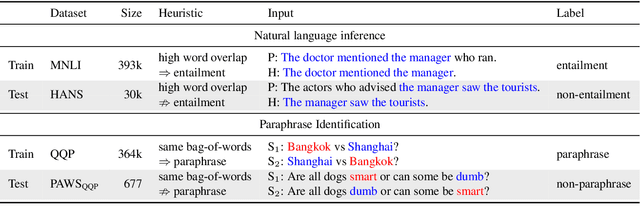
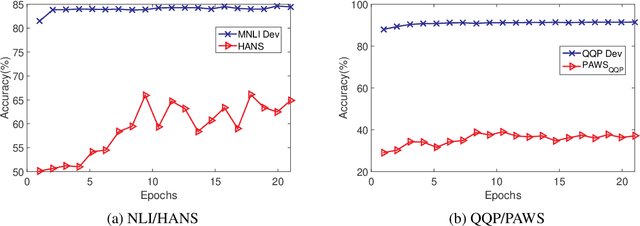
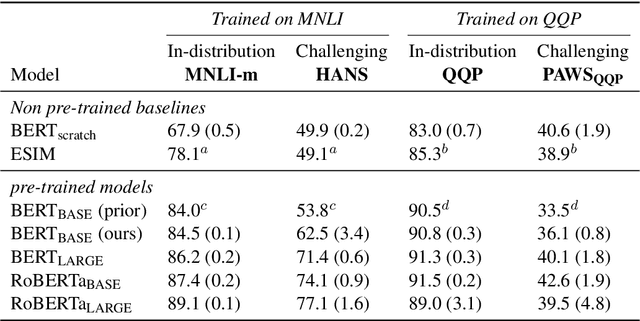
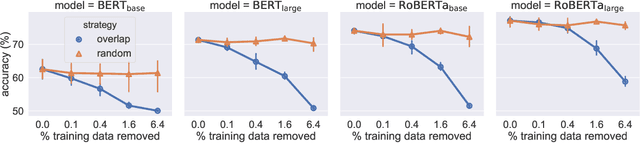
Recent work has shown that pre-trained language models such as BERT improve robustness to spurious correlations in the dataset. Intrigued by these results, we find that the key to their success is generalization from a small amount of counterexamples where the spurious correlations do not hold. When such minority examples are scarce, pre-trained models perform as poorly as models trained from scratch. In the case of extreme minority, we propose to use multi-task learning (MTL) to improve generalization. Our experiments on natural language inference and paraphrase identification show that MTL with the right auxiliary tasks significantly improves performance on challenging examples without hurting the in-distribution performance. Further, we show that the gain from MTL mainly comes from improved generalization from the minority examples. Our results highlight the importance of data diversity for overcoming spurious correlations.
CASA-NLU: Context-Aware Self-Attentive Natural Language Understanding for Task-Oriented Chatbots
Sep 18, 2019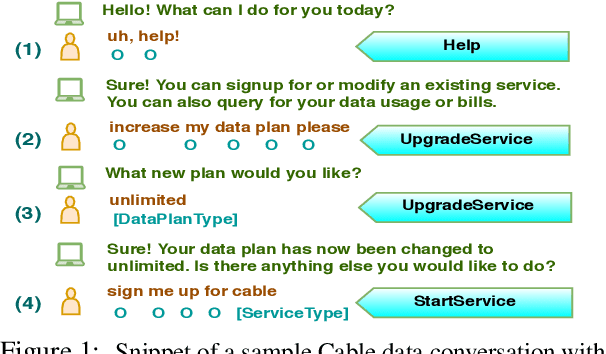

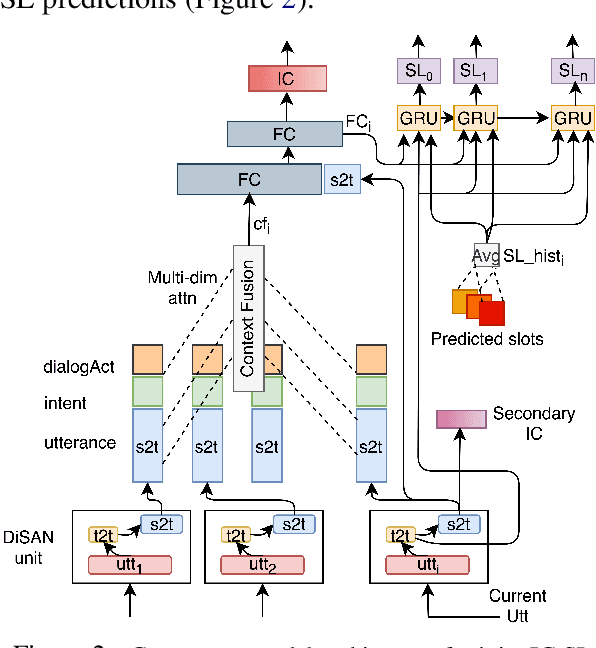
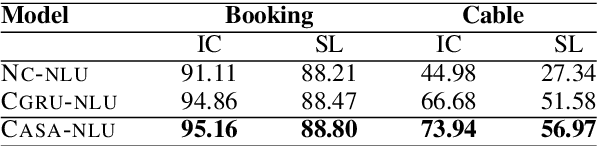
Natural Language Understanding (NLU) is a core component of dialog systems. It typically involves two tasks - intent classification (IC) and slot labeling (SL), which are then followed by a dialogue management (DM) component. Such NLU systems cater to utterances in isolation, thus pushing the problem of context management to DM. However, contextual information is critical to the correct prediction of intents and slots in a conversation. Prior work on contextual NLU has been limited in terms of the types of contextual signals used and the understanding of their impact on the model. In this work, we propose a context-aware self-attentive NLU (CASA-NLU) model that uses multiple signals, such as previous intents, slots, dialog acts and utterances over a variable context window, in addition to the current user utterance. CASA-NLU outperforms a recurrent contextual NLU baseline on two conversational datasets, yielding a gain of up to 7% on the IC task for one of the datasets. Moreover, a non-contextual variant of CASA-NLU achieves state-of-the-art performance for IC task on standard public datasets - Snips and ATIS.