 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-based Knowledge Distillation with LLM-as-a-Judge
Apr 03, 2026Reinforcement Learning (RL) has been shown to substantially improve the reasoning capability of small and large language models (LLMs), but existing approaches typically rely on verifiable rewards, hence ground truth labels. We propose an RL framework that uses rewards from an LLM that acts as a judge evaluating model outputs over large amounts of unlabeled data, enabling label-free knowledge distillation and replacing the need of ground truth supervision. Notably, the judge operates with a single-token output, making reward computation efficient. When combined with verifiable rewards, our approach yields substantial performance gains across math reasoning benchmarks. These results suggest that LLM-based evaluators can produce effective training signals for RL fine-tuning.
LLM NL2SQL Robustness: Surface Noise vs. Linguistic Variation in Traditional and Agentic Settings
Mar 17, 2026Robustness evaluation for Natural Language to SQL (NL2SQL) systems is essential because real-world database environments are dynamic, noisy, and continuously evolving, whereas conventional benchmark evaluations typically assume static schemas and well-formed user inputs. In this work, we introduce a robustness evaluation benchmark containing approximately ten types of perturbations and conduct evaluations under both traditional and agentic settings. We assess multiple state-of-the-art large language models (LLMs), including Grok-4.1, Gemini-3-Pro, Claude-Opus-4.6, and GPT-5.2. Our results show that these models generally maintain strong performance under several perturbations; however, notable performance degradation is observed for surface-level noise (e.g., character-level corruption) and linguistic variation that preserves semantics while altering lexical or syntactic forms. Furthermore, we observe that surface-level noise causes larger performance drops in traditional pipelines, whereas linguistic variation presents greater challenges in agentic settings. These findings highlight the remaining challenges in achieving robust NL2SQL systems, particularly in handling linguistic variability.
Retrofitting Small Multilingual Models for Retrieval: Matching 7B Performance with 300M Parameters
Oct 16, 2025Training effective multilingual embedding models presents unique challenges due to the diversity of languages and task objectives. Although small multilingual models (<1 B parameters) perform well on multilingual tasks generally, they consistently lag behind larger models (>1 B) in the most prevalent use case: retrieval. This raises a critical question: Can smaller models be retrofitted specifically for retrieval tasks to enhance their performance? In this work, we investigate key factors that influence the effectiveness of multilingual embeddings, focusing on training data scale, negative sampling strategies, and data diversity. We find that while increasing the scale of training data yields initial performance gains, these improvements quickly plateau - indicating diminishing returns. Incorporating hard negatives proves essential for consistently improving retrieval accuracy. Furthermore, our analysis reveals that task diversity in the training data contributes more significantly to performance than language diversity alone. As a result, we develop a compact (approximately 300M) multilingual model that achieves retrieval performance comparable to or even surpassing current strong 7B models.
Investigating Factuality in Long-Form Text Generation: The Roles of Self-Known and Self-Unknown
Nov 24, 2024



Large language models (LLMs) have demonstrated strong capabilities in text understanding and generation. However, they often lack factuality, producing a mixture of true and false information, especially in long-form generation. In this work, we investigates the factuality of long-form text generation across various large language models (LLMs), including GPT-4, Gemini-1.5-Pro, Claude-3-Opus, Llama-3-70B, and Mistral. Our analysis reveals that factuality scores tend to decline in later sentences of the generated text, accompanied by a rise in the number of unsupported claims. Furthermore, we explore the effectiveness of different evaluation settings to assess whether LLMs can accurately judge the correctness of their own outputs: Self-Known (the percentage of supported atomic claims, decomposed from LLM outputs, that the corresponding LLMs judge as correct) and Self-Unknown (the percentage of unsupported atomic claims that the corresponding LLMs judge as incorrect). The results indicate that even advanced models like GPT-4 and Gemini-1.5-Pro fail to achieve perfect Self-Known scores, while their Self-Unknown scores remain notably above zero, reflecting ongoing uncertainty in their self-assessments. Moreover, we find a correlation between higher Self-Known scores and improved factuality, while higher Self-Unknown scores are associated with lower factuality. Interestingly, even without significant changes in the models' self-judgment (Self-Known and Self-Unknown), the number of unsupported claims can increases, likely as an artifact of long-form generation. These findings show the limitations of current LLMs in long-form generation, and provide valuable insights for improving factuality in long-form text generation.
Traffic Light or Light Traffic? Investigating Phrasal Semantics in Large Language Models
Oct 03, 2024

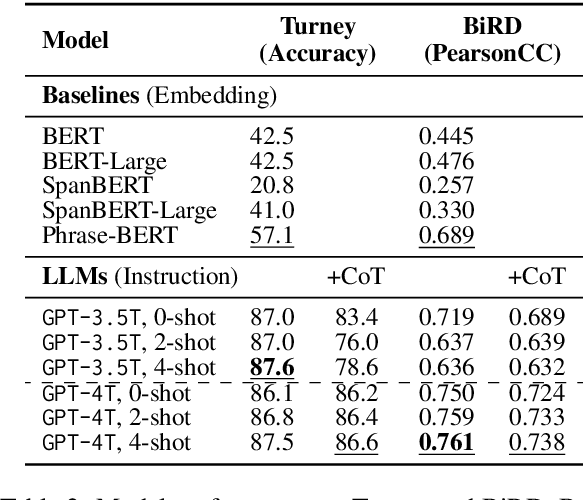

Phrases are fundamental linguistic units through which humans convey semantics. This study critically examines the capacity of API-based large language models (LLMs) to comprehend phrase semantics, utilizing three human-annotated datasets. We assess the performance of LLMs in executing phrase semantic reasoning tasks guided by natural language instructions and explore the impact of common prompting techniques, including few-shot demonstrations and Chain-of-Thought reasoning. Our findings reveal that LLMs greatly outperform traditional embedding methods across the datasets; however, they do not show a significant advantage over fine-tuned methods. The effectiveness of advanced prompting strategies shows variability. We conduct detailed error analyses to interpret the limitations faced by LLMs in comprehending phrase semantics. Code and data can be found at https://github.com/memray/llm_phrase_semantics.
xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations
Aug 22, 2024



We present xGen-VideoSyn-1, a text-to-video (T2V) generation model capable of producing realistic scenes from textual descriptions. Building on recent advancements, such as OpenAI's Sora, we explore the latent diffusion model (LDM) architecture and introduce a video variational autoencoder (VidVAE). VidVAE compresses video data both spatially and temporally, significantly reducing the length of visual tokens and the computational demands associated with generating long-sequence videos. To further address the computational costs, we propose a divide-and-merge strategy that maintains temporal consistency across video segments. Our Diffusion Transformer (DiT) model incorporates spatial and temporal self-attention layers, enabling robust generalization across different timeframes and aspect ratios. We have devised a data processing pipeline from the very beginning and collected over 13M high-quality video-text pairs. The pipeline includes multiple steps such as clipping, text detection, motion estimation, aesthetics scoring, and dense captioning based on our in-house video-LLM model. Training the VidVAE and DiT models required approximately 40 and 642 H100 days, respectively. Our model supports over 14-second 720p video generation in an end-to-end way and demonstrates competitive performance against state-of-the-art T2V models.
Unlocking Anticipatory Text Generation: A Constrained Approach for Faithful Decoding with Large Language Models
Dec 11, 2023


Large Language Models (LLMs) have demonstrated a powerful ability for text generation. However, achieving optimal results with a given prompt or instruction can be challenging, especially for billion-sized models. Additionally, undesired behaviors such as toxicity or hallucinations can manifest. While much larger models (e.g., ChatGPT) may demonstrate strength in mitigating these issues, there is still no guarantee of complete prevention. In this work, we propose formalizing text generation as a future-constrained generation problem to minimize undesirable behaviors and enforce faithfulness to instructions. The estimation of future constraint satisfaction, accomplished using LLMs, guides the text generation process. Our extensive experiments demonstrate the effectiveness of the proposed approach across three distinct text generation tasks: keyword-constrained generation (Lin et al., 2020), toxicity reduction (Gehman et al., 2020), and factual correctness in question-answering (Gao et al., 2023).
XGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.
Efficiently Aligned Cross-Lingual Transfer Learning for Conversational Tasks using Prompt-Tuning
Apr 03, 2023



Cross-lingual transfer of language models trained on high-resource languages like English has been widely studied for many NLP tasks, but focus on conversational tasks has been rather limited. This is partly due to the high cost of obtaining non-English conversational data, which results in limited coverage. In this work, we introduce XSGD, a parallel and large-scale multilingual conversation dataset that we created by translating the English-only Schema-Guided Dialogue (SGD) dataset (Rastogi et al., 2020) into 105 other languages. XSGD contains approximately 330k utterances per language. To facilitate aligned cross-lingual representations, we develop an efficient prompt-tuning-based method for learning alignment prompts. We also investigate two different classifiers: NLI-based and vanilla classifiers, and test cross-lingual capability enabled by the aligned prompts. We evaluate our model's cross-lingual generalization capabilities on two conversation tasks: slot-filling and intent classification. Our results demonstrate the strong and efficient modeling ability of NLI-based classifiers and the large cross-lingual transfer improvements achieved by our aligned prompts, particularly in few-shot settings.
Unsupervised Dense Retrieval Deserves Better Positive Pairs: Scalable Augmentation with Query Extraction and Generation
Dec 17, 2022



Dense retrievers have made significant strides in obtaining state-of-the-art results on text retrieval and open-domain question answering (ODQA). Yet most of these achievements were made possible with the help of large annotated datasets, unsupervised learning for dense retrieval models remains an open problem. In this work, we explore two categories of methods for creating pseudo query-document pairs, named query extraction (QExt) and transferred query generation (TQGen), to augment the retriever training in an annotation-free and scalable manner. Specifically, QExt extracts pseudo queries by document structures or selecting salient random spans, and TQGen utilizes generation models trained for other NLP tasks (e.g., summarization) to produce pseudo queries. Extensive experiments show that dense retrievers trained with individual augmentation methods can perform comparably well with multiple strong baselines, and combining them leads to further improvements, achieving state-of-the-art performance of unsupervised dense retrieval on both BEIR and ODQA datasets.