 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRMArena-Pro: Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions
May 24, 2025While AI agents hold transformative potential in business, effective performance benchmarking is hindered by the scarcity of public, realistic business data on widely used platforms. Existing benchmarks often lack fidelity in their environments, data, and agent-user interactions, with limited coverage of diverse business scenarios and industries. To address these gaps, we introduce CRMArena-Pro, a novel benchmark for holistic, realistic assessment of LLM agents in diverse professional settings. CRMArena-Pro expands on CRMArena with nineteen expert-validated tasks across sales, service, and 'configure, price, and quote' processes, for both Business-to-Business and Business-to-Customer scenarios. It distinctively incorporates multi-turn interactions guided by diverse personas and robust confidentiality awareness assessments. Experiments reveal leading LLM agents achieve only around 58% single-turn success on CRMArena-Pro, with performance dropping significantly to approximately 35% in multi-turn settings. While Workflow Execution proves more tractable for top agents (over 83% single-turn success), other evaluated business skills present greater challenges. Furthermore, agents exhibit near-zero inherent confidentiality awareness; though targeted prompting can improve this, it often compromises task performance. These findings highlight a substantial gap between current LLM capabilities and enterprise demands, underscoring the need for advancements in multi-turn reasoning, confidentiality adherence, and versatile skill acquisition.
BingoGuard: LLM Content Moderation Tools with Risk Levels
Mar 09, 2025Malicious content generated by large language models (LLMs) can pose varying degrees of harm. Although existing LLM-based moderators can detect harmful content, they struggle to assess risk levels and may miss lower-risk outputs. Accurate risk assessment allows platforms with different safety thresholds to tailor content filtering and rejection. In this paper, we introduce per-topic severity rubrics for 11 harmful topics and build BingoGuard, an LLM-based moderation system designed to predict both binary safety labels and severity levels. To address the lack of annotations on levels of severity, we propose a scalable generate-then-filter framework that first generates responses across different severity levels and then filters out low-quality responses. Using this framework, we create BingoGuardTrain, a training dataset with 54,897 examples covering a variety of topics, response severity, styles, and BingoGuardTest, a test set with 988 examples explicitly labeled based on our severity rubrics that enables fine-grained analysis on model behaviors on different severity levels. Our BingoGuard-8B, trained on BingoGuardTrain, achieves the state-of-the-art performance on several moderation benchmarks, including WildGuardTest and HarmBench, as well as BingoGuardTest, outperforming best public models, WildGuard, by 4.3\%. Our analysis demonstrates that incorporating severity levels into training significantly enhances detection performance and enables the model to effectively gauge the severity of harmful responses.
Evaluating Cultural and Social Awareness of LLM Web Agents
Oct 30, 2024As large language models (LLMs) expand into performing as agents for real-world applications beyond traditional NLP tasks, evaluating their robustness becomes increasingly important. However, existing benchmarks often overlook critical dimensions like cultural and social awareness. To address these, we introduce CASA, a benchmark designed to assess LLM agents' sensitivity to cultural and social norms across two web-based tasks: online shopping and social discussion forums. Our approach evaluates LLM agents' ability to detect and appropriately respond to norm-violating user queries and observations. Furthermore, we propose a comprehensive evaluation framework that measures awareness coverage, helpfulness in managing user queries, and the violation rate when facing misleading web content. Experiments show that current LLMs perform significantly better in non-agent than in web-based agent environments, with agents achieving less than 10% awareness coverage and over 40% violation rates. To improve performance, we explore two methods: prompting and fine-tuning, and find that combining both methods can offer complementary advantages -- fine-tuning on culture-specific datasets significantly enhances the agents' ability to generalize across different regions, while prompting boosts the agents' ability to navigate complex tasks. These findings highlight the importance of constantly benchmarking LLM agents' cultural and social awareness during the development cycle.
Investigating the prompt leakage effect and black-box defenses for multi-turn LLM interactions
Apr 26, 2024



Prompt leakage in large language models (LLMs) poses a significant security and privacy threat, particularly in retrieval-augmented generation (RAG) systems. However, leakage in multi-turn LLM interactions along with mitigation strategies has not been studied in a standardized manner. This paper investigates LLM vulnerabilities against prompt leakage across 4 diverse domains and 10 closed- and open-source LLMs. Our unique multi-turn threat model leverages the LLM's sycophancy effect and our analysis dissects task instruction and knowledge leakage in the LLM response. In a multi-turn setting, our threat model elevates the average attack success rate (ASR) to 86.2%, including a 99% leakage with GPT-4 and claude-1.3. We find that some black-box LLMs like Gemini show variable susceptibility to leakage across domains - they are more likely to leak contextual knowledge in the news domain compared to the medical domain. Our experiments measure specific effects of 6 black-box defense strategies, including a query-rewriter in the RAG scenario. Our proposed multi-tier combination of defenses still has an ASR of 5.3% for black-box LLMs, indicating room for enhancement and future direction for LLM security research.
Art or Artifice? Large Language Models and the False Promise of Creativity
Sep 25, 2023Researchers have argued that large language models (LLMs) exhibit high-quality writing capabilities from blogs to stories. However, evaluating objectively the creativity of a piece of writing is challenging. Inspired by the Torrance Test of Creative Thinking (TTCT), which measures creativity as a process, we use the Consensual Assessment Technique [3] and propose the Torrance Test of Creative Writing (TTCW) to evaluate creativity as a product. TTCW consists of 14 binary tests organized into the original dimensions of Fluency, Flexibility, Originality, and Elaboration. We recruit 10 creative writers and implement a human assessment of 48 stories written either by professional authors or LLMs using TTCW. Our analysis shows that LLM-generated stories pass 3-10X less TTCW tests than stories written by professionals. In addition, we explore the use of LLMs as assessors to automate the TTCW evaluation, revealing that none of the LLMs positively correlate with the expert assessments.
SPLAL: Similarity-based pseudo-labeling with alignment loss for semi-supervised medical image classification
Jul 10, 2023



Medical image classification is a challenging task due to the scarcity of labeled samples and class imbalance caused by the high variance in disease prevalence. Semi-supervised learning (SSL) methods can mitigate these challenges by leveraging both labeled and unlabeled data. However, SSL methods for medical image classification need to address two key challenges: (1) estimating reliable pseudo-labels for the images in the unlabeled dataset and (2) reducing biases caused by class imbalance. In this paper, we propose a novel SSL approach, SPLAL, that effectively addresses these challenges. SPLAL leverages class prototypes and a weighted combination of classifiers to predict reliable pseudo-labels over a subset of unlabeled images. Additionally, we introduce alignment loss to mitigate model biases toward majority classes. To evaluate the performance of our proposed approach, we conduct experiments on two publicly available medical image classification benchmark datasets: the skin lesion classification (ISIC 2018) and the blood cell classification dataset (BCCD). The experimental results empirically demonstrate that our approach outperforms several state-of-the-art SSL methods over various evaluation metrics. Specifically, our proposed approach achieves a significant improvement over the state-of-the-art approach on the ISIC 2018 dataset in both Accuracy and F1 score, with relative margins of 2.24\% and 11.40\%, respectively. Finally, we conduct extensive ablation experiments to examine the contribution of different components of our approach, validating its effectiveness.
LLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond
May 23, 2023



With the recent appearance of LLMs in practical settings, having methods that can effectively detect factual inconsistencies is crucial to reduce the propagation of misinformation and improve trust in model outputs. When testing on existing factual consistency benchmarks, we find that a few large language models (LLMs) perform competitively on classification benchmarks for factual inconsistency detection compared to traditional non-LLM methods. However, a closer analysis reveals that most LLMs fail on more complex formulations of the task and exposes issues with existing evaluation benchmarks, affecting evaluation precision. To address this, we propose a new protocol for inconsistency detection benchmark creation and implement it in a 10-domain benchmark called SummEdits. This new benchmark is 20 times more cost-effective per sample than previous benchmarks and highly reproducible, as we estimate inter-annotator agreement at about 0.9. Most LLMs struggle on SummEdits, with performance close to random chance. The best-performing model, GPT-4, is still 8\% below estimated human performance, highlighting the gaps in LLMs' ability to reason about facts and detect inconsistencies when they occur.
Unsupervised Dense Retrieval Deserves Better Positive Pairs: Scalable Augmentation with Query Extraction and Generation
Dec 17, 2022Dense retrievers have made significant strides in obtaining state-of-the-art results on text retrieval and open-domain question answering (ODQA). Yet most of these achievements were made possible with the help of large annotated datasets, unsupervised learning for dense retrieval models remains an open problem. In this work, we explore two categories of methods for creating pseudo query-document pairs, named query extraction (QExt) and transferred query generation (TQGen), to augment the retriever training in an annotation-free and scalable manner. Specifically, QExt extracts pseudo queries by document structures or selecting salient random spans, and TQGen utilizes generation models trained for other NLP tasks (e.g., summarization) to produce pseudo queries. Extensive experiments show that dense retrievers trained with individual augmentation methods can perform comparably well with multiple strong baselines, and combining them leads to further improvements, achieving state-of-the-art performance of unsupervised dense retrieval on both BEIR and ODQA datasets.
CREATIVESUMM: Shared Task on Automatic Summarization for Creative Writing
Nov 10, 2022This paper introduces the shared task of summarizing documents in several creative domains, namely literary texts, movie scripts, and television scripts. Summarizing these creative documents requires making complex literary interpretations, as well as understanding non-trivial temporal dependencies in texts containing varied styles of plot development and narrative structure. This poses unique challenges and is yet underexplored for text summarization systems. In this shared task, we introduce four sub-tasks and their corresponding datasets, focusing on summarizing books, movie scripts, primetime television scripts, and daytime soap opera scripts. We detail the process of curating these datasets for the task, as well as the metrics used for the evaluation of the submissions. As part of the CREATIVESUMM workshop at COLING 2022, the shared task attracted 18 submissions in total. We discuss the submissions and the baselines for each sub-task in this paper, along with directions for facilitating future work in the field.
BookSum: A Collection of Datasets for Long-form Narrative Summarization
May 18, 2021

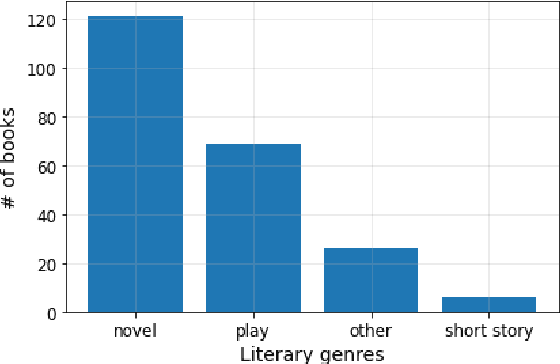

The majority of available text summarization datasets include short-form source documents that lack long-range causal and temporal dependencies, and often contain strong layout and stylistic biases. While relevant, such datasets will offer limited challenges for future generations of text summarization systems. We address these issues by introducing BookSum, a collection of datasets for long-form narrative summarization. Our dataset covers source documents from the literature domain, such as novels, plays and stories, and includes highly abstractive, human written summaries on three levels of granularity of increasing difficulty: paragraph-, chapter-, and book-level. The domain and structure of our dataset poses a unique set of challenges for summarization systems, which include: processing very long documents, non-trivial causal and temporal dependencies, and rich discourse structures. To facilitate future work, we trained and evaluated multiple extractive and abstractive summarization models as baselines for our dataset.