 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Task-Specific Knowledge from LLM for Semi-Supervised 3D Medical Image Segmentation
Jul 06, 2024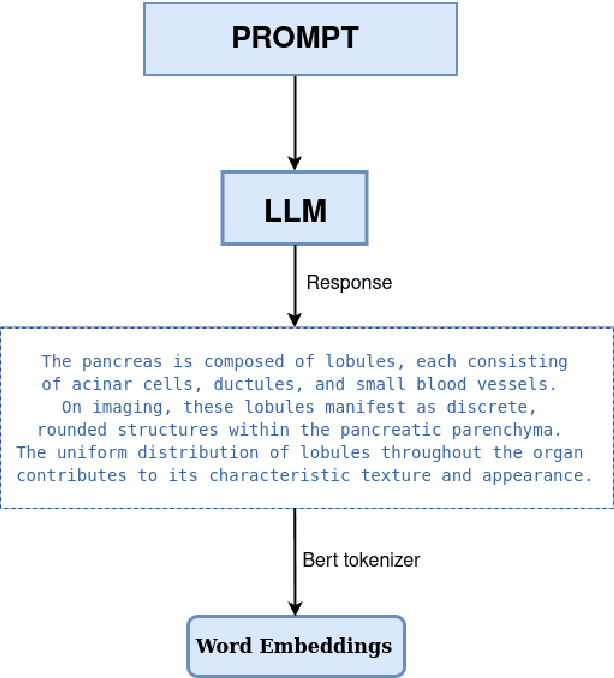
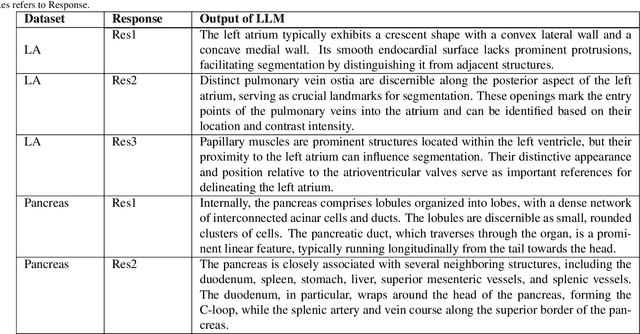
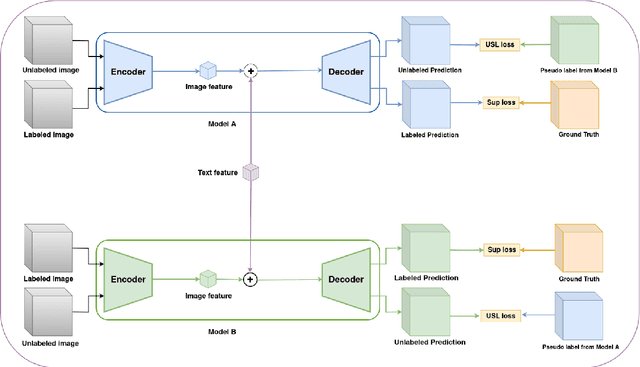
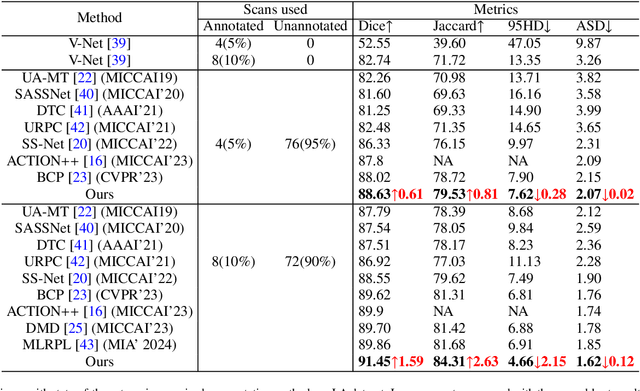
Traditional supervised 3D medical image segmentation models need voxel-level annotations, which require huge human effort, time, and cost. Semi-supervised learning (SSL) addresses this limitation of supervised learning by facilitating learning with a limited annotated and larger amount of unannotated training samples. However, state-of-the-art SSL models still struggle to fully exploit the potential of learning from unannotated samples. To facilitate effective learning from unannotated data, we introduce LLM-SegNet, which exploits a large language model (LLM) to integrate task-specific knowledge into our co-training framework. This knowledge aids the model in comprehensively understanding the features of the region of interest (ROI), ultimately leading to more efficient segmentation. Additionally, to further reduce erroneous segmentation, we propose a Unified Segmentation loss function. This loss function reduces erroneous segmentation by not only prioritizing regions where the model is confident in predicting between foreground or background pixels but also effectively addressing areas where the model lacks high confidence in predictions. Experiments on publicly available Left Atrium, Pancreas-CT, and Brats-19 datasets demonstrate the superior performance of LLM-SegNet compared to the state-of-the-art. Furthermore, we conducted several ablation studies to demonstrate the effectiveness of various modules and loss functions leveraged by LLM-SegNet.
Leveraging Fixed and Dynamic Pseudo-labels for Semi-supervised Medical Image Segmentation
May 12, 2024Semi-supervised medical image segmentation has gained growing interest due to its ability to utilize unannotated data. The current state-of-the-art methods mostly rely on pseudo-labeling within a co-training framework. These methods depend on a single pseudo-label for training, but these labels are not as accurate as the ground truth of labeled data. Relying solely on one pseudo-label often results in suboptimal results. To this end, we propose a novel approach where multiple pseudo-labels for the same unannotated image are used to learn from the unlabeled data: the conventional fixed pseudo-label and the newly introduced dynamic pseudo-label. By incorporating multiple pseudo-labels for the same unannotated image into the co-training framework, our approach provides a more robust training approach that improves model performance and generalization capabilities. We validate our novel approach on three semi-supervised medical benchmark segmentation datasets, the Left Atrium dataset, the Pancreas-CT dataset, and the Brats-2019 dataset. Our approach significantly outperforms state-of-the-art methods over multiple medical benchmark segmentation datasets with different labeled data ratios. We also present several ablation experiments to demonstrate the effectiveness of various components used in our approach.
Data efficient deep learning for medical image analysis: A survey
Oct 10, 2023The rapid evolution of deep learning has significantly advanced the field of medical image analysis. However, despite these achievements, the further enhancement of deep learning models for medical image analysis faces a significant challenge due to the scarcity of large, well-annotated datasets. To address this issue, recent years have witnessed a growing emphasis on the development of data-efficient deep learning methods. This paper conducts a thorough review of data-efficient deep learning methods for medical image analysis. To this end, we categorize these methods based on the level of supervision they rely on, encompassing categories such as no supervision, inexact supervision, incomplete supervision, inaccurate supervision, and only limited supervision. We further divide these categories into finer subcategories. For example, we categorize inexact supervision into multiple instance learning and learning with weak annotations. Similarly, we categorize incomplete supervision into semi-supervised learning, active learning, and domain-adaptive learning and so on. Furthermore, we systematically summarize commonly used datasets for data efficient deep learning in medical image analysis and investigate future research directions to conclude this survey.
Deep learning for unsupervised domain adaptation in medical imaging: Recent advancements and future perspectives
Jul 18, 2023Deep learning has demonstrated remarkable performance across various tasks in medical imaging. However, these approaches primarily focus on supervised learning, assuming that the training and testing data are drawn from the same distribution. Unfortunately, this assumption may not always hold true in practice. To address these issues, unsupervised domain adaptation (UDA) techniques have been developed to transfer knowledge from a labeled domain to a related but unlabeled domain. In recent years, significant advancements have been made in UDA, resulting in a wide range of methodologies, including feature alignment, image translation, self-supervision, and disentangled representation methods, among others. In this paper, we provide a comprehensive literature review of recent deep UDA approaches in medical imaging from a technical perspective. Specifically, we categorize current UDA research in medical imaging into six groups and further divide them into finer subcategories based on the different tasks they perform. We also discuss the respective datasets used in the studies to assess the divergence between the different domains. Finally, we discuss emerging areas and provide insights and discussions on future research directions to conclude this survey.
SPLAL: Similarity-based pseudo-labeling with alignment loss for semi-supervised medical image classification
Jul 10, 2023



Medical image classification is a challenging task due to the scarcity of labeled samples and class imbalance caused by the high variance in disease prevalence. Semi-supervised learning (SSL) methods can mitigate these challenges by leveraging both labeled and unlabeled data. However, SSL methods for medical image classification need to address two key challenges: (1) estimating reliable pseudo-labels for the images in the unlabeled dataset and (2) reducing biases caused by class imbalance. In this paper, we propose a novel SSL approach, SPLAL, that effectively addresses these challenges. SPLAL leverages class prototypes and a weighted combination of classifiers to predict reliable pseudo-labels over a subset of unlabeled images. Additionally, we introduce alignment loss to mitigate model biases toward majority classes. To evaluate the performance of our proposed approach, we conduct experiments on two publicly available medical image classification benchmark datasets: the skin lesion classification (ISIC 2018) and the blood cell classification dataset (BCCD). The experimental results empirically demonstrate that our approach outperforms several state-of-the-art SSL methods over various evaluation metrics. Specifically, our proposed approach achieves a significant improvement over the state-of-the-art approach on the ISIC 2018 dataset in both Accuracy and F1 score, with relative margins of 2.24\% and 11.40\%, respectively. Finally, we conduct extensive ablation experiments to examine the contribution of different components of our approach, validating its effectiveness.