 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Task-Specific Knowledge from LLM for Semi-Supervised 3D Medical Image Segmentation
Jul 06, 2024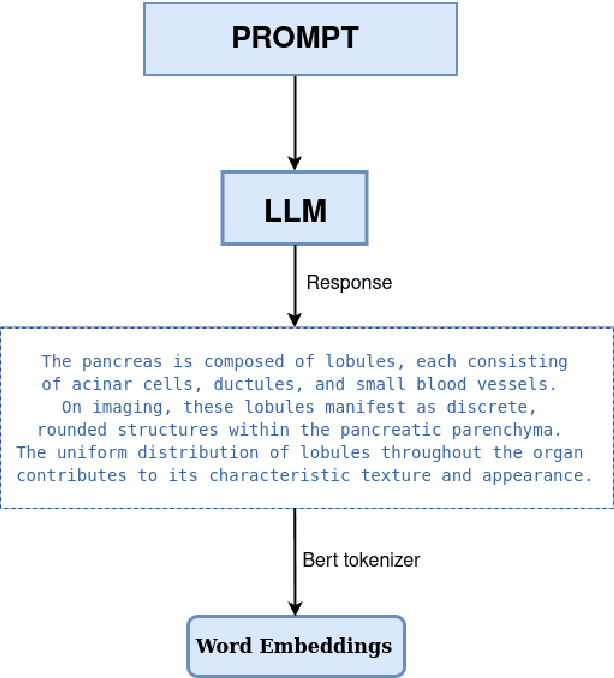
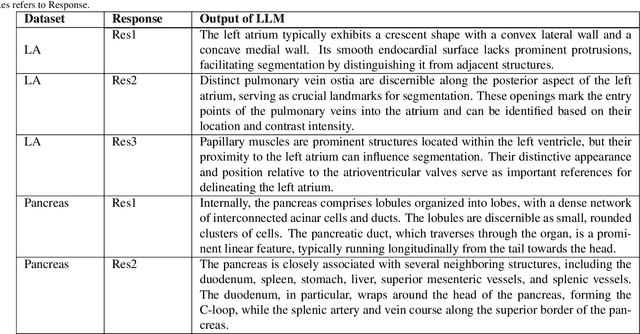
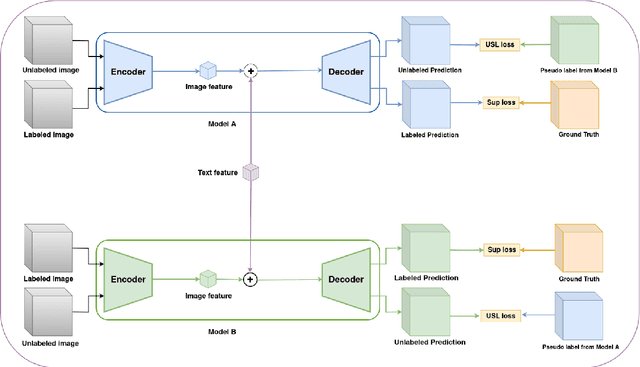
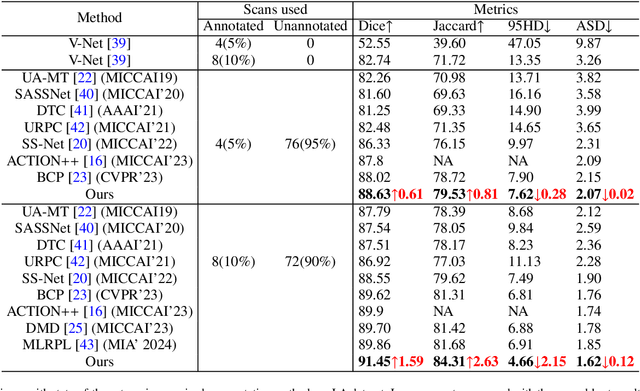
Traditional supervised 3D medical image segmentation models need voxel-level annotations, which require huge human effort, time, and cost. Semi-supervised learning (SSL) addresses this limitation of supervised learning by facilitating learning with a limited annotated and larger amount of unannotated training samples. However, state-of-the-art SSL models still struggle to fully exploit the potential of learning from unannotated samples. To facilitate effective learning from unannotated data, we introduce LLM-SegNet, which exploits a large language model (LLM) to integrate task-specific knowledge into our co-training framework. This knowledge aids the model in comprehensively understanding the features of the region of interest (ROI), ultimately leading to more efficient segmentation. Additionally, to further reduce erroneous segmentation, we propose a Unified Segmentation loss function. This loss function reduces erroneous segmentation by not only prioritizing regions where the model is confident in predicting between foreground or background pixels but also effectively addressing areas where the model lacks high confidence in predictions. Experiments on publicly available Left Atrium, Pancreas-CT, and Brats-19 datasets demonstrate the superior performance of LLM-SegNet compared to the state-of-the-art. Furthermore, we conducted several ablation studies to demonstrate the effectiveness of various modules and loss functions leveraged by LLM-SegNet.
DISBELIEVE: Distance Between Client Models is Very Essential for Effective Local Model Poisoning Attacks
Aug 14, 2023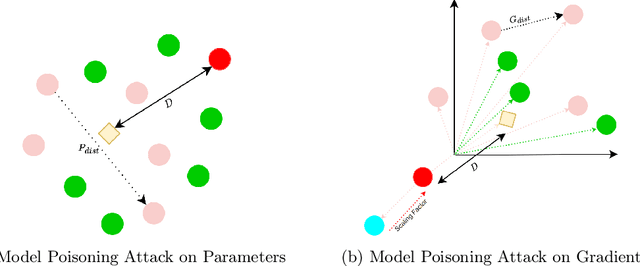



Federated learning is a promising direction to tackle the privacy issues related to sharing patients' sensitive data. Often, federated systems in the medical image analysis domain assume that the participating local clients are \textit{honest}. Several studies report mechanisms through which a set of malicious clients can be introduced that can poison the federated setup, hampering the performance of the global model. To overcome this, robust aggregation methods have been proposed that defend against those attacks. We observe that most of the state-of-the-art robust aggregation methods are heavily dependent on the distance between the parameters or gradients of malicious clients and benign clients, which makes them prone to local model poisoning attacks when the parameters or gradients of malicious and benign clients are close. Leveraging this, we introduce DISBELIEVE, a local model poisoning attack that creates malicious parameters or gradients such that their distance to benign clients' parameters or gradients is low respectively but at the same time their adverse effect on the global model's performance is high. Experiments on three publicly available medical image datasets demonstrate the efficacy of the proposed DISBELIEVE attack as it significantly lowers the performance of the state-of-the-art \textit{robust aggregation} methods for medical image analysis. Furthermore, compared to state-of-the-art local model poisoning attacks, DISBELIEVE attack is also effective on natural images where we observe a severe drop in classification performance of the global model for multi-class classification on benchmark dataset CIFAR-10.
Improved Techniques for the Conditional Generative Augmentation of Clinical Audio Data
Nov 05, 2022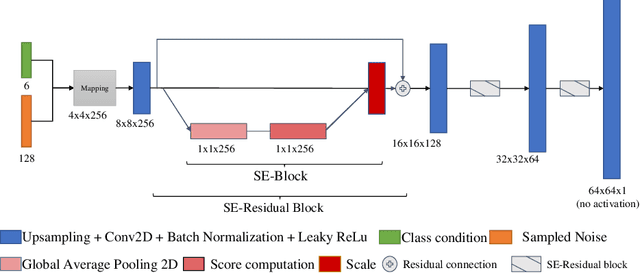

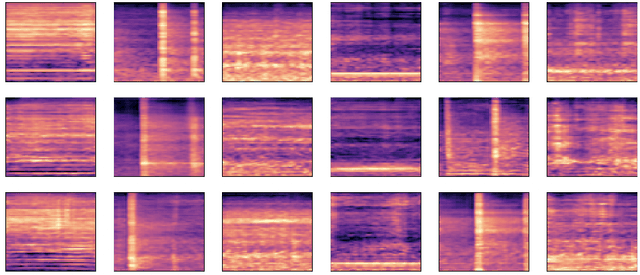
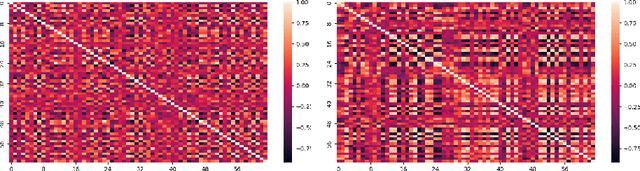
Data augmentation is a valuable tool for the design of deep learning systems to overcome data limitations and stabilize the training process. Especially in the medical domain, where the collection of large-scale data sets is challenging and expensive due to limited access to patient data, relevant environments, as well as strict regulations, community-curated large-scale public datasets, pretrained models, and advanced data augmentation methods are the main factors for developing reliable systems to improve patient care. However, for the development of medical acoustic sensing systems, an emerging field of research, the community lacks large-scale publicly available data sets and pretrained models. To address the problem of limited data, we propose a conditional generative adversarial neural network-based augmentation method which is able to synthesize mel spectrograms from a learned data distribution of a source data set. In contrast to previously proposed fully convolutional models, the proposed model implements residual Squeeze and Excitation modules in the generator architecture. We show that our method outperforms all classical audio augmentation techniques and previously published generative methods in terms of generated sample quality and a performance improvement of 2.84% of Macro F1-Score for a classifier trained on the augmented data set, an enhancement of $1.14\%$ in relation to previous work. By analyzing the correlation of intermediate feature spaces, we show that the residual Squeeze and Excitation modules help the model to reduce redundancy in the latent features. Therefore, the proposed model advances the state-of-the-art in the augmentation of clinical audio data and improves the data bottleneck for the design of clinical acoustic sensing systems.
Synthetic Data in Human Analysis: A Survey
Aug 19, 2022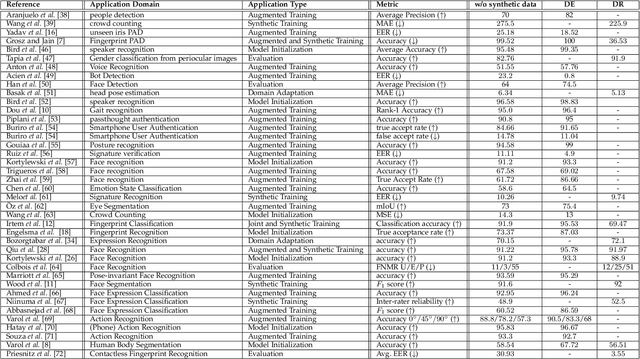



Deep neural networks have become prevalent in human analysis, boosting the performance of applications, such as biometric recognition, action recognition, as well as person re-identification. However, the performance of such networks scales with the available training data. In human analysis, the demand for large-scale datasets poses a severe challenge, as data collection is tedious, time-expensive, costly and must comply with data protection laws. Current research investigates the generation of \textit{synthetic data} as an efficient and privacy-ensuring alternative to collecting real data in the field. This survey introduces the basic definitions and methodologies, essential when generating and employing synthetic data for human analysis. We conduct a survey that summarises current state-of-the-art methods and the main benefits of using synthetic data. We also provide an overview of publicly available synthetic datasets and generation models. Finally, we discuss limitations, as well as open research problems in this field. This survey is intended for researchers and practitioners in the field of human analysis.
DILF-EN framework for Class-Incremental Learning
Dec 23, 2021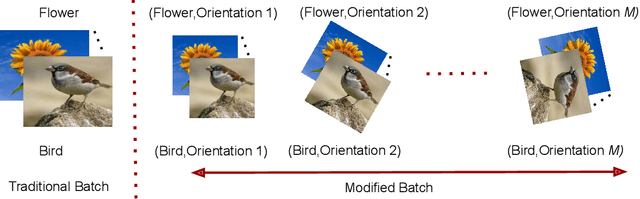
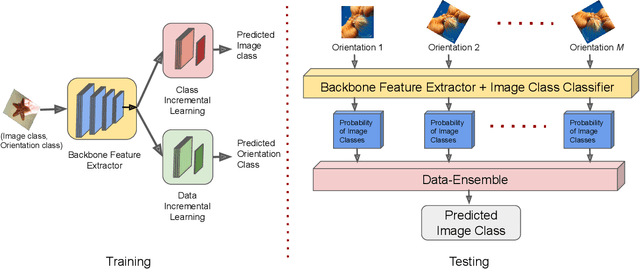

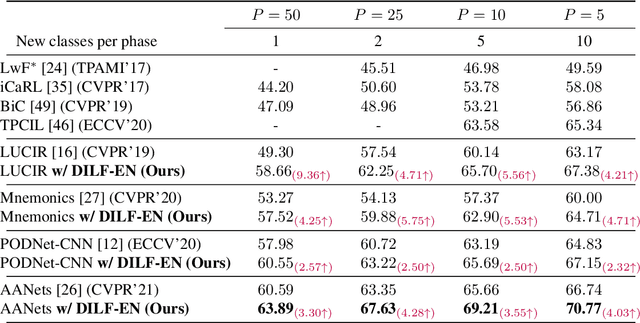
Deep learning models suffer from catastrophic forgetting of the classes in the older phases as they get trained on the classes introduced in the new phase in the class-incremental learning setting. In this work, we show that the effect of catastrophic forgetting on the model prediction varies with the change in orientation of the same image, which is a novel finding. Based on this, we propose a novel data-ensemble approach that combines the predictions for the different orientations of the image to help the model retain further information regarding the previously seen classes and thereby reduce the effect of forgetting on the model predictions. However, we cannot directly use the data-ensemble approach if the model is trained using traditional techniques. Therefore, we also propose a novel dual-incremental learning framework that involves jointly training the network with two incremental learning objectives, i.e., the class-incremental learning objective and our proposed data-incremental learning objective. In the dual-incremental learning framework, each image belongs to two classes, i.e., the image class (for class-incremental learning) and the orientation class (for data-incremental learning). In class-incremental learning, each new phase introduces a new set of classes, and the model cannot access the complete training data from the older phases. In our proposed data-incremental learning, the orientation classes remain the same across all the phases, and the data introduced by the new phase in class-incremental learning acts as new training data for these orientation classes. We empirically demonstrate that the dual-incremental learning framework is vital to the data-ensemble approach. We apply our proposed approach to state-of-the-art class-incremental learning methods and empirically show that our framework significantly improves the performance of these methods.
Sensor-invariant Fingerprint ROI Segmentation Using Recurrent Adversarial Learning
Jul 03, 2021
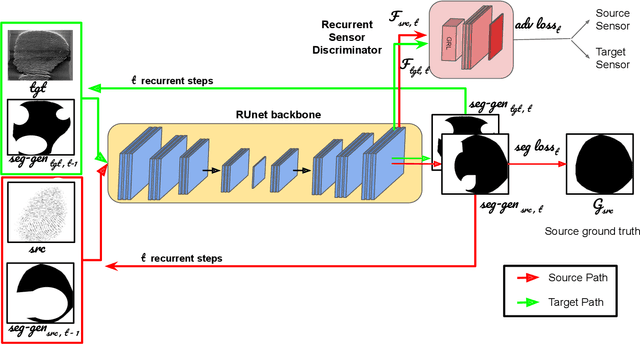

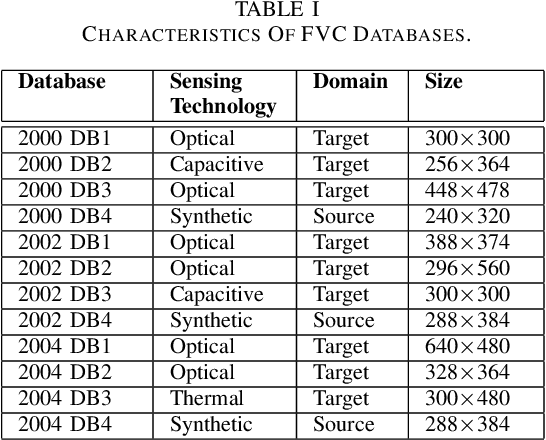
A fingerprint region of interest (roi) segmentation algorithm is designed to separate the foreground fingerprint from the background noise. All the learning based state-of-the-art fingerprint roi segmentation algorithms proposed in the literature are benchmarked on scenarios when both training and testing databases consist of fingerprint images acquired from the same sensors. However, when testing is conducted on a different sensor, the segmentation performance obtained is often unsatisfactory. As a result, every time a new fingerprint sensor is used for testing, the fingerprint roi segmentation model needs to be re-trained with the fingerprint image acquired from the new sensor and its corresponding manually marked ROI. Manually marking fingerprint ROI is expensive because firstly, it is time consuming and more importantly, requires domain expertise. In order to save the human effort in generating annotations required by state-of-the-art, we propose a fingerprint roi segmentation model which aligns the features of fingerprint images derived from the unseen sensor such that they are similar to the ones obtained from the fingerprints whose ground truth roi masks are available for training. Specifically, we propose a recurrent adversarial learning based feature alignment network that helps the fingerprint roi segmentation model to learn sensor-invariant features. Consequently, sensor-invariant features learnt by the proposed roi segmentation model help it to achieve improved segmentation performance on fingerprints acquired from the new sensor. Experiments on publicly available FVC databases demonstrate the efficacy of the proposed work.
* IJCNN 2021 (Accepted)
Data Uncertainty Guided Noise-aware Preprocessing Of Fingerprints
Jul 02, 2021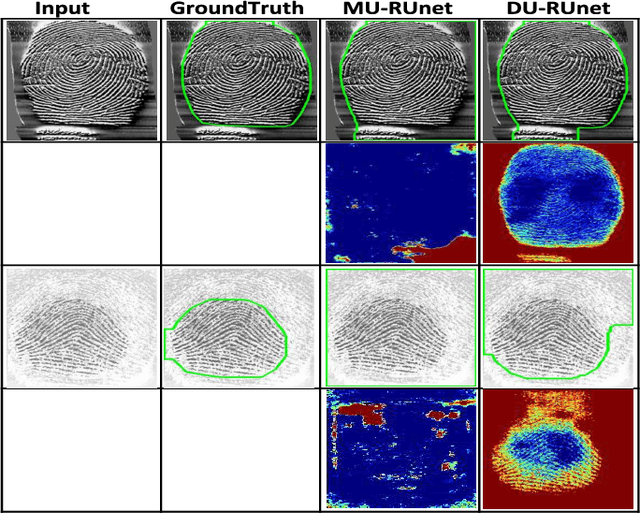
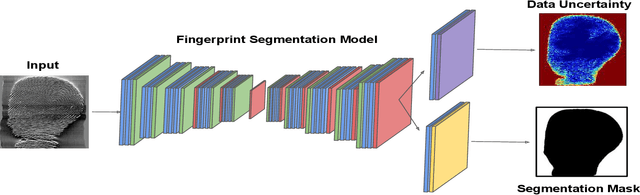
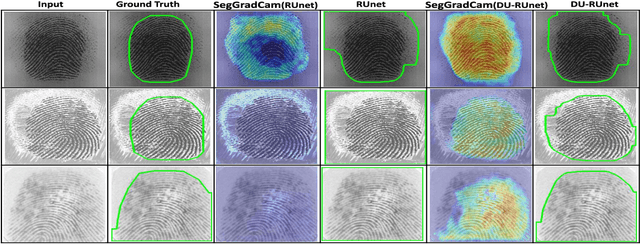

The effectiveness of fingerprint-based authentication systems on good quality fingerprints is established long back. However, the performance of standard fingerprint matching systems on noisy and poor quality fingerprints is far from satisfactory. Towards this, we propose a data uncertainty-based framework which enables the state-of-the-art fingerprint preprocessing models to quantify noise present in the input image and identify fingerprint regions with background noise and poor ridge clarity. Quantification of noise helps the model two folds: firstly, it makes the objective function adaptive to the noise in a particular input fingerprint and consequently, helps to achieve robust performance on noisy and distorted fingerprint regions. Secondly, it provides a noise variance map which indicates noisy pixels in the input fingerprint image. The predicted noise variance map enables the end-users to understand erroneous predictions due to noise present in the input image. Extensive experimental evaluation on 13 publicly available fingerprint databases, across different architectural choices and two fingerprint processing tasks demonstrate effectiveness of the proposed framework.