 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOVESe: MOVablE and Moving LiDAR Scene Segmentation with Improved Navigation in Seg-label free settings
Jun 26, 2023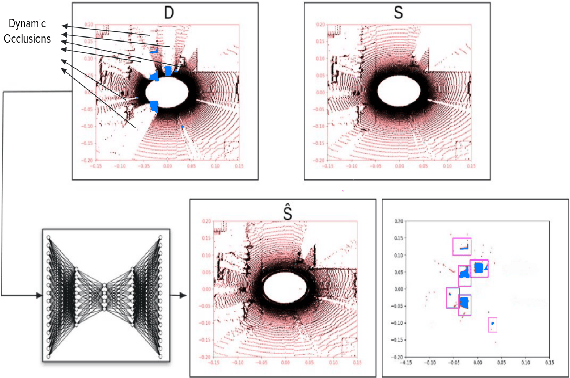


Accurate detection of movable and moving objects in LiDAR is of vital importance for navigation. Most existing works focus on extracting and removing moving objects during navigation. Movable objects like pedestrians, parked vehicles, etc. although static may move in the future. This leads to erroneous navigation and accidents. In such cases, it becomes necessary to detect potentially movable objects. To this end, we present a learning-based approach that segments movable and moving objects by generating static parts of scenes that are otherwise occluded. Our model performs superior to existing baselines on static LiDAR reconstructions using 3 datasets including a challenging sparse industrial dataset. We achieve this without the assistance of any segmentation labels because such labels might not always be available for less popular yet important settings like industrial environments. The non-movable static parts of the scene generated by our model are of vital importance for downstream navigation for SLAM. The movable objects detected by our model can be fed to a downstream 3D detector for aiding navigation. Though we do not use segmentation, we evaluate our method against navigation baselines that use it to remove dynamic objects for SLAM. Through extensive experiments on several datasets, we showcase that our model surpasses these baselines on navigation.
Sensor-invariant Fingerprint ROI Segmentation Using Recurrent Adversarial Learning
Jul 03, 2021
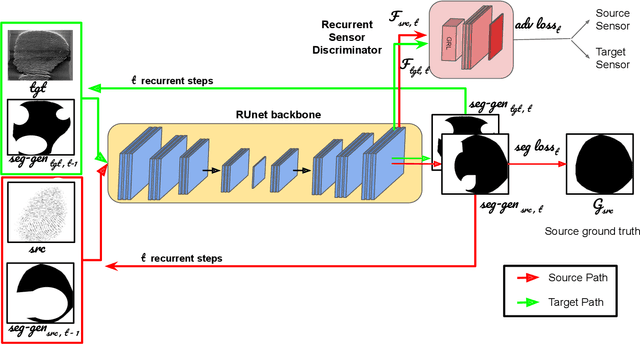

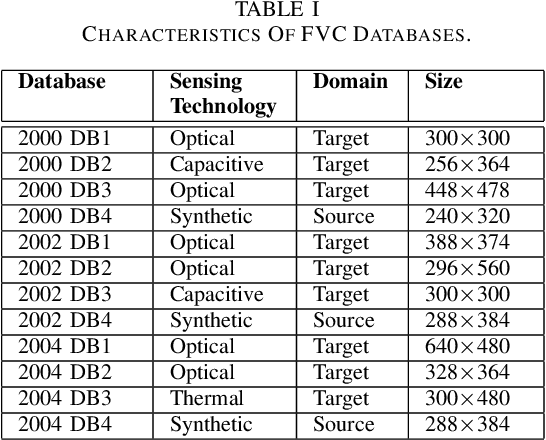
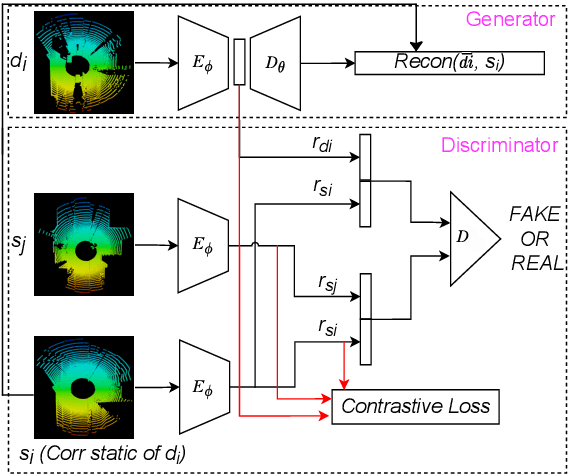
A fingerprint region of interest (roi) segmentation algorithm is designed to separate the foreground fingerprint from the background noise. All the learning based state-of-the-art fingerprint roi segmentation algorithms proposed in the literature are benchmarked on scenarios when both training and testing databases consist of fingerprint images acquired from the same sensors. However, when testing is conducted on a different sensor, the segmentation performance obtained is often unsatisfactory. As a result, every time a new fingerprint sensor is used for testing, the fingerprint roi segmentation model needs to be re-trained with the fingerprint image acquired from the new sensor and its corresponding manually marked ROI. Manually marking fingerprint ROI is expensive because firstly, it is time consuming and more importantly, requires domain expertise. In order to save the human effort in generating annotations required by state-of-the-art, we propose a fingerprint roi segmentation model which aligns the features of fingerprint images derived from the unseen sensor such that they are similar to the ones obtained from the fingerprints whose ground truth roi masks are available for training. Specifically, we propose a recurrent adversarial learning based feature alignment network that helps the fingerprint roi segmentation model to learn sensor-invariant features. Consequently, sensor-invariant features learnt by the proposed roi segmentation model help it to achieve improved segmentation performance on fingerprints acquired from the new sensor. Experiments on publicly available FVC databases demonstrate the efficacy of the proposed work.
* IJCNN 2021 (Accepted)
Data Uncertainty Guided Noise-aware Preprocessing Of Fingerprints
Jul 02, 2021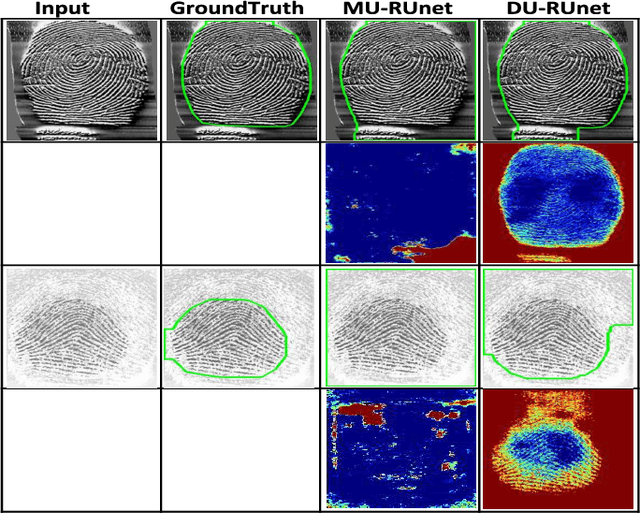
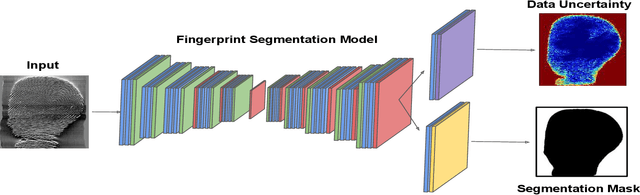
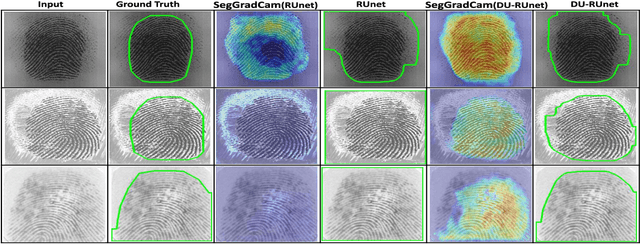

The effectiveness of fingerprint-based authentication systems on good quality fingerprints is established long back. However, the performance of standard fingerprint matching systems on noisy and poor quality fingerprints is far from satisfactory. Towards this, we propose a data uncertainty-based framework which enables the state-of-the-art fingerprint preprocessing models to quantify noise present in the input image and identify fingerprint regions with background noise and poor ridge clarity. Quantification of noise helps the model two folds: firstly, it makes the objective function adaptive to the noise in a particular input fingerprint and consequently, helps to achieve robust performance on noisy and distorted fingerprint regions. Secondly, it provides a noise variance map which indicates noisy pixels in the input fingerprint image. The predicted noise variance map enables the end-users to understand erroneous predictions due to noise present in the input image. Extensive experimental evaluation on 13 publicly available fingerprint databases, across different architectural choices and two fingerprint processing tasks demonstrate effectiveness of the proposed framework.
A Probabilistic Transmission Expansion Planning Methodology based on Roulette Wheel Selection and Social Welfare
Mar 12, 2012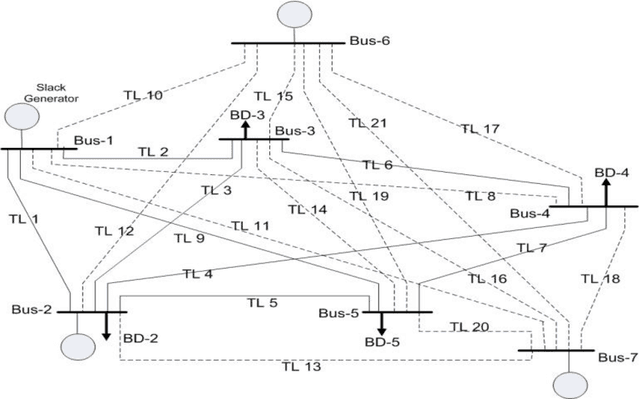
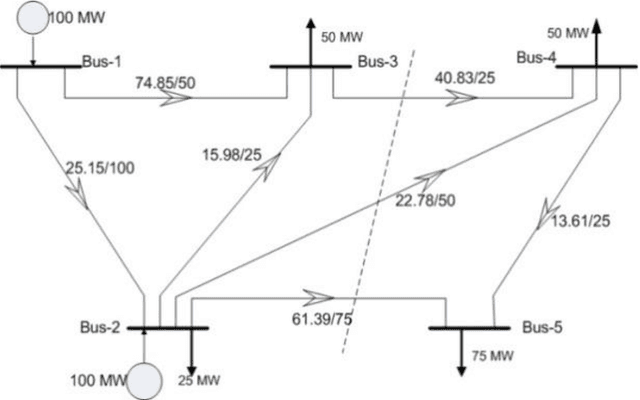
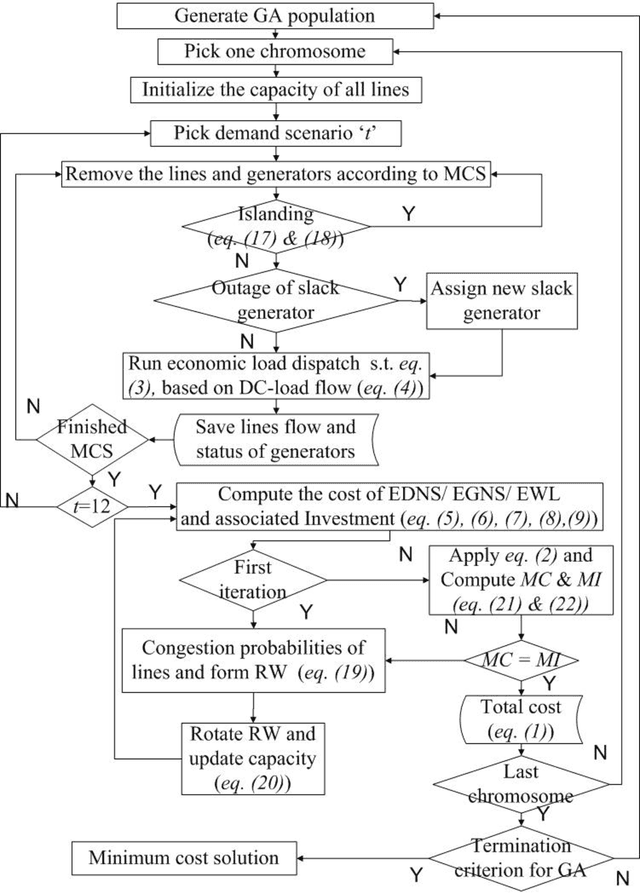
A new probabilistic methodology for transmission expansion planning (TEP) that does not require a priori specification of new/additional transmission capacities and uses the concept of social welfare has been proposed. Two new concepts have been introduced in this paper: (i) roulette wheel methodology has been used to calculate the capacity of new transmission lines and (ii) load flow analysis has been used to calculate expected demand not served (EDNS). The overall methodology has been implemented on a modified IEEE 5-bus test system. Simulations show an important result: addition of only new transmission lines is not sufficient to minimize EDNS.