 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Universal Perturbation Attacks: A Float-Coded, Penalty-Driven Evolutionary Approach
Jan 18, 2026Universal adversarial perturbations (UAPs) have garnered significant attention due to their ability to undermine deep neural networks across multiple inputs using a single noise pattern. Evolutionary algorithms offer a promising approach to generating such perturbations due to their ability to navigate non-convex, gradient-free landscapes. In this work, we introduce a float-coded, penalty-driven single-objective evolutionary framework for UAP generation that achieves lower visibility perturbations while enhancing attack success rates. Our approach leverages continuous gene representations aligned with contemporary deep learning scales, incorporates dynamic evolutionary operators with adaptive scheduling, and utilizes a modular PyTorch implementation for seamless integration with modern architectures. Additionally, we ensure the universality of the generated perturbations by testing across diverse models and by periodically switching batches to prevent overfitting. Experimental results on the ImageNet dataset demonstrate that our framework consistently produces perturbations with smaller norms, higher misclassification effectiveness, and faster convergence compared to existing evolutionary-based methods. These findings highlight the robustness and scalability of our approach for universal adversarial attacks across various deep learning architectures.
MedChat: A Multi-Agent Framework for Multimodal Diagnosis with Large Language Models
Jun 09, 2025The integration of deep learning-based glaucoma detection with large language models (LLMs) presents an automated strategy to mitigate ophthalmologist shortages and improve clinical reporting efficiency. However, applying general LLMs to medical imaging remains challenging due to hallucinations, limited interpretability, and insufficient domain-specific medical knowledge, which can potentially reduce clinical accuracy. Although recent approaches combining imaging models with LLM reasoning have improved reporting, they typically rely on a single generalist agent, restricting their capacity to emulate the diverse and complex reasoning found in multidisciplinary medical teams. To address these limitations, we propose MedChat, a multi-agent diagnostic framework and platform that combines specialized vision models with multiple role-specific LLM agents, all coordinated by a director agent. This design enhances reliability, reduces hallucination risk, and enables interactive diagnostic reporting through an interface tailored for clinical review and educational use. Code available at https://github.com/Purdue-M2/MedChat.
Detecting Multimedia Generated by Large AI Models: A Survey
Feb 07, 2024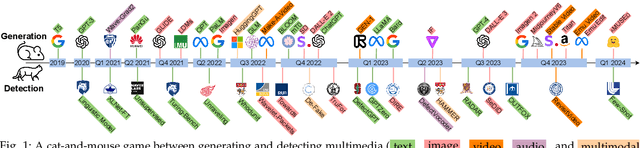
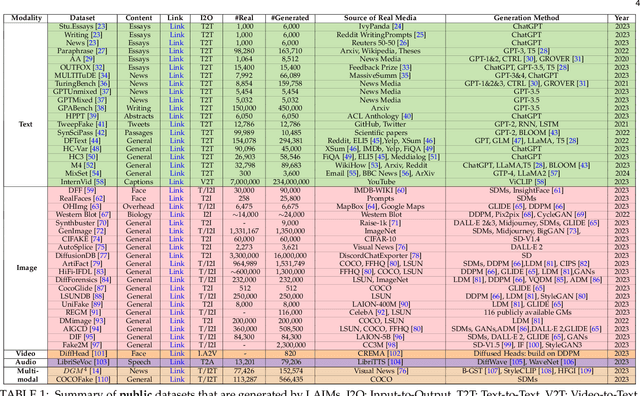
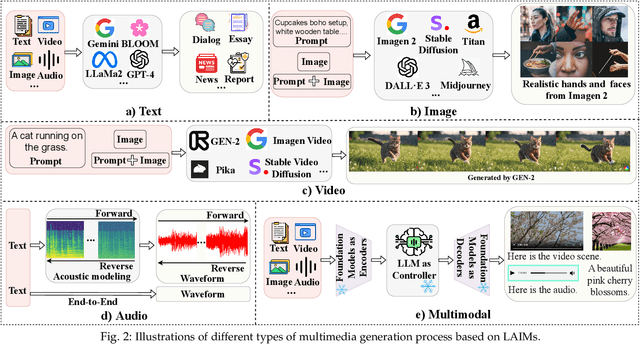
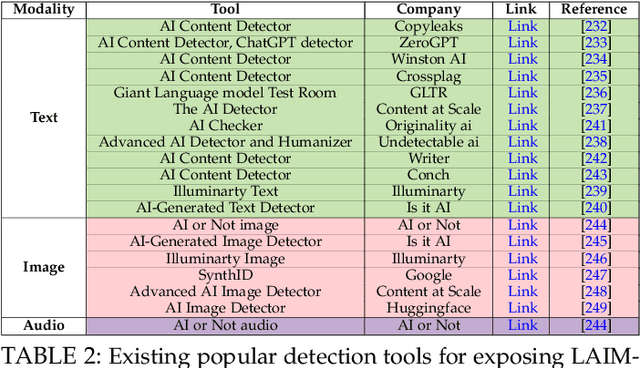
The rapid advancement of Large AI Models (LAIMs), particularly diffusion models and large language models, has marked a new era where AI-generated multimedia is increasingly integrated into various aspects of daily life. Although beneficial in numerous fields, this content presents significant risks, including potential misuse, societal disruptions, and ethical concerns. Consequently, detecting multimedia generated by LAIMs has become crucial, with a marked rise in related research. Despite this, there remains a notable gap in systematic surveys that focus specifically on detecting LAIM-generated multimedia. Addressing this, we provide the first survey to comprehensively cover existing research on detecting multimedia (such as text, images, videos, audio, and multimodal content) created by LAIMs. Specifically, we introduce a novel taxonomy for detection methods, categorized by media modality, and aligned with two perspectives: pure detection (aiming to enhance detection performance) and beyond detection (adding attributes like generalizability, robustness, and interpretability to detectors). Additionally, we have presented a brief overview of generation mechanisms, public datasets, and online detection tools to provide a valuable resource for researchers and practitioners in this field. Furthermore, we identify current challenges in detection and propose directions for future research that address unexplored, ongoing, and emerging issues in detecting multimedia generated by LAIMs. Our aim for this survey is to fill an academic gap and contribute to global AI security efforts, helping to ensure the integrity of information in the digital realm. The project link is https://github.com/Purdue-M2/Detect-LAIM-generated-Multimedia-Survey.
FREGAN : an application of generative adversarial networks in enhancing the frame rate of videos
Nov 01, 2021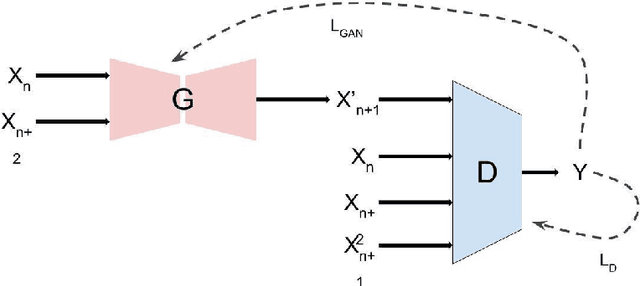

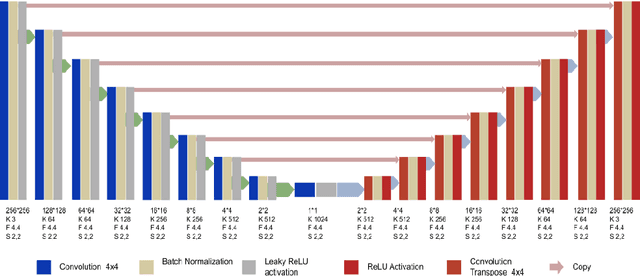
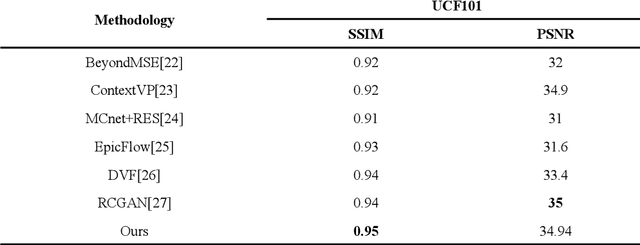
A digital video is a collection of individual frames, while streaming the video the scene utilized the time slice for each frame. High refresh rate and high frame rate is the demand of all high technology applications. The action tracking in videos becomes easier and motion becomes smoother in gaming applications due to the high refresh rate. It provides a faster response because of less time in between each frame that is displayed on the screen. FREGAN (Frame Rate Enhancement Generative Adversarial Network) model has been proposed, which predicts future frames of a video sequence based on a sequence of past frames. In this paper, we investigated the GAN model and proposed FREGAN for the enhancement of frame rate in videos. We have utilized Huber loss as a loss function in the proposed FREGAN. It provided excellent results in super-resolution and we have tried to reciprocate that performance in the application of frame rate enhancement. We have validated the effectiveness of the proposed model on the standard datasets (UCF101 and RFree500). The experimental outcomes illustrate that the proposed model has a Peak signal-to-noise ratio (PSNR) of 34.94 and a Structural Similarity Index (SSIM) of 0.95.
A Probabilistic Transmission Expansion Planning Methodology based on Roulette Wheel Selection and Social Welfare
Mar 12, 2012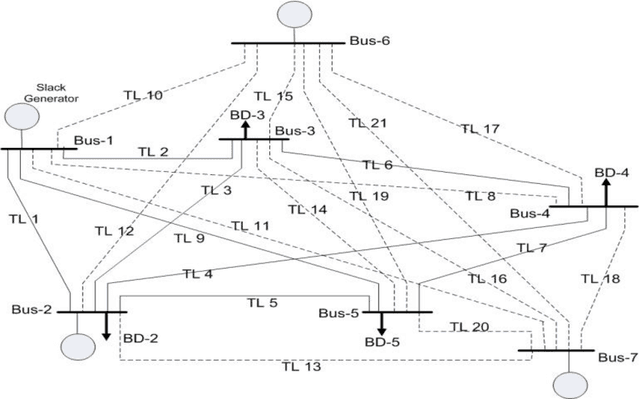
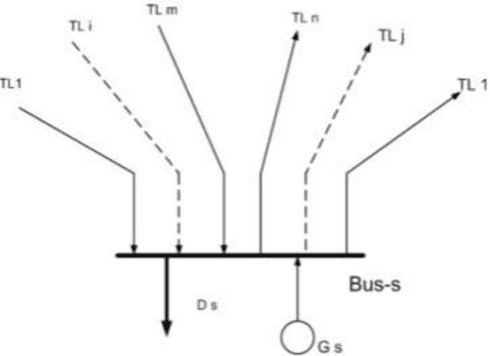
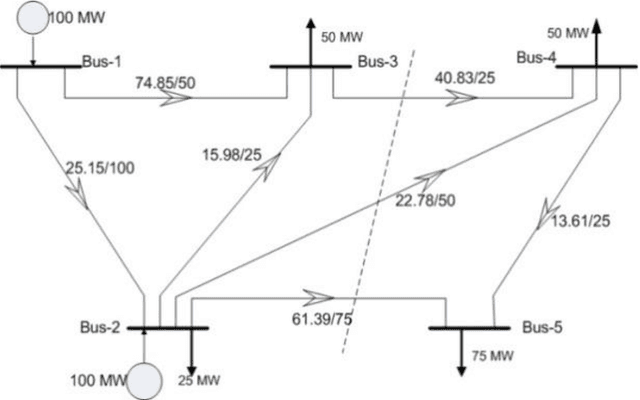
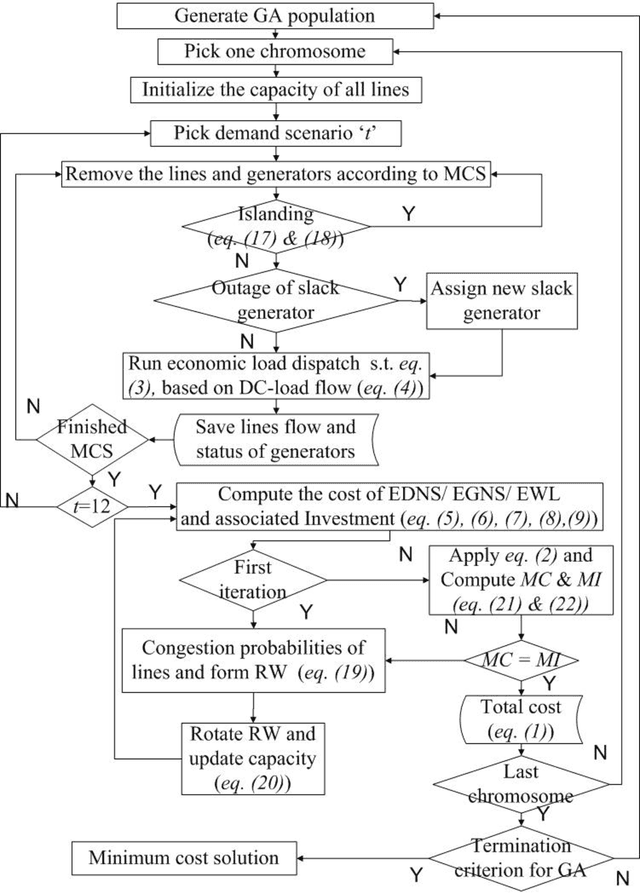
A new probabilistic methodology for transmission expansion planning (TEP) that does not require a priori specification of new/additional transmission capacities and uses the concept of social welfare has been proposed. Two new concepts have been introduced in this paper: (i) roulette wheel methodology has been used to calculate the capacity of new transmission lines and (ii) load flow analysis has been used to calculate expected demand not served (EDNS). The overall methodology has been implemented on a modified IEEE 5-bus test system. Simulations show an important result: addition of only new transmission lines is not sufficient to minimize EDNS.