 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization for AI-Synthesized Voice Detection
Dec 26, 2024AI-synthesized voice technology has the potential to create realistic human voices for beneficial applications, but it can also be misused for malicious purposes. While existing AI-synthesized voice detection models excel in intra-domain evaluation, they face challenges in generalizing across different domains, potentially becoming obsolete as new voice generators emerge. Current solutions use diverse data and advanced machine learning techniques (e.g., domain-invariant representation, self-supervised learning), but are limited by predefined vocoders and sensitivity to factors like background noise and speaker identity. In this work, we introduce an innovative disentanglement framework aimed at extracting domain-agnostic artifact features related to vocoders. Utilizing these features, we enhance model learning in a flat loss landscape, enabling escape from suboptimal solutions and improving generalization. Extensive experiments on benchmarks show our approach outperforms state-of-the-art methods, achieving up to 5.12% improvement in the equal error rate metric in intra-domain and 7.59% in cross-domain evaluations.
PaPr: Training-Free One-Step Patch Pruning with Lightweight ConvNets for Faster Inference
Mar 24, 2024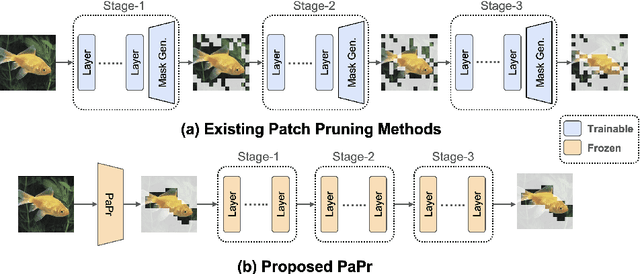
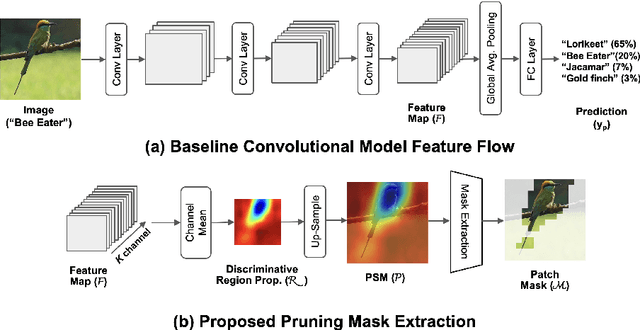
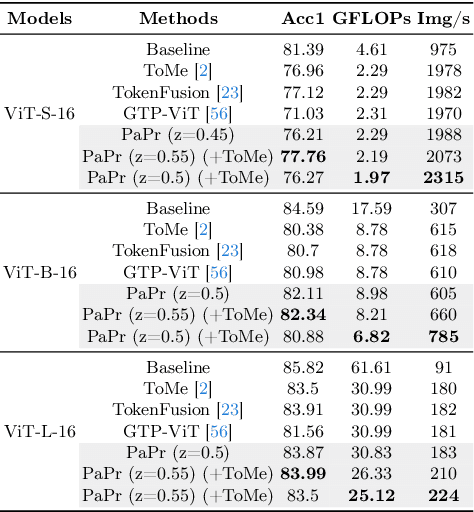
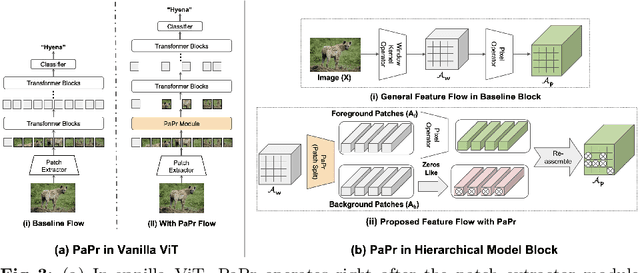
As deep neural networks evolve from convolutional neural networks (ConvNets) to advanced vision transformers (ViTs), there is an increased need to eliminate redundant data for faster processing without compromising accuracy. Previous methods are often architecture-specific or necessitate re-training, restricting their applicability with frequent model updates. To solve this, we first introduce a novel property of lightweight ConvNets: their ability to identify key discriminative patch regions in images, irrespective of model's final accuracy or size. We demonstrate that fully-connected layers are the primary bottleneck for ConvNets performance, and their suppression with simple weight recalibration markedly enhances discriminative patch localization performance. Using this insight, we introduce PaPr, a method for substantially pruning redundant patches with minimal accuracy loss using lightweight ConvNets across a variety of deep learning architectures, including ViTs, ConvNets, and hybrid transformers, without any re-training. Moreover, the simple early-stage one-step patch pruning with PaPr enhances existing patch reduction methods. Through extensive testing on diverse architectures, PaPr achieves significantly higher accuracy over state-of-the-art patch reduction methods with similar FLOP count reduction. More specifically, PaPr reduces about 70% of redundant patches in videos with less than 0.8% drop in accuracy, and up to 3.7x FLOPs reduction, which is a 15% more reduction with 2.5% higher accuracy.
Detecting Multimedia Generated by Large AI Models: A Survey
Feb 07, 2024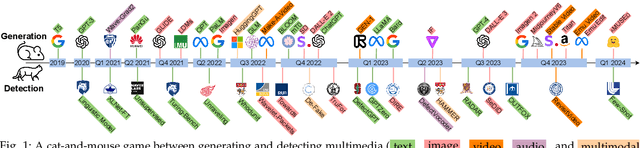
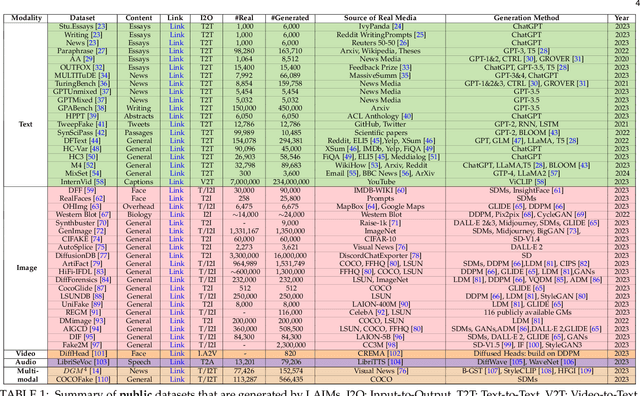
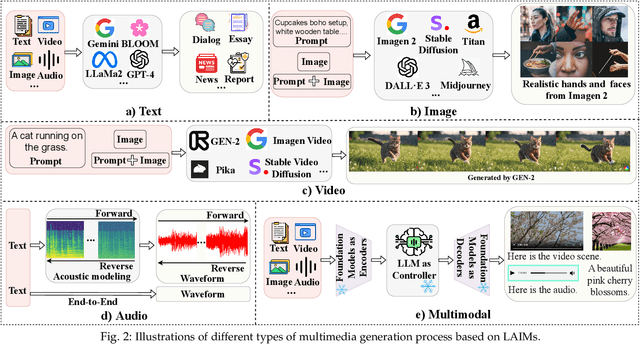
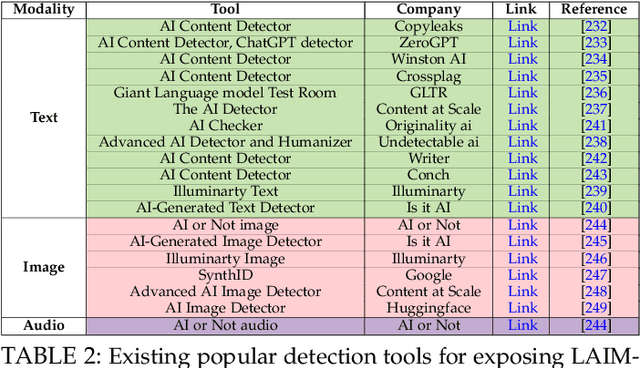
The rapid advancement of Large AI Models (LAIMs), particularly diffusion models and large language models, has marked a new era where AI-generated multimedia is increasingly integrated into various aspects of daily life. Although beneficial in numerous fields, this content presents significant risks, including potential misuse, societal disruptions, and ethical concerns. Consequently, detecting multimedia generated by LAIMs has become crucial, with a marked rise in related research. Despite this, there remains a notable gap in systematic surveys that focus specifically on detecting LAIM-generated multimedia. Addressing this, we provide the first survey to comprehensively cover existing research on detecting multimedia (such as text, images, videos, audio, and multimodal content) created by LAIMs. Specifically, we introduce a novel taxonomy for detection methods, categorized by media modality, and aligned with two perspectives: pure detection (aiming to enhance detection performance) and beyond detection (adding attributes like generalizability, robustness, and interpretability to detectors). Additionally, we have presented a brief overview of generation mechanisms, public datasets, and online detection tools to provide a valuable resource for researchers and practitioners in this field. Furthermore, we identify current challenges in detection and propose directions for future research that address unexplored, ongoing, and emerging issues in detecting multimedia generated by LAIMs. Our aim for this survey is to fill an academic gap and contribute to global AI security efforts, helping to ensure the integrity of information in the digital realm. The project link is https://github.com/Purdue-M2/Detect-LAIM-generated-Multimedia-Survey.
SSVOD: Semi-Supervised Video Object Detection with Sparse Annotations
Sep 04, 2023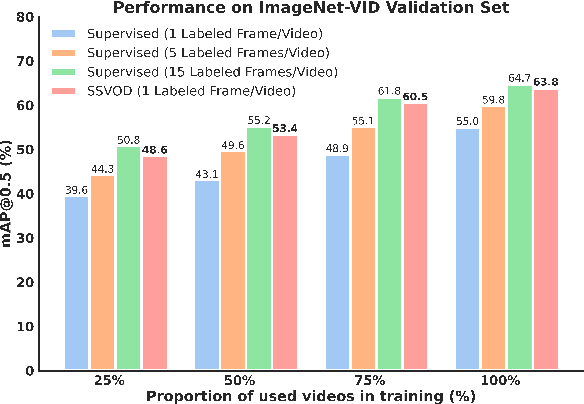
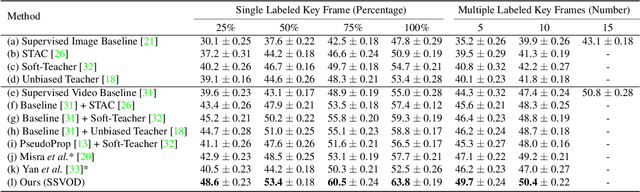
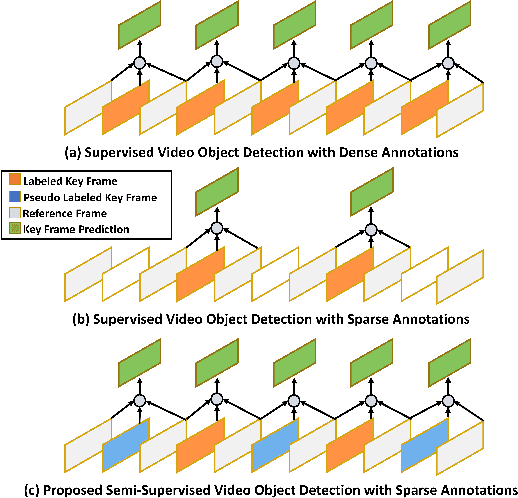
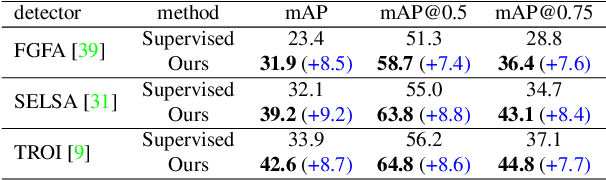
Despite significant progress in semi-supervised learning for image object detection, several key issues are yet to be addressed for video object detection: (1) Achieving good performance for supervised video object detection greatly depends on the availability of annotated frames. (2) Despite having large inter-frame correlations in a video, collecting annotations for a large number of frames per video is expensive, time-consuming, and often redundant. (3) Existing semi-supervised techniques on static images can hardly exploit the temporal motion dynamics inherently present in videos. In this paper, we introduce SSVOD, an end-to-end semi-supervised video object detection framework that exploits motion dynamics of videos to utilize large-scale unlabeled frames with sparse annotations. To selectively assemble robust pseudo-labels across groups of frames, we introduce \textit{flow-warped predictions} from nearby frames for temporal-consistency estimation. In particular, we introduce cross-IoU and cross-divergence based selection methods over a set of estimated predictions to include robust pseudo-labels for bounding boxes and class labels, respectively. To strike a balance between confirmation bias and uncertainty noise in pseudo-labels, we propose confidence threshold based combination of hard and soft pseudo-labels. Our method achieves significant performance improvements over existing methods on ImageNet-VID, Epic-KITCHENS, and YouTube-VIS datasets. Code and pre-trained models will be released.
Instance-Aware Repeat Factor Sampling for Long-Tailed Object Detection
May 14, 2023We propose an embarrassingly simple method -- instance-aware repeat factor sampling (IRFS) to address the problem of imbalanced data in long-tailed object detection. Imbalanced datasets in real-world object detection often suffer from a large disparity in the number of instances for each class. To improve the generalization performance of object detection models on rare classes, various data sampling techniques have been proposed. Repeat factor sampling (RFS) has shown promise due to its simplicity and effectiveness. Despite its efficiency, RFS completely neglects the instance counts and solely relies on the image count during re-sampling process. However, instance count may immensely vary for different classes with similar image counts. Such variation highlights the importance of both image and instance for addressing the long-tail distributions. Thus, we propose IRFS which unifies instance and image counts for the re-sampling process to be aware of different perspectives of the imbalance in long-tailed datasets. Our method shows promising results on the challenging LVIS v1.0 benchmark dataset over various architectures and backbones, demonstrating their effectiveness in improving the performance of object detection models on rare classes with a relative $+50\%$ average precision (AP) improvement over counterpart RFS. IRFS can serve as a strong baseline and be easily incorporated into existing long-tailed frameworks.
Object Detection for Autonomous Dozers
Aug 17, 2022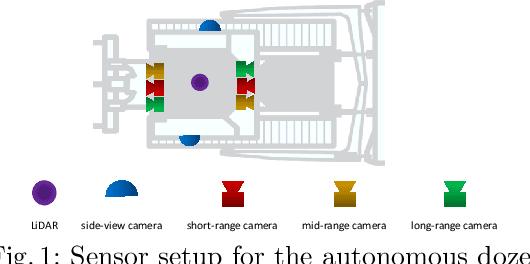

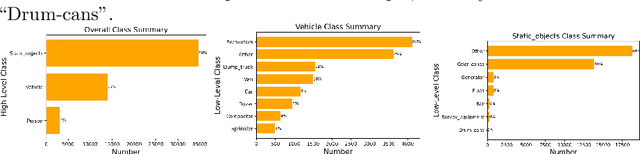
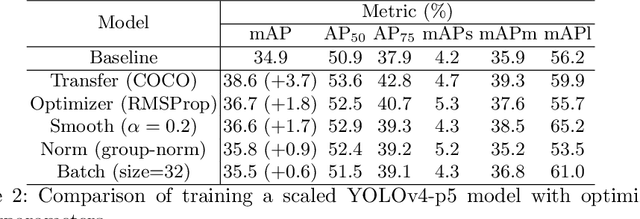
We introduce a new type of autonomous vehicle - an autonomous dozer that is expected to complete construction site tasks in an efficient, robust, and safe manner. To better handle the path planning for the dozer and ensure construction site safety, object detection plays one of the most critical components among perception tasks. In this work, we first collect the construction site data by driving around our dozers. Then we analyze the data thoroughly to understand its distribution. Finally, two well-known object detection models are trained, and their performances are benchmarked with a wide range of training strategies and hyperparameters.
PseudoProp: Robust Pseudo-Label Generation for Semi-Supervised Object Detection in Autonomous Driving Systems
Mar 11, 2022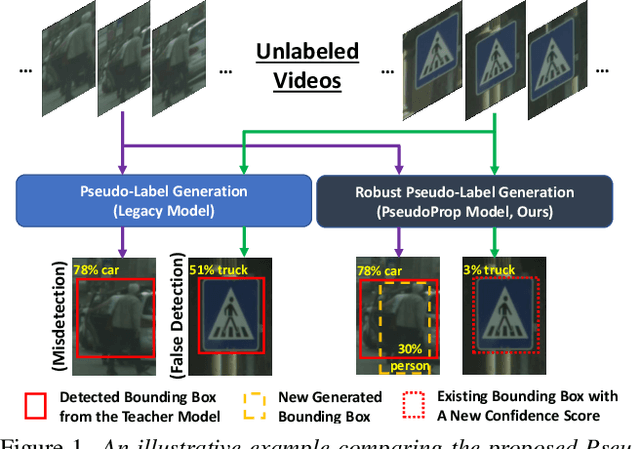
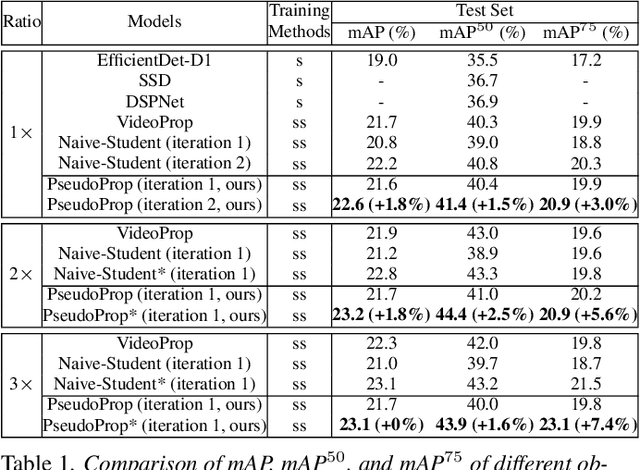
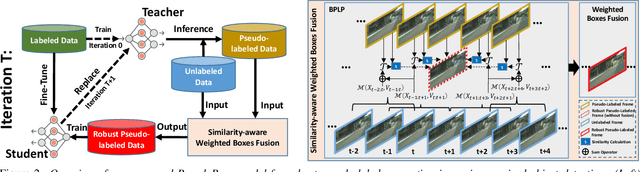
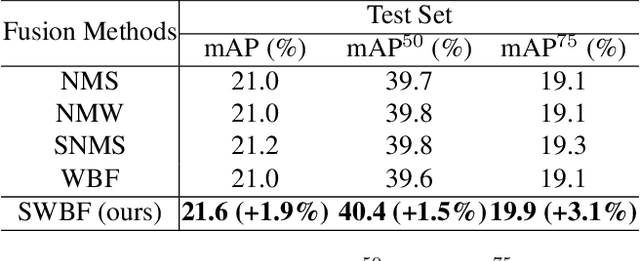
Semi-supervised object detection methods are widely used in autonomous driving systems, where only a fraction of objects are labeled. To propagate information from the labeled objects to the unlabeled ones, pseudo-labels for unlabeled objects must be generated. Although pseudo-labels have proven to improve the performance of semi-supervised object detection significantly, the applications of image-based methods to video frames result in numerous miss or false detections using such generated pseudo-labels. In this paper, we propose a new approach, PseudoProp, to generate robust pseudo-labels by leveraging motion continuity in video frames. Specifically, PseudoProp uses a novel bidirectional pseudo-label propagation approach to compensate for misdetection. A feature-based fusion technique is also used to suppress inference noise. Extensive experiments on the large-scale Cityscapes dataset demonstrate that our method outperforms the state-of-the-art semi-supervised object detection methods by 7.4% on mAP75.
Complement Objective Training
Mar 21, 2019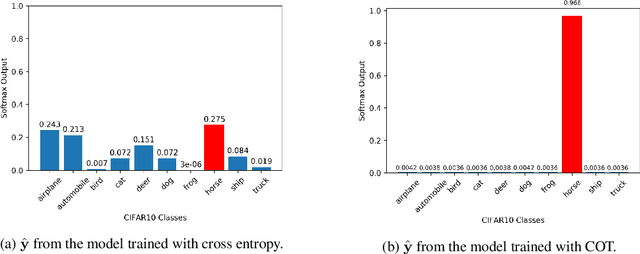
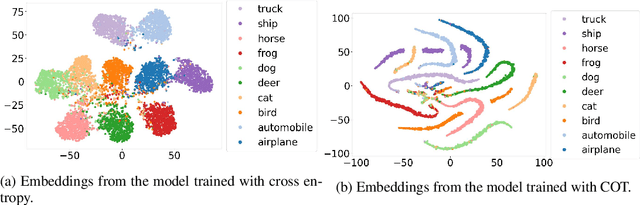
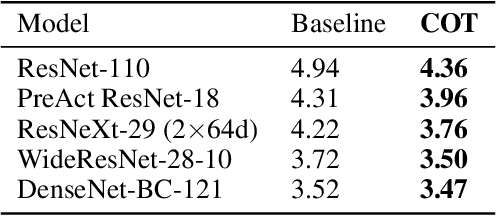

Learning with a primary objective, such as softmax cross entropy for classification and sequence generation, has been the norm for training deep neural networks for years. Although being a widely-adopted approach, using cross entropy as the primary objective exploits mostly the information from the ground-truth class for maximizing data likelihood, and largely ignores information from the complement (incorrect) classes. We argue that, in addition to the primary objective, training also using a complement objective that leverages information from the complement classes can be effective in improving model performance. This motivates us to study a new training paradigm that maximizes the likelihood of the groundtruth class while neutralizing the probabilities of the complement classes. We conduct extensive experiments on multiple tasks ranging from computer vision to natural language understanding. The experimental results confirm that, compared to the conventional training with just one primary objective, training also with the complement objective further improves the performance of the state-of-the-art models across all tasks. In addition to the accuracy improvement, we also show that models trained with both primary and complement objectives are more robust to single-step adversarial attacks.