 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Temperature for Language Modeling
Dec 25, 2020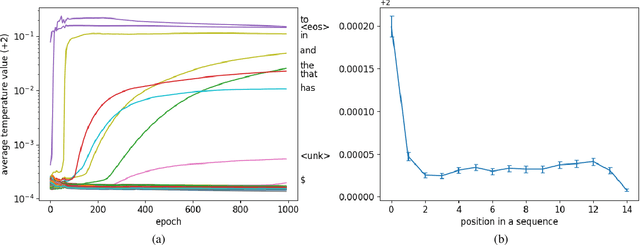
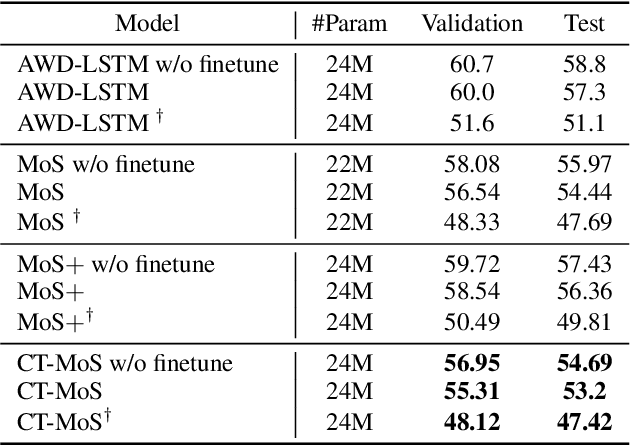
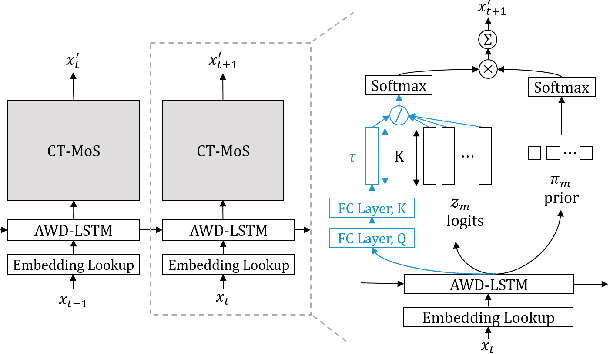
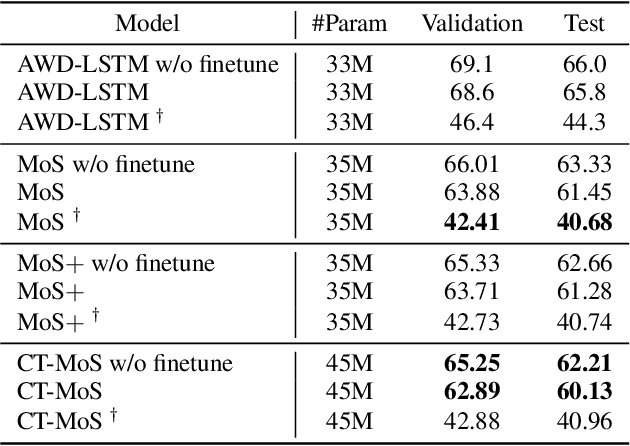
Temperature scaling has been widely used as an effective approach to control the smoothness of a distribution, which helps the model performance in various tasks. Current practices to apply temperature scaling assume either a fixed, or a manually-crafted dynamically changing schedule. However, our studies indicate that the individual optimal trajectory for each class can change with the context. To this end, we propose contextual temperature, a generalized approach that learns an optimal temperature trajectory for each vocabulary over the context. Experimental results confirm that the proposed method significantly improves state-of-the-art language models, achieving a perplexity of 55.31 and 62.89 on the test set of Penn Treebank and WikiText-2, respectively. In-depth analyses show that the behaviour of the learned temperature schedules varies dramatically by vocabulary, and that the optimal schedules help in controlling the uncertainties. These evidences further justify the need for the proposed method and its advantages over fixed temperature schedules.
Complement Objective Training
Mar 21, 2019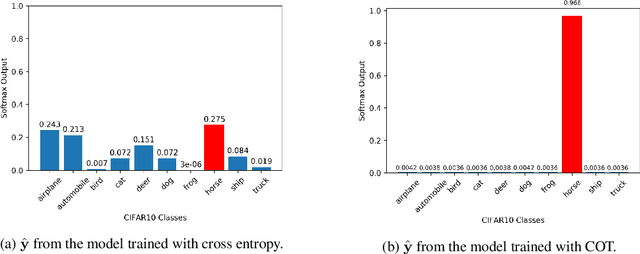
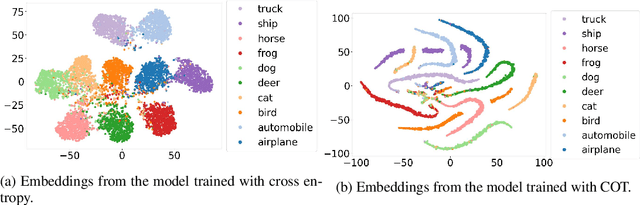
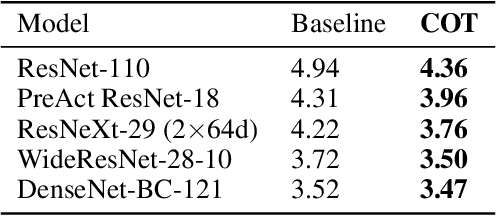

Learning with a primary objective, such as softmax cross entropy for classification and sequence generation, has been the norm for training deep neural networks for years. Although being a widely-adopted approach, using cross entropy as the primary objective exploits mostly the information from the ground-truth class for maximizing data likelihood, and largely ignores information from the complement (incorrect) classes. We argue that, in addition to the primary objective, training also using a complement objective that leverages information from the complement classes can be effective in improving model performance. This motivates us to study a new training paradigm that maximizes the likelihood of the groundtruth class while neutralizing the probabilities of the complement classes. We conduct extensive experiments on multiple tasks ranging from computer vision to natural language understanding. The experimental results confirm that, compared to the conventional training with just one primary objective, training also with the complement objective further improves the performance of the state-of-the-art models across all tasks. In addition to the accuracy improvement, we also show that models trained with both primary and complement objectives are more robust to single-step adversarial attacks.