 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Space Search for Pareto-Efficient Spaces
Apr 22, 2021
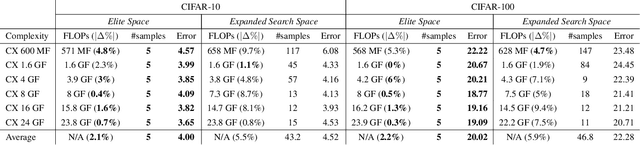


Network spaces have been known as a critical factor in both handcrafted network designs or defining search spaces for Neural Architecture Search (NAS). However, an effective space involves tremendous prior knowledge and/or manual effort, and additional constraints are required to discover efficiency-aware architectures. In this paper, we define a new problem, Network Space Search (NSS), as searching for favorable network spaces instead of a single architecture. We propose an NSS method to directly search for efficient-aware network spaces automatically, reducing the manual effort and immense cost in discovering satisfactory ones. The resultant network spaces, named Elite Spaces, are discovered from Expanded Search Space with minimal human expertise imposed. The Pareto-efficient Elite Spaces are aligned with the Pareto front under various complexity constraints and can be further served as NAS search spaces, benefiting differentiable NAS approaches (e.g. In CIFAR-100, an averagely 2.3% lower error rate and 3.7% closer to target constraint than the baseline with around 90% fewer samples required to find satisfactory networks). Moreover, our NSS approach is capable of searching for superior spaces in future unexplored spaces, revealing great potential in searching for network spaces automatically.
Learning with Hierarchical Complement Objective
Nov 17, 2019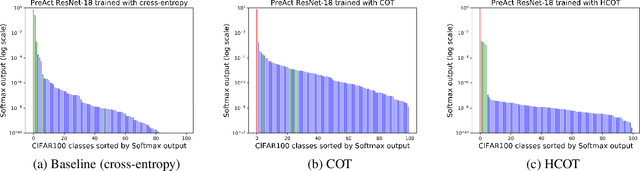
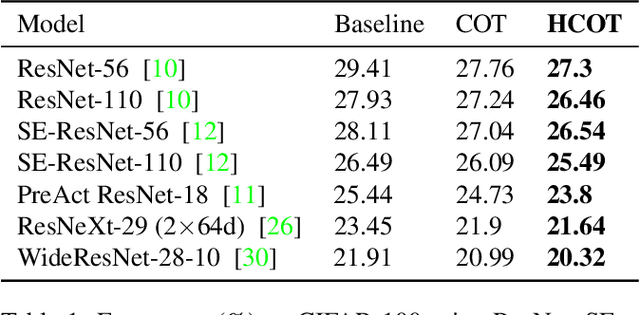
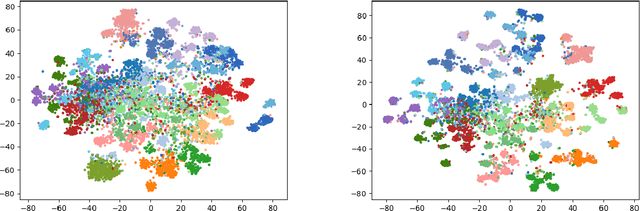
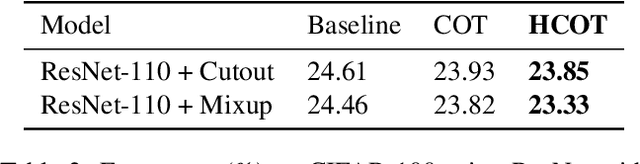
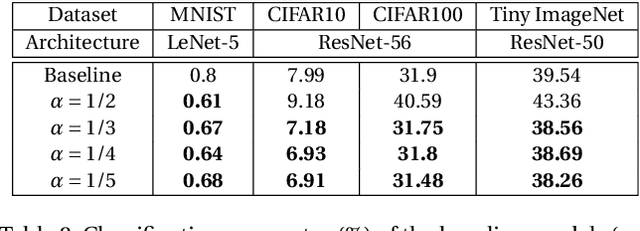
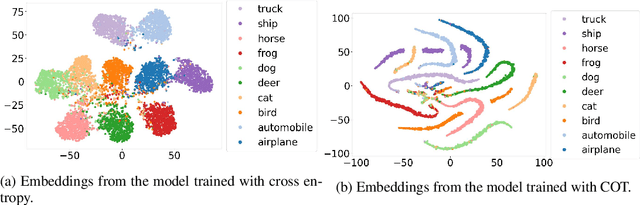
Label hierarchies widely exist in many vision-related problems, ranging from explicit label hierarchies existed in image classification to latent label hierarchies existed in semantic segmentation. Nevertheless, state-of-the-art methods often deploy cross-entropy loss that implicitly assumes class labels to be exclusive and thus independence from each other. Motivated by the fact that classes from the same parental category usually share certain similarity, we design a new training diagram called Hierarchical Complement Objective Training (HCOT) that leverages the information from label hierarchy. HCOT maximizes the probability of the ground truth class, and at the same time, neutralizes the probabilities of rest of the classes in a hierarchical fashion, making the model take advantage of the label hierarchy explicitly. The proposed HCOT is evaluated on both image classification and semantic segmentation tasks. Experimental results confirm that HCOT outperforms state-of-the-art models in CIFAR-100, ImageNet-2012, and PASCAL-Context. The study further demonstrates that HCOT can be applied on tasks with latent label hierarchies, which is a common characteristic in many machine learning tasks.
Improving Adversarial Robustness via Guided Complement Entropy
Mar 23, 2019


Model robustness has been an important issue, since adding small adversarial perturbations to images is sufficient to drive the model accuracy down to nearly zero. In this paper, we propose a new training objective "Guided Complement Entropy" (GCE) that has dual desirable effects: (a) neutralizing the predicted probabilities of incorrect classes, and (b) maximizing the predicted probability of the ground-truth class, particularly when (a) is achieved. Training with GCE encourages models to learn latent representations where samples of different classes form distinct clusters, which we argue, improves the model robustness against adversarial perturbations. Furthermore, compared with the state-of-the-arts trained with cross-entropy, same models trained with GCE achieve significant improvements on the robustness against white-box adversarial attacks, both with and without adversarial training. When no attack is present, training with GCE also outperforms cross-entropy in terms of model accuracy.
Complement Objective Training
Mar 21, 2019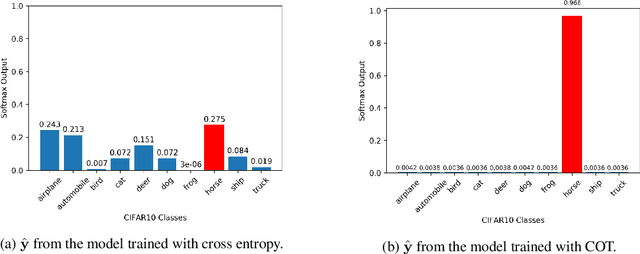
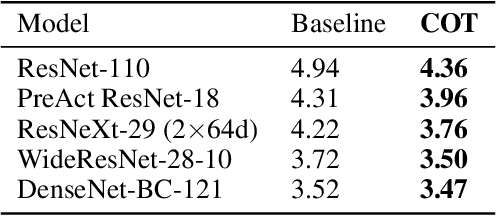

Learning with a primary objective, such as softmax cross entropy for classification and sequence generation, has been the norm for training deep neural networks for years. Although being a widely-adopted approach, using cross entropy as the primary objective exploits mostly the information from the ground-truth class for maximizing data likelihood, and largely ignores information from the complement (incorrect) classes. We argue that, in addition to the primary objective, training also using a complement objective that leverages information from the complement classes can be effective in improving model performance. This motivates us to study a new training paradigm that maximizes the likelihood of the groundtruth class while neutralizing the probabilities of the complement classes. We conduct extensive experiments on multiple tasks ranging from computer vision to natural language understanding. The experimental results confirm that, compared to the conventional training with just one primary objective, training also with the complement objective further improves the performance of the state-of-the-art models across all tasks. In addition to the accuracy improvement, we also show that models trained with both primary and complement objectives are more robust to single-step adversarial attacks.