 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Local Implicit Transformer for Arbitrary-Scale Super-Resolution
Mar 29, 2023Implicit neural representation has recently shown a promising ability in representing images with arbitrary resolutions. In this paper, we present a Local Implicit Transformer (LIT), which integrates the attention mechanism and frequency encoding technique into a local implicit image function. We design a cross-scale local attention block to effectively aggregate local features. To further improve representative power, we propose a Cascaded LIT (CLIT) that exploits multi-scale features, along with a cumulative training strategy that gradually increases the upsampling scales during training. We have conducted extensive experiments to validate the effectiveness of these components and analyze various training strategies. The qualitative and quantitative results demonstrate that LIT and CLIT achieve favorable results and outperform the prior works in arbitrary super-resolution tasks.
Self-Supervised Robustifying Guidance for Monocular 3D Face Reconstruction
Dec 29, 2021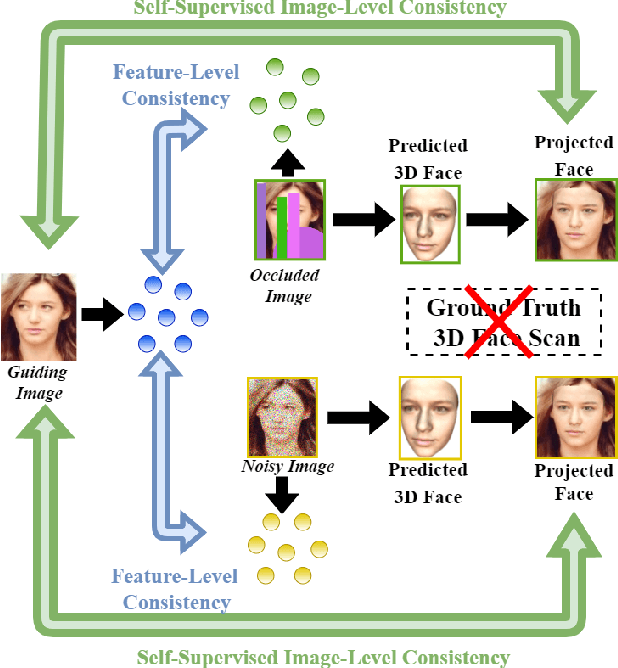
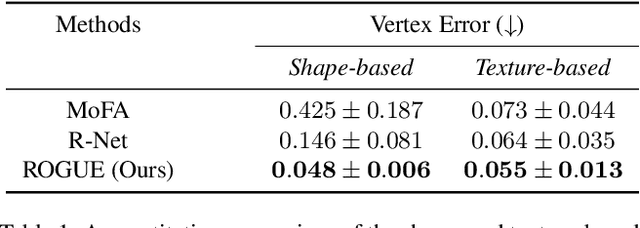
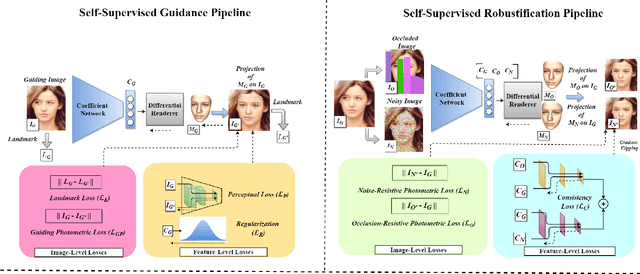
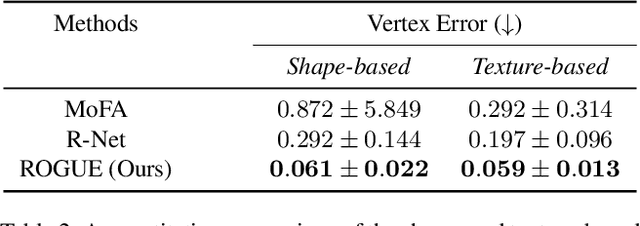
Despite the recent developments in 3D Face Reconstruction from occluded and noisy face images, the performance is still unsatisfactory. One of the main challenges is to handle moderate to heavy occlusions in the face images. In addition, the noise in the face images inhibits the correct capture of facial attributes, thus needing to be reliably addressed. Moreover, most existing methods rely on additional dependencies, posing numerous constraints over the training procedure. Therefore, we propose a Self-Supervised RObustifying GUidancE (ROGUE) framework to obtain robustness against occlusions and noise in the face images. The proposed network contains 1) the Guidance Pipeline to obtain the 3D face coefficients for the clean faces, and 2) the Robustification Pipeline to acquire the consistency between the estimated coefficients for occluded or noisy images and the clean counterpart. The proposed image- and feature-level loss functions aid the ROGUE learning process without posing additional dependencies. On the three variations of the test dataset of CelebA: rational occlusions, delusional occlusions, and noisy face images, our method outperforms the current state-of-the-art method by large margins (e.g., for the shape-based 3D vertex errors, a reduction from 0.146 to 0.048 for rational occlusions, from 0.292 to 0.061 for delusional occlusions and from 0.269 to 0.053 for the noise in the face images), demonstrating the effectiveness of the proposed approach.
Learning to Compensate: A Deep Neural Network Framework for 5G Power Amplifier Compensation
Jun 15, 2021
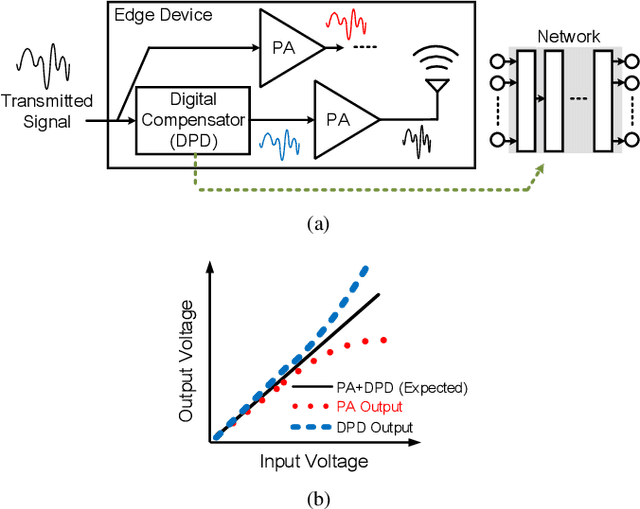


Owing to the complicated characteristics of 5G communication system, designing RF components through mathematical modeling becomes a challenging obstacle. Moreover, such mathematical models need numerous manual adjustments for various specification requirements. In this paper, we present a learning-based framework to model and compensate Power Amplifiers (PAs) in 5G communication. In the proposed framework, Deep Neural Networks (DNNs) are used to learn the characteristics of the PAs, while, correspondent Digital Pre-Distortions (DPDs) are also learned to compensate for the nonlinear and memory effects of PAs. On top of the framework, we further propose two frequency domain losses to guide the learning process to better optimize the target, compared to naive time domain Mean Square Error (MSE). The proposed framework serves as a drop-in replacement for the conventional approach. The proposed approach achieves an average of 56.7% reduction of nonlinear and memory effects, which converts to an average of 16.3% improvement over a carefully-designed mathematical model, and even reaches 34% enhancement in severe distortion scenarios.
Network Space Search for Pareto-Efficient Spaces
Apr 22, 2021
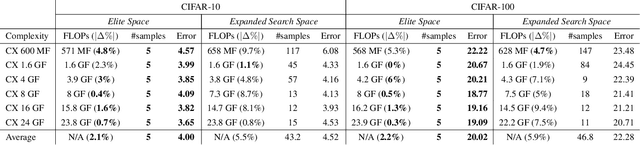


Network spaces have been known as a critical factor in both handcrafted network designs or defining search spaces for Neural Architecture Search (NAS). However, an effective space involves tremendous prior knowledge and/or manual effort, and additional constraints are required to discover efficiency-aware architectures. In this paper, we define a new problem, Network Space Search (NSS), as searching for favorable network spaces instead of a single architecture. We propose an NSS method to directly search for efficient-aware network spaces automatically, reducing the manual effort and immense cost in discovering satisfactory ones. The resultant network spaces, named Elite Spaces, are discovered from Expanded Search Space with minimal human expertise imposed. The Pareto-efficient Elite Spaces are aligned with the Pareto front under various complexity constraints and can be further served as NAS search spaces, benefiting differentiable NAS approaches (e.g. In CIFAR-100, an averagely 2.3% lower error rate and 3.7% closer to target constraint than the baseline with around 90% fewer samples required to find satisfactory networks). Moreover, our NSS approach is capable of searching for superior spaces in future unexplored spaces, revealing great potential in searching for network spaces automatically.
Deploying Image Deblurring across Mobile Devices: A Perspective of Quality and Latency
Apr 27, 2020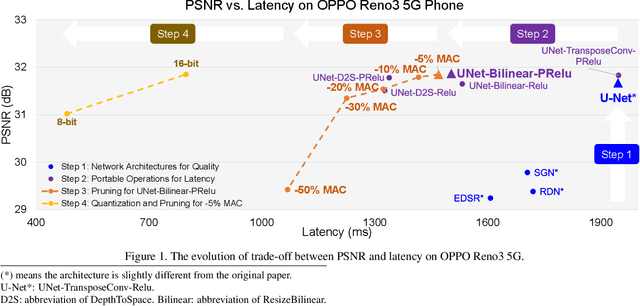
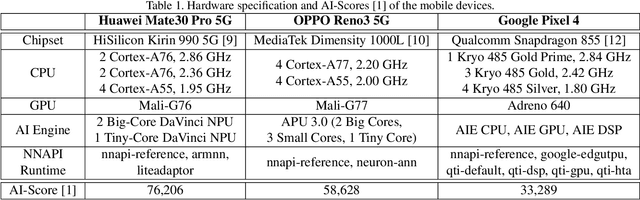
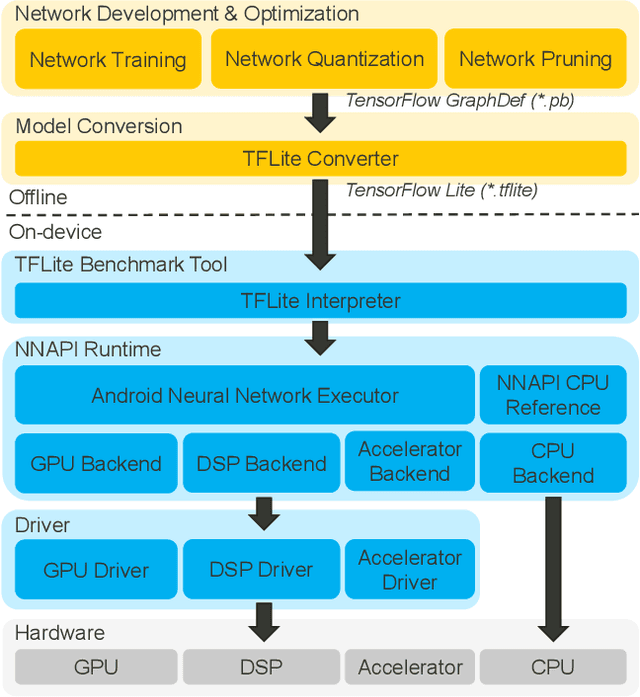
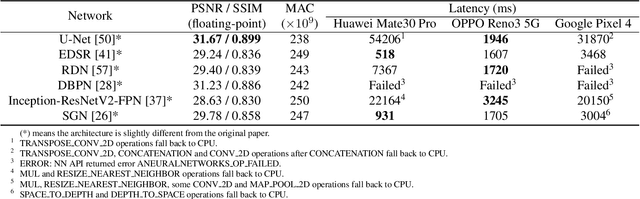
Recently, image enhancement and restoration have become important applications on mobile devices, such as super-resolution and image deblurring. However, most state-of-the-art networks present extremely high computational complexity. This makes them difficult to be deployed on mobile devices with acceptable latency. Moreover, when deploying to different mobile devices, there is a large latency variation due to the difference and limitation of deep learning accelerators on mobile devices. In this paper, we conduct a search of portable network architectures for better quality-latency trade-off across mobile devices. We further present the effectiveness of widely used network optimizations for image deblurring task. This paper provides comprehensive experiments and comparisons to uncover the in-depth analysis for both latency and image quality. Through all the above works, we demonstrate the successful deployment of image deblurring application on mobile devices with the acceleration of deep learning accelerators. To the best of our knowledge, this is the first paper that addresses all the deployment issues of image deblurring task across mobile devices. This paper provides practical deployment-guidelines, and is adopted by the championship-winning team in NTIRE 2020 Image Deblurring Challenge on Smartphone Track.
Unified Dynamic Convolutional Network for Super-Resolution with Variational Degradations
Apr 15, 2020

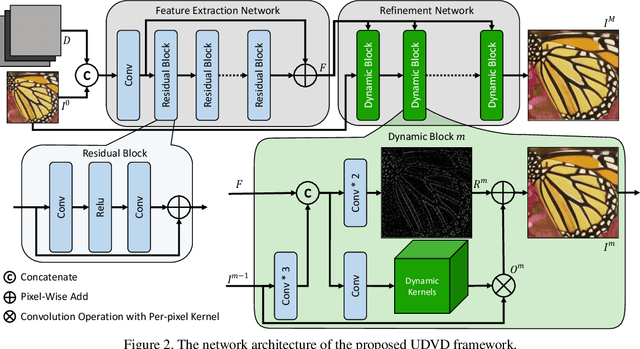
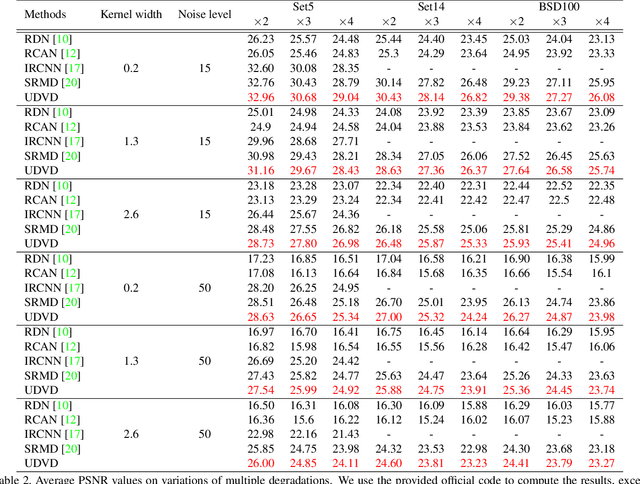
Deep Convolutional Neural Networks (CNNs) have achieved remarkable results on Single Image Super-Resolution (SISR). Despite considering only a single degradation, recent studies also include multiple degrading effects to better reflect real-world cases. However, most of the works assume a fixed combination of degrading effects, or even train an individual network for different combinations. Instead, a more practical approach is to train a single network for wide-ranging and variational degradations. To fulfill this requirement, this paper proposes a unified network to accommodate the variations from inter-image (cross-image variations) and intra-image (spatial variations). Different from the existing works, we incorporate dynamic convolution which is a far more flexible alternative to handle different variations. In SISR with non-blind setting, our Unified Dynamic Convolutional Network for Variational Degradations (UDVD) is evaluated on both synthetic and real images with an extensive set of variations. The qualitative results demonstrate the effectiveness of UDVD over various existing works. Extensive experiments show that our UDVD achieves favorable or comparable performance on both synthetic and real images.
Architecture-aware Network Pruning for Vision Quality Applications
Aug 05, 2019
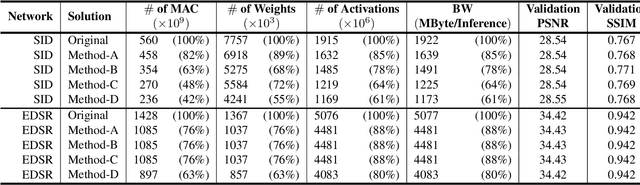
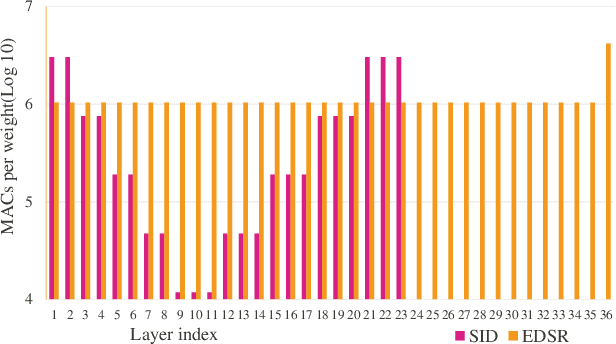
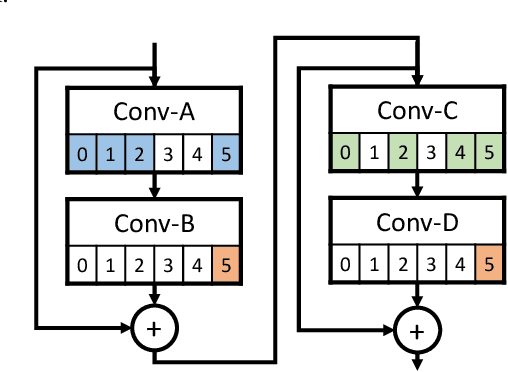
Convolutional neural network (CNN) delivers impressive achievements in computer vision and machine learning field. However, CNN incurs high computational complexity, especially for vision quality applications because of large image resolution. In this paper, we propose an iterative architecture-aware pruning algorithm with adaptive magnitude threshold while cooperating with quality-metric measurement simultaneously. We show the performance improvement applied on vision quality applications and provide comprehensive analysis with flexible pruning configuration. With the proposed method, the Multiply-Accumulate (MAC) of state-of-the-art low-light imaging (SID) and super-resolution (EDSR) are reduced by 58% and 37% without quality drop, respectively. The memory bandwidth (BW) requirements of convolutional layer can be also reduced by 20% to 40%.