 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Walks-Based Adaptive Distribution Generation with Efficient CUDA-Q Acceleration
Apr 18, 2025We present a novel Adaptive Distribution Generator that leverages a quantum walks-based approach to generate high precision and efficiency of target probability distributions. Our method integrates variational quantum circuits with discrete-time quantum walks, specifically, split-step quantum walks and their entangled extensions, to dynamically tune coin parameters and drive the evolution of quantum states towards desired distributions. This enables accurate one-dimensional probability modeling for applications such as financial simulation and structured two-dimensional pattern generation exemplified by digit representations(0~9). Implemented within the CUDA-Q framework, our approach exploits GPU acceleration to significantly reduce computational overhead and improve scalability relative to conventional methods. Extensive benchmarks demonstrate that our Quantum Walks-Based Adaptive Distribution Generator achieves high simulation fidelity and bridges the gap between theoretical quantum algorithms and practical high-performance computation.
Deploying Image Deblurring across Mobile Devices: A Perspective of Quality and Latency
Apr 27, 2020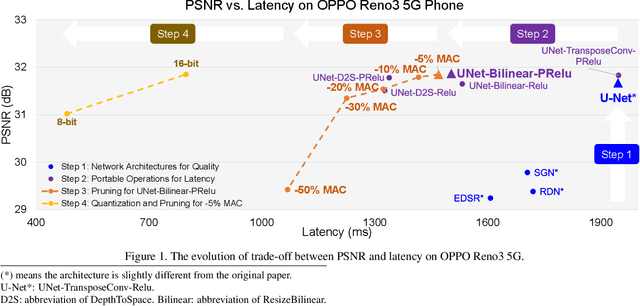
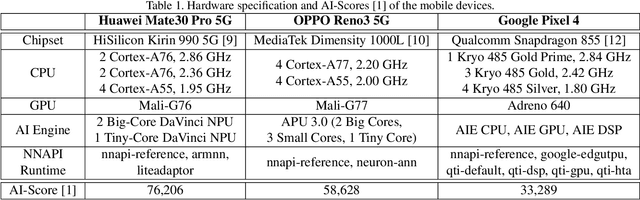
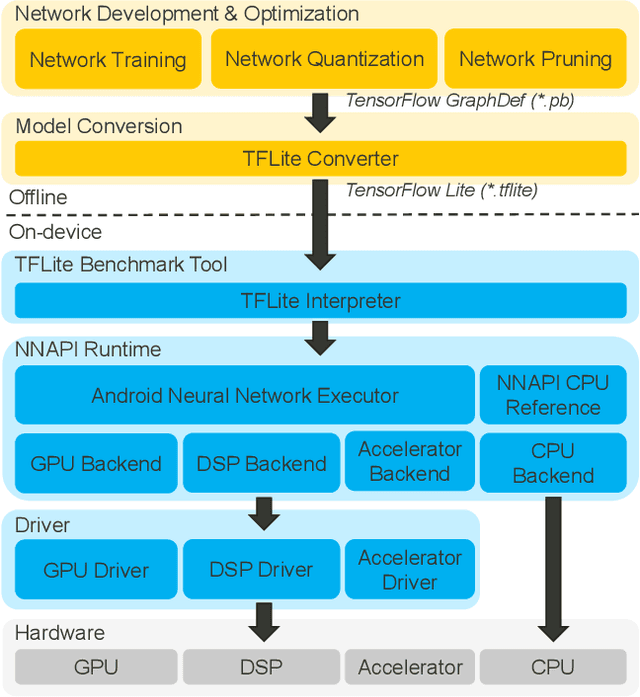
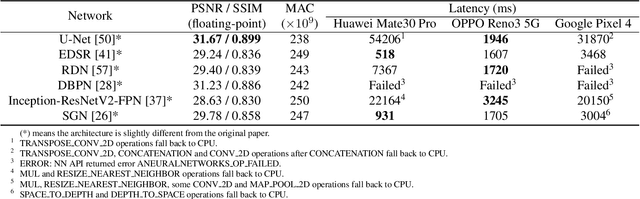
Recently, image enhancement and restoration have become important applications on mobile devices, such as super-resolution and image deblurring. However, most state-of-the-art networks present extremely high computational complexity. This makes them difficult to be deployed on mobile devices with acceptable latency. Moreover, when deploying to different mobile devices, there is a large latency variation due to the difference and limitation of deep learning accelerators on mobile devices. In this paper, we conduct a search of portable network architectures for better quality-latency trade-off across mobile devices. We further present the effectiveness of widely used network optimizations for image deblurring task. This paper provides comprehensive experiments and comparisons to uncover the in-depth analysis for both latency and image quality. Through all the above works, we demonstrate the successful deployment of image deblurring application on mobile devices with the acceleration of deep learning accelerators. To the best of our knowledge, this is the first paper that addresses all the deployment issues of image deblurring task across mobile devices. This paper provides practical deployment-guidelines, and is adopted by the championship-winning team in NTIRE 2020 Image Deblurring Challenge on Smartphone Track.
Architecture-aware Network Pruning for Vision Quality Applications
Aug 05, 2019
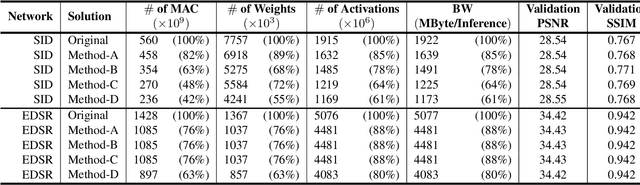
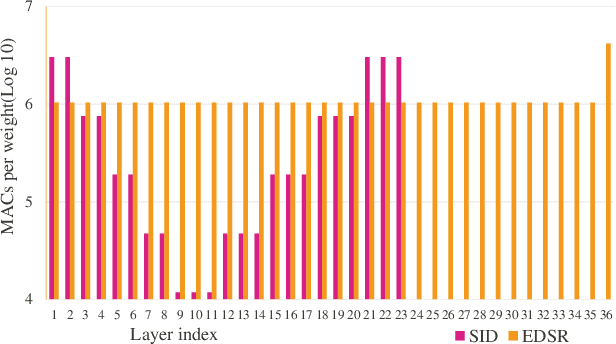
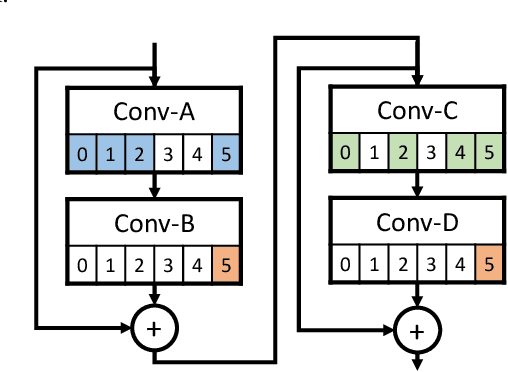
Convolutional neural network (CNN) delivers impressive achievements in computer vision and machine learning field. However, CNN incurs high computational complexity, especially for vision quality applications because of large image resolution. In this paper, we propose an iterative architecture-aware pruning algorithm with adaptive magnitude threshold while cooperating with quality-metric measurement simultaneously. We show the performance improvement applied on vision quality applications and provide comprehensive analysis with flexible pruning configuration. With the proposed method, the Multiply-Accumulate (MAC) of state-of-the-art low-light imaging (SID) and super-resolution (EDSR) are reduced by 58% and 37% without quality drop, respectively. The memory bandwidth (BW) requirements of convolutional layer can be also reduced by 20% to 40%.