 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Guided Attention Head Selection for Focus-Oriented Image Retrieval
Apr 02, 2025The goal of this paper is to enhance pretrained Vision Transformer (ViT) models for focus-oriented image retrieval with visual prompting. In real-world image retrieval scenarios, both query and database images often exhibit complexity, with multiple objects and intricate backgrounds. Users often want to retrieve images with specific object, which we define as the Focus-Oriented Image Retrieval (FOIR) task. While a standard image encoder can be employed to extract image features for similarity matching, it may not perform optimally in the multi-object-based FOIR task. This is because each image is represented by a single global feature vector. To overcome this, a prompt-based image retrieval solution is required. We propose an approach called Prompt-guided attention Head Selection (PHS) to leverage the head-wise potential of the multi-head attention mechanism in ViT in a promptable manner. PHS selects specific attention heads by matching their attention maps with user's visual prompts, such as a point, box, or segmentation. This empowers the model to focus on specific object of interest while preserving the surrounding visual context. Notably, PHS does not necessitate model re-training and avoids any image alteration. Experimental results show that PHS substantially improves performance on multiple datasets, offering a practical and training-free solution to enhance model performance in the FOIR task.
Improving Image Clustering with Artifacts Attenuation via Inference-Time Attention Engineering
Oct 07, 2024



The goal of this paper is to improve the performance of pretrained Vision Transformer (ViT) models, particularly DINOv2, in image clustering task without requiring re-training or fine-tuning. As model size increases, high-norm artifacts anomaly appears in the patches of multi-head attention. We observe that this anomaly leads to reduced accuracy in zero-shot image clustering. These artifacts are characterized by disproportionately large values in the attention map compared to other patch tokens. To address these artifacts, we propose an approach called Inference-Time Attention Engineering (ITAE), which manipulates attention function during inference. Specifically, we identify the artifacts by investigating one of the Query-Key-Value (QKV) patches in the multi-head attention and attenuate their corresponding attention values inside the pretrained models. ITAE shows improved clustering accuracy on multiple datasets by exhibiting more expressive features in latent space. Our findings highlight the potential of ITAE as a practical solution for reducing artifacts in pretrained ViT models and improving model performance in clustering tasks without the need for re-training or fine-tuning.
Revisiting Relevance Feedback for CLIP-based Interactive Image Retrieval
Apr 29, 2024Many image retrieval studies use metric learning to train an image encoder. However, metric learning cannot handle differences in users' preferences, and requires data to train an image encoder. To overcome these limitations, we revisit relevance feedback, a classic technique for interactive retrieval systems, and propose an interactive CLIP-based image retrieval system with relevance feedback. Our retrieval system first executes the retrieval, collects each user's unique preferences through binary feedback, and returns images the user prefers. Even when users have various preferences, our retrieval system learns each user's preference through the feedback and adapts to the preference. Moreover, our retrieval system leverages CLIP's zero-shot transferability and achieves high accuracy without training. We empirically show that our retrieval system competes well with state-of-the-art metric learning in category-based image retrieval, despite not training image encoders specifically for each dataset. Furthermore, we set up two additional experimental settings where users have various preferences: one-label-based image retrieval and conditioned image retrieval. In both cases, our retrieval system effectively adapts to each user's preferences, resulting in improved accuracy compared to image retrieval without feedback. Overall, our work highlights the potential benefits of integrating CLIP with classic relevance feedback techniques to enhance image retrieval.
Revisiting a kNN-based Image Classification System with High-capacity Storage
Apr 03, 2022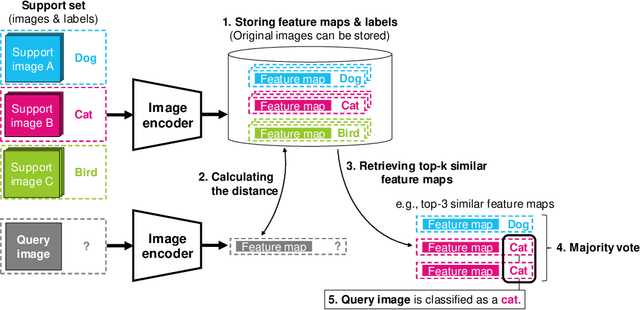



In existing image classification systems that use deep neural networks, the knowledge needed for image classification is implicitly stored in model parameters. If users want to update this knowledge, then they need to fine-tune the model parameters. Moreover, users cannot verify the validity of inference results or evaluate the contribution of knowledge to the results. In this paper, we investigate a system that stores knowledge for image classification, such as image feature maps, labels, and original images, not in model parameters but in external high-capacity storage. Our system refers to the storage like a database when classifying input images. To increase knowledge, our system updates the database instead of fine-tuning model parameters, which avoids catastrophic forgetting in incremental learning scenarios. We revisit a kNN (k-Nearest Neighbor) classifier and employ it in our system. By analyzing the neighborhood samples referred by the kNN algorithm, we can interpret how knowledge learned in the past is used for inference results. Our system achieves 79.8% top-1 accuracy on the ImageNet dataset without fine-tuning model parameters after pretraining, and 90.8% accuracy on the Split CIFAR-100 dataset in the task incremental learning setting.
Deploying Image Deblurring across Mobile Devices: A Perspective of Quality and Latency
Apr 27, 2020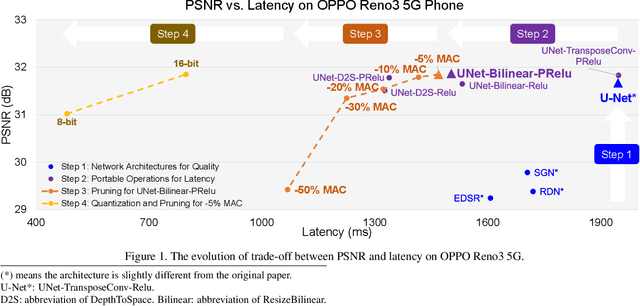
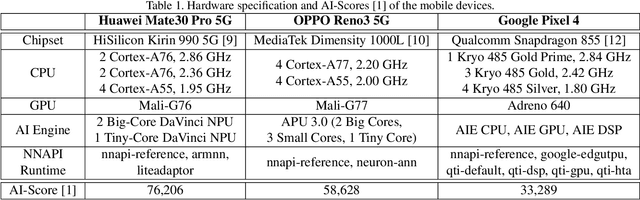
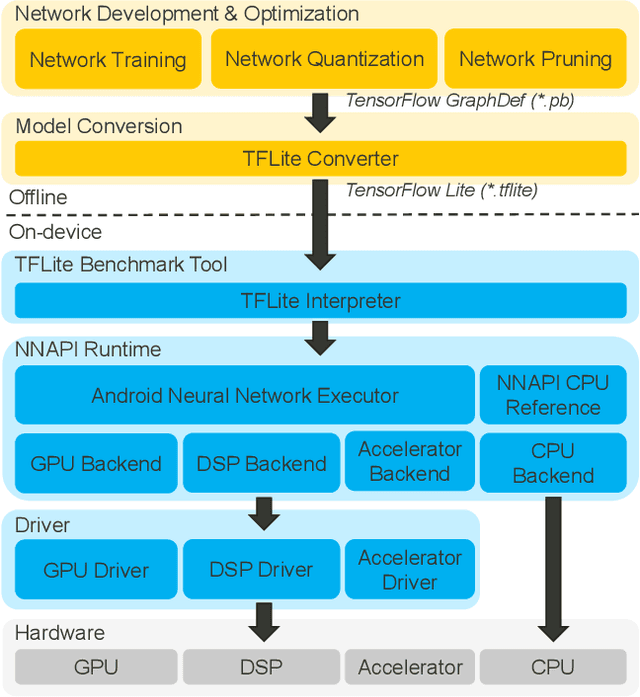
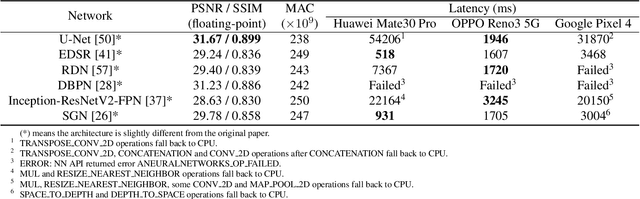
Recently, image enhancement and restoration have become important applications on mobile devices, such as super-resolution and image deblurring. However, most state-of-the-art networks present extremely high computational complexity. This makes them difficult to be deployed on mobile devices with acceptable latency. Moreover, when deploying to different mobile devices, there is a large latency variation due to the difference and limitation of deep learning accelerators on mobile devices. In this paper, we conduct a search of portable network architectures for better quality-latency trade-off across mobile devices. We further present the effectiveness of widely used network optimizations for image deblurring task. This paper provides comprehensive experiments and comparisons to uncover the in-depth analysis for both latency and image quality. Through all the above works, we demonstrate the successful deployment of image deblurring application on mobile devices with the acceleration of deep learning accelerators. To the best of our knowledge, this is the first paper that addresses all the deployment issues of image deblurring task across mobile devices. This paper provides practical deployment-guidelines, and is adopted by the championship-winning team in NTIRE 2020 Image Deblurring Challenge on Smartphone Track.