 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Sparse Lexical Representations for Image Retrieval in the Age of Rising Multi-Modal Large Language Models
Aug 29, 2024
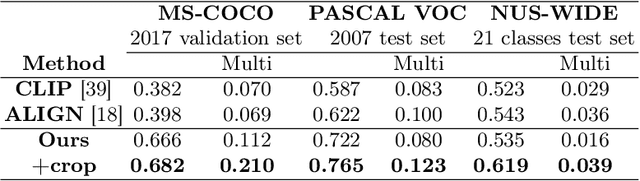


In this paper, we rethink sparse lexical representations for image retrieval. By utilizing multi-modal large language models (M-LLMs) that support visual prompting, we can extract image features and convert them into textual data, enabling us to utilize efficient sparse retrieval algorithms employed in natural language processing for image retrieval tasks. To assist the LLM in extracting image features, we apply data augmentation techniques for key expansion and analyze the impact with a metric for relevance between images and textual data. We empirically show the superior precision and recall performance of our image retrieval method compared to conventional vision-language model-based methods on the MS-COCO, PASCAL VOC, and NUS-WIDE datasets in a keyword-based image retrieval scenario, where keywords serve as search queries. We also demonstrate that the retrieval performance can be improved by iteratively incorporating keywords into search queries.
AiSAQ: All-in-Storage ANNS with Product Quantization for DRAM-free Information Retrieval
Apr 09, 2024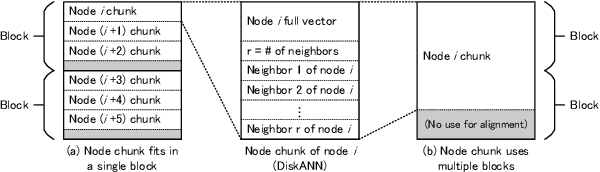



In approximate nearest neighbor search (ANNS) methods based on approximate proximity graphs, DiskANN achieves good recall-speed balance for large-scale datasets using both of RAM and storage. Despite it claims to save memory usage by loading compressed vectors by product quantization (PQ), its memory usage increases in proportion to the scale of datasets. In this paper, we propose All-in-Storage ANNS with Product Quantization (AiSAQ), which offloads the compressed vectors to storage. Our method achieves $\sim$10 MB memory usage in query search even with billion-scale datasets with minor performance degradation. AiSAQ also reduces the index load time before query search, which enables the index switch between muitiple billion-scale datasets and significantly enhances the flexibility of retrieval-augmented generation (RAG). This method is applicable to all graph-based ANNS algorithms and can be combined with higher-spec ANNS methods in the future.
RaLLe: A Framework for Developing and Evaluating Retrieval-Augmented Large Language Models
Aug 21, 2023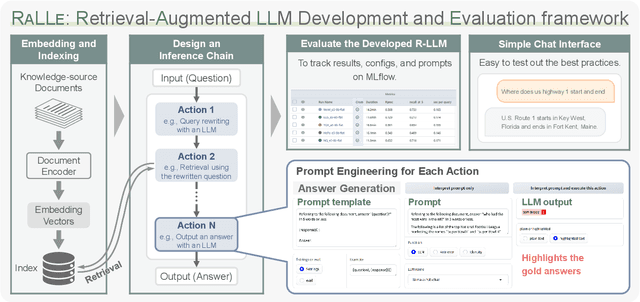

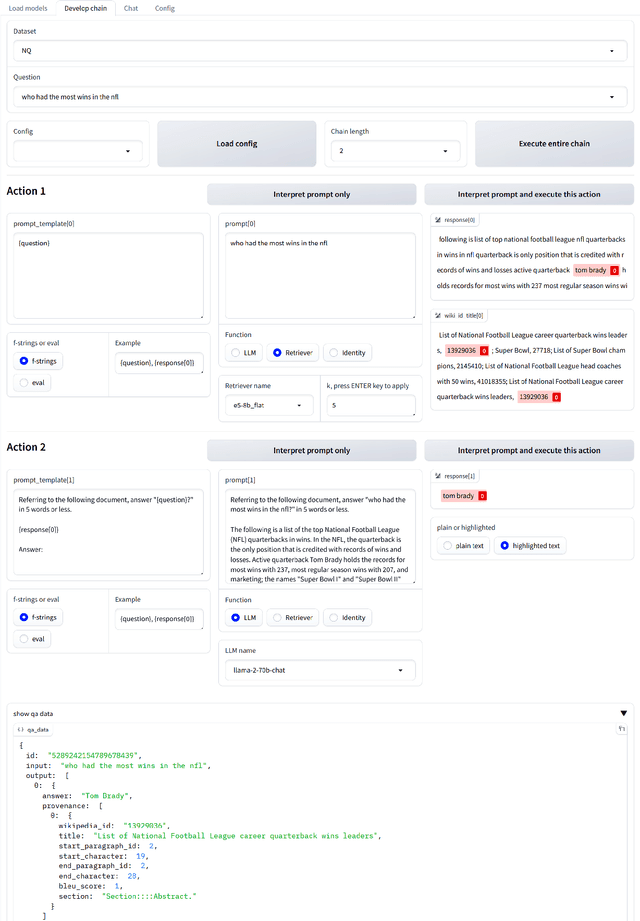
Retrieval-augmented large language models (R-LLMs) combine pre-trained large language models (LLMs) with information retrieval systems to improve the accuracy of factual question-answering. However, current libraries for building R-LLMs provide high-level abstractions without sufficient transparency for evaluating and optimizing prompts within specific inference processes such as retrieval and generation. To address this gap, we present RaLLe, an open-source framework designed to facilitate the development, evaluation, and optimization of R-LLMs for knowledge-intensive tasks. With RaLLe, developers can easily develop and evaluate R-LLMs, improving hand-crafted prompts, assessing individual inference processes, and objectively measuring overall system performance quantitatively. By leveraging these features, developers can enhance the performance and accuracy of their R-LLMs in knowledge-intensive generation tasks. We open-source our code at https://github.com/yhoshi3/RaLLe.
SimplyRetrieve: A Private and Lightweight Retrieval-Centric Generative AI Tool
Aug 08, 2023



Large Language Model (LLM) based Generative AI systems have seen significant progress in recent years. Integrating a knowledge retrieval architecture allows for seamless integration of private data into publicly available Generative AI systems using pre-trained LLM without requiring additional model fine-tuning. Moreover, Retrieval-Centric Generation (RCG) approach, a promising future research direction that explicitly separates roles of LLMs and retrievers in context interpretation and knowledge memorization, potentially leads to more efficient implementation. SimplyRetrieve is an open-source tool with the goal of providing a localized, lightweight, and user-friendly interface to these sophisticated advancements to the machine learning community. SimplyRetrieve features a GUI and API based RCG platform, assisted by a Private Knowledge Base Constructor and a Retrieval Tuning Module. By leveraging these capabilities, users can explore the potential of RCG for improving generative AI performance while maintaining privacy standards. The tool is available at https://github.com/RCGAI/SimplyRetrieve with an MIT license.
Can a Frozen Pretrained Language Model be used for Zero-shot Neural Retrieval on Entity-centric Questions?
Mar 09, 2023Neural document retrievers, including dense passage retrieval (DPR), have outperformed classical lexical-matching retrievers, such as BM25, when fine-tuned and tested on specific question-answering datasets. However, it has been shown that the existing dense retrievers do not generalize well not only out of domain but even in domain such as Wikipedia, especially when a named entity in a question is a dominant clue for retrieval. In this paper, we propose an approach toward in-domain generalization using the embeddings generated by the frozen language model trained with the entities in the domain. By not fine-tuning, we explore the possibility that the rich knowledge contained in a pretrained language model can be used for retrieval tasks. The proposed method outperforms conventional DPRs on entity-centric questions in Wikipedia domain and achieves almost comparable performance to BM25 and state-of-the-art SPAR model. We also show that the contextualized keys lead to strong improvements compared to BM25 when the entity names consist of common words. Our results demonstrate the feasibility of the zero-shot retrieval method for entity-centric questions of Wikipedia domain, where DPR has struggled to perform.
Revisiting a kNN-based Image Classification System with High-capacity Storage
Apr 03, 2022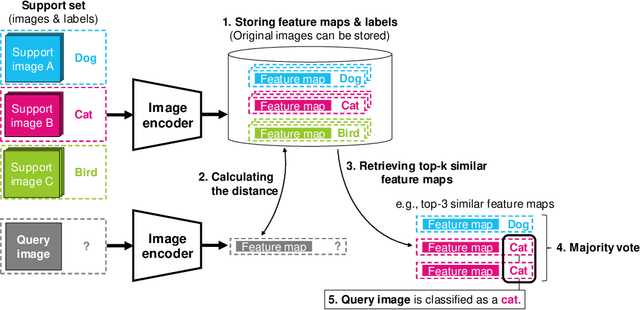



In existing image classification systems that use deep neural networks, the knowledge needed for image classification is implicitly stored in model parameters. If users want to update this knowledge, then they need to fine-tune the model parameters. Moreover, users cannot verify the validity of inference results or evaluate the contribution of knowledge to the results. In this paper, we investigate a system that stores knowledge for image classification, such as image feature maps, labels, and original images, not in model parameters but in external high-capacity storage. Our system refers to the storage like a database when classifying input images. To increase knowledge, our system updates the database instead of fine-tuning model parameters, which avoids catastrophic forgetting in incremental learning scenarios. We revisit a kNN (k-Nearest Neighbor) classifier and employ it in our system. By analyzing the neighborhood samples referred by the kNN algorithm, we can interpret how knowledge learned in the past is used for inference results. Our system achieves 79.8% top-1 accuracy on the ImageNet dataset without fine-tuning model parameters after pretraining, and 90.8% accuracy on the Split CIFAR-100 dataset in the task incremental learning setting.
Convolutional Neural Networks using Logarithmic Data Representation
Mar 17, 2016



Recent advances in convolutional neural networks have considered model complexity and hardware efficiency to enable deployment onto embedded systems and mobile devices. For example, it is now well-known that the arithmetic operations of deep networks can be encoded down to 8-bit fixed-point without significant deterioration in performance. However, further reduction in precision down to as low as 3-bit fixed-point results in significant losses in performance. In this paper we propose a new data representation that enables state-of-the-art networks to be encoded to 3 bits with negligible loss in classification performance. To perform this, we take advantage of the fact that the weights and activations in a trained network naturally have non-uniform distributions. Using non-uniform, base-2 logarithmic representation to encode weights, communicate activations, and perform dot-products enables networks to 1) achieve higher classification accuracies than fixed-point at the same resolution and 2) eliminate bulky digital multipliers. Finally, we propose an end-to-end training procedure that uses log representation at 5-bits, which achieves higher final test accuracy than linear at 5-bits.