 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Relevance Feedback for CLIP-based Interactive Image Retrieval
Apr 29, 2024Many image retrieval studies use metric learning to train an image encoder. However, metric learning cannot handle differences in users' preferences, and requires data to train an image encoder. To overcome these limitations, we revisit relevance feedback, a classic technique for interactive retrieval systems, and propose an interactive CLIP-based image retrieval system with relevance feedback. Our retrieval system first executes the retrieval, collects each user's unique preferences through binary feedback, and returns images the user prefers. Even when users have various preferences, our retrieval system learns each user's preference through the feedback and adapts to the preference. Moreover, our retrieval system leverages CLIP's zero-shot transferability and achieves high accuracy without training. We empirically show that our retrieval system competes well with state-of-the-art metric learning in category-based image retrieval, despite not training image encoders specifically for each dataset. Furthermore, we set up two additional experimental settings where users have various preferences: one-label-based image retrieval and conditioned image retrieval. In both cases, our retrieval system effectively adapts to each user's preferences, resulting in improved accuracy compared to image retrieval without feedback. Overall, our work highlights the potential benefits of integrating CLIP with classic relevance feedback techniques to enhance image retrieval.
RaLLe: A Framework for Developing and Evaluating Retrieval-Augmented Large Language Models
Aug 21, 2023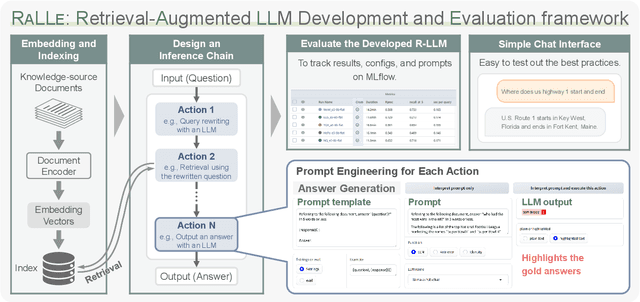
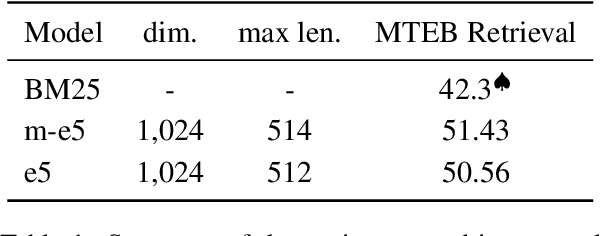

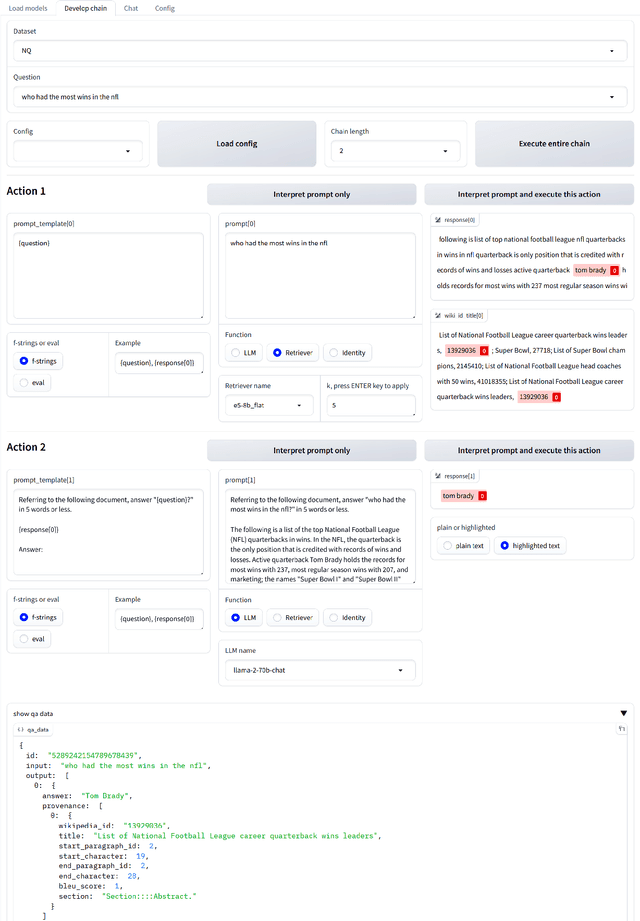
Retrieval-augmented large language models (R-LLMs) combine pre-trained large language models (LLMs) with information retrieval systems to improve the accuracy of factual question-answering. However, current libraries for building R-LLMs provide high-level abstractions without sufficient transparency for evaluating and optimizing prompts within specific inference processes such as retrieval and generation. To address this gap, we present RaLLe, an open-source framework designed to facilitate the development, evaluation, and optimization of R-LLMs for knowledge-intensive tasks. With RaLLe, developers can easily develop and evaluate R-LLMs, improving hand-crafted prompts, assessing individual inference processes, and objectively measuring overall system performance quantitatively. By leveraging these features, developers can enhance the performance and accuracy of their R-LLMs in knowledge-intensive generation tasks. We open-source our code at https://github.com/yhoshi3/RaLLe.
SimplyRetrieve: A Private and Lightweight Retrieval-Centric Generative AI Tool
Aug 08, 2023



Large Language Model (LLM) based Generative AI systems have seen significant progress in recent years. Integrating a knowledge retrieval architecture allows for seamless integration of private data into publicly available Generative AI systems using pre-trained LLM without requiring additional model fine-tuning. Moreover, Retrieval-Centric Generation (RCG) approach, a promising future research direction that explicitly separates roles of LLMs and retrievers in context interpretation and knowledge memorization, potentially leads to more efficient implementation. SimplyRetrieve is an open-source tool with the goal of providing a localized, lightweight, and user-friendly interface to these sophisticated advancements to the machine learning community. SimplyRetrieve features a GUI and API based RCG platform, assisted by a Private Knowledge Base Constructor and a Retrieval Tuning Module. By leveraging these capabilities, users can explore the potential of RCG for improving generative AI performance while maintaining privacy standards. The tool is available at https://github.com/RCGAI/SimplyRetrieve with an MIT license.
Can a Frozen Pretrained Language Model be used for Zero-shot Neural Retrieval on Entity-centric Questions?
Mar 09, 2023

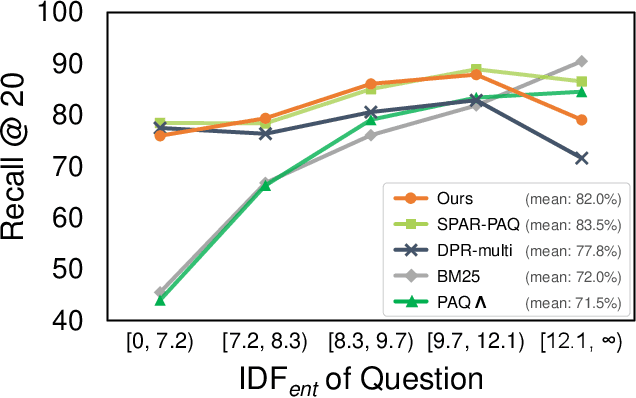
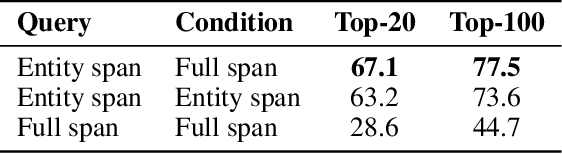
Neural document retrievers, including dense passage retrieval (DPR), have outperformed classical lexical-matching retrievers, such as BM25, when fine-tuned and tested on specific question-answering datasets. However, it has been shown that the existing dense retrievers do not generalize well not only out of domain but even in domain such as Wikipedia, especially when a named entity in a question is a dominant clue for retrieval. In this paper, we propose an approach toward in-domain generalization using the embeddings generated by the frozen language model trained with the entities in the domain. By not fine-tuning, we explore the possibility that the rich knowledge contained in a pretrained language model can be used for retrieval tasks. The proposed method outperforms conventional DPRs on entity-centric questions in Wikipedia domain and achieves almost comparable performance to BM25 and state-of-the-art SPAR model. We also show that the contextualized keys lead to strong improvements compared to BM25 when the entity names consist of common words. Our results demonstrate the feasibility of the zero-shot retrieval method for entity-centric questions of Wikipedia domain, where DPR has struggled to perform.