 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiSAQ: All-in-Storage ANNS with Product Quantization for DRAM-free Information Retrieval
Apr 09, 2024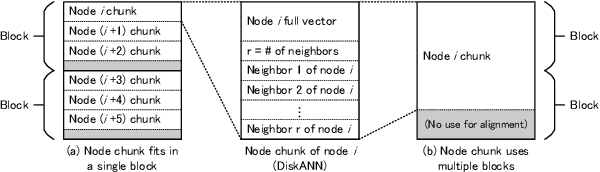



In approximate nearest neighbor search (ANNS) methods based on approximate proximity graphs, DiskANN achieves good recall-speed balance for large-scale datasets using both of RAM and storage. Despite it claims to save memory usage by loading compressed vectors by product quantization (PQ), its memory usage increases in proportion to the scale of datasets. In this paper, we propose All-in-Storage ANNS with Product Quantization (AiSAQ), which offloads the compressed vectors to storage. Our method achieves $\sim$10 MB memory usage in query search even with billion-scale datasets with minor performance degradation. AiSAQ also reduces the index load time before query search, which enables the index switch between muitiple billion-scale datasets and significantly enhances the flexibility of retrieval-augmented generation (RAG). This method is applicable to all graph-based ANNS algorithms and can be combined with higher-spec ANNS methods in the future.
RaLLe: A Framework for Developing and Evaluating Retrieval-Augmented Large Language Models
Aug 21, 2023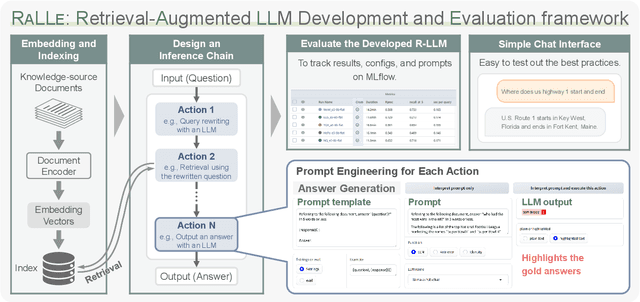
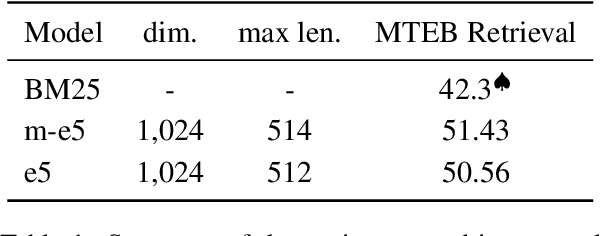

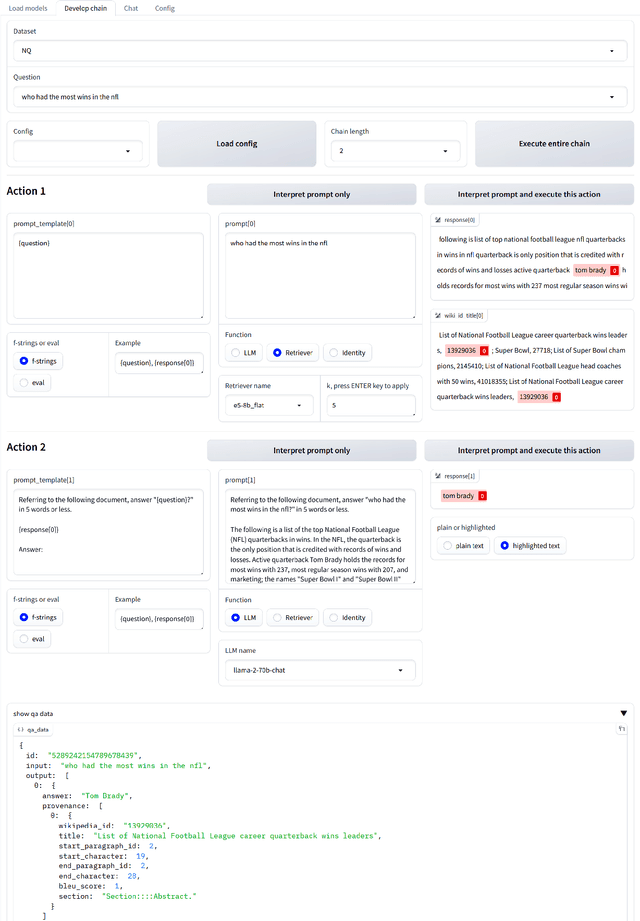
Retrieval-augmented large language models (R-LLMs) combine pre-trained large language models (LLMs) with information retrieval systems to improve the accuracy of factual question-answering. However, current libraries for building R-LLMs provide high-level abstractions without sufficient transparency for evaluating and optimizing prompts within specific inference processes such as retrieval and generation. To address this gap, we present RaLLe, an open-source framework designed to facilitate the development, evaluation, and optimization of R-LLMs for knowledge-intensive tasks. With RaLLe, developers can easily develop and evaluate R-LLMs, improving hand-crafted prompts, assessing individual inference processes, and objectively measuring overall system performance quantitatively. By leveraging these features, developers can enhance the performance and accuracy of their R-LLMs in knowledge-intensive generation tasks. We open-source our code at https://github.com/yhoshi3/RaLLe.