 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Image Clustering with Artifacts Attenuation via Inference-Time Attention Engineering
Oct 07, 2024



The goal of this paper is to improve the performance of pretrained Vision Transformer (ViT) models, particularly DINOv2, in image clustering task without requiring re-training or fine-tuning. As model size increases, high-norm artifacts anomaly appears in the patches of multi-head attention. We observe that this anomaly leads to reduced accuracy in zero-shot image clustering. These artifacts are characterized by disproportionately large values in the attention map compared to other patch tokens. To address these artifacts, we propose an approach called Inference-Time Attention Engineering (ITAE), which manipulates attention function during inference. Specifically, we identify the artifacts by investigating one of the Query-Key-Value (QKV) patches in the multi-head attention and attenuate their corresponding attention values inside the pretrained models. ITAE shows improved clustering accuracy on multiple datasets by exhibiting more expressive features in latent space. Our findings highlight the potential of ITAE as a practical solution for reducing artifacts in pretrained ViT models and improving model performance in clustering tasks without the need for re-training or fine-tuning.
Rethinking Sparse Lexical Representations for Image Retrieval in the Age of Rising Multi-Modal Large Language Models
Aug 29, 2024
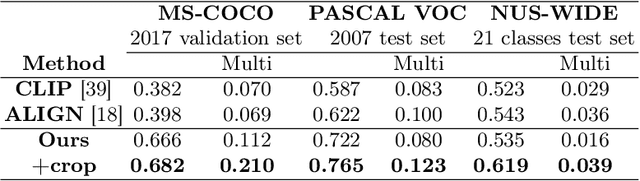


In this paper, we rethink sparse lexical representations for image retrieval. By utilizing multi-modal large language models (M-LLMs) that support visual prompting, we can extract image features and convert them into textual data, enabling us to utilize efficient sparse retrieval algorithms employed in natural language processing for image retrieval tasks. To assist the LLM in extracting image features, we apply data augmentation techniques for key expansion and analyze the impact with a metric for relevance between images and textual data. We empirically show the superior precision and recall performance of our image retrieval method compared to conventional vision-language model-based methods on the MS-COCO, PASCAL VOC, and NUS-WIDE datasets in a keyword-based image retrieval scenario, where keywords serve as search queries. We also demonstrate that the retrieval performance can be improved by iteratively incorporating keywords into search queries.
Revisiting a kNN-based Image Classification System with High-capacity Storage
Apr 03, 2022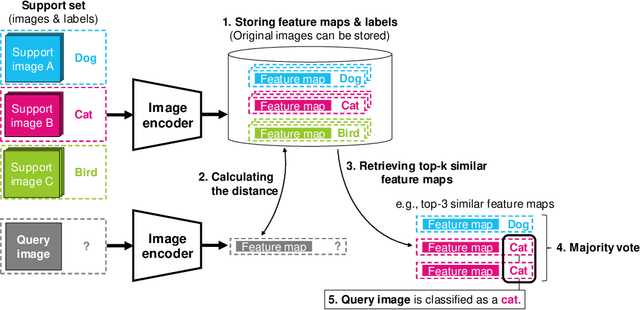



In existing image classification systems that use deep neural networks, the knowledge needed for image classification is implicitly stored in model parameters. If users want to update this knowledge, then they need to fine-tune the model parameters. Moreover, users cannot verify the validity of inference results or evaluate the contribution of knowledge to the results. In this paper, we investigate a system that stores knowledge for image classification, such as image feature maps, labels, and original images, not in model parameters but in external high-capacity storage. Our system refers to the storage like a database when classifying input images. To increase knowledge, our system updates the database instead of fine-tuning model parameters, which avoids catastrophic forgetting in incremental learning scenarios. We revisit a kNN (k-Nearest Neighbor) classifier and employ it in our system. By analyzing the neighborhood samples referred by the kNN algorithm, we can interpret how knowledge learned in the past is used for inference results. Our system achieves 79.8% top-1 accuracy on the ImageNet dataset without fine-tuning model parameters after pretraining, and 90.8% accuracy on the Split CIFAR-100 dataset in the task incremental learning setting.