 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Robustifying Guidance for Monocular 3D Face Reconstruction
Dec 29, 2021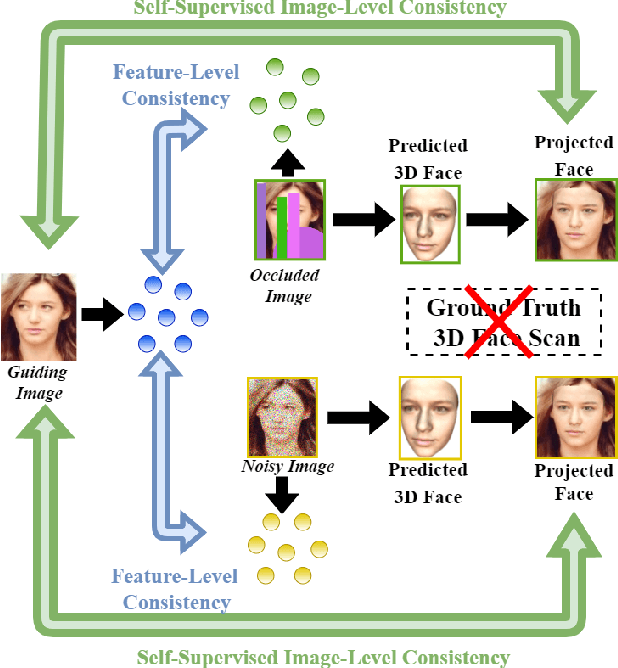
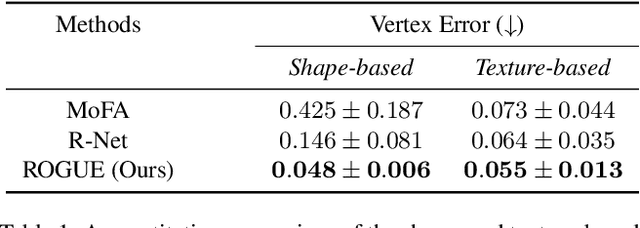
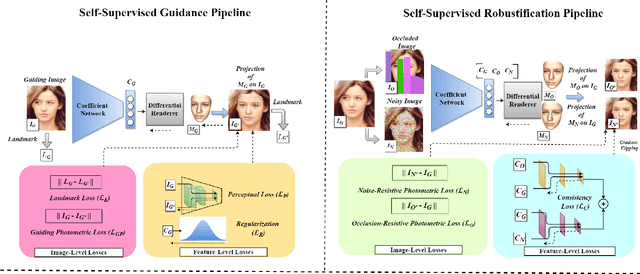
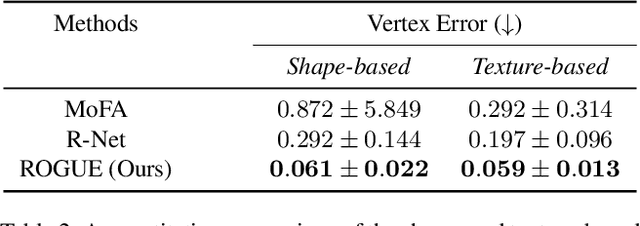
Despite the recent developments in 3D Face Reconstruction from occluded and noisy face images, the performance is still unsatisfactory. One of the main challenges is to handle moderate to heavy occlusions in the face images. In addition, the noise in the face images inhibits the correct capture of facial attributes, thus needing to be reliably addressed. Moreover, most existing methods rely on additional dependencies, posing numerous constraints over the training procedure. Therefore, we propose a Self-Supervised RObustifying GUidancE (ROGUE) framework to obtain robustness against occlusions and noise in the face images. The proposed network contains 1) the Guidance Pipeline to obtain the 3D face coefficients for the clean faces, and 2) the Robustification Pipeline to acquire the consistency between the estimated coefficients for occluded or noisy images and the clean counterpart. The proposed image- and feature-level loss functions aid the ROGUE learning process without posing additional dependencies. On the three variations of the test dataset of CelebA: rational occlusions, delusional occlusions, and noisy face images, our method outperforms the current state-of-the-art method by large margins (e.g., for the shape-based 3D vertex errors, a reduction from 0.146 to 0.048 for rational occlusions, from 0.292 to 0.061 for delusional occlusions and from 0.269 to 0.053 for the noise in the face images), demonstrating the effectiveness of the proposed approach.
Semantic Mobile Base Station Placement
Aug 11, 2021
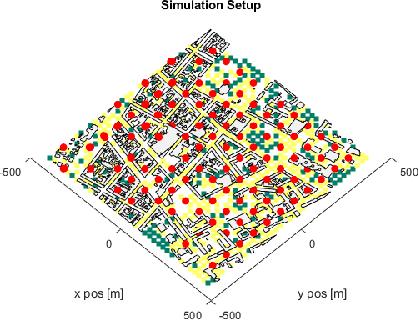
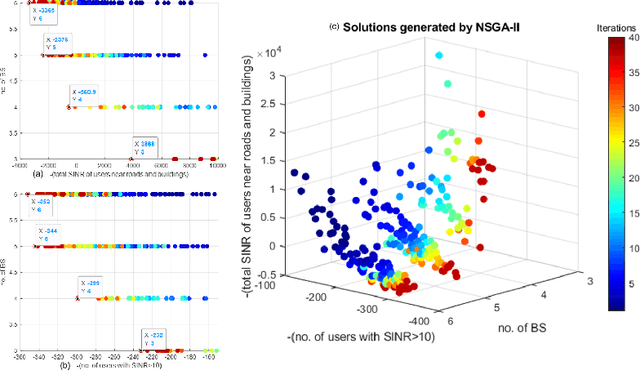

Location of Base Stations (BS) in mobile networks plays an important role in coverage and received signal strength. As Internet ofThings (IoT), autonomous vehicles and smart cities evolve, wireless net-work coverage will have an important role in ensuring seamless connectivity. Due to use of higher carrier frequencies, blockages cause communication to primarily be Line of Sight (LoS), increasing the importance of base station placement. In this paper, we propose a novel placement pipeline in which we perform semantic segmentation of aerial drone imagery using DeepLabv3+ and create its 2.5D model with the help ofDigital Surface Model (DSM). This is used along with Vienna simulator for finding the best location for deploying base stations by formulating the problem as a multi-objective function and solving it using Non-Dominated Sorting Genetic Algorithm II (NSGA-II). The case with and without prior deployed base station is considered. We evaluate the basestation deployment based on Signal to Interference Noise Ratio (SINR)coverage probability and user down-link throughput. This is followed by comparison with other base station placement methods and the bene-fits offered by our approach. Our work is novel as it considers scenarios where there is high ground elevation and building density variation, and shows that irregular BS placement improves coverage.
Design and Development of an automated Robotic Pick & Stow System for an e-Commerce Warehouse
Mar 07, 2017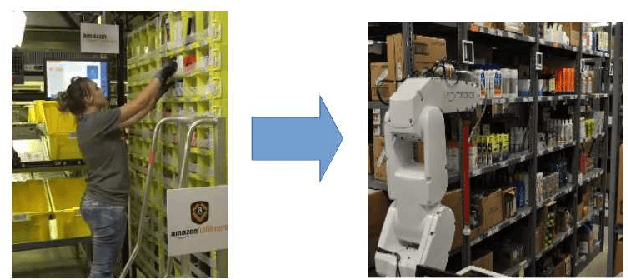
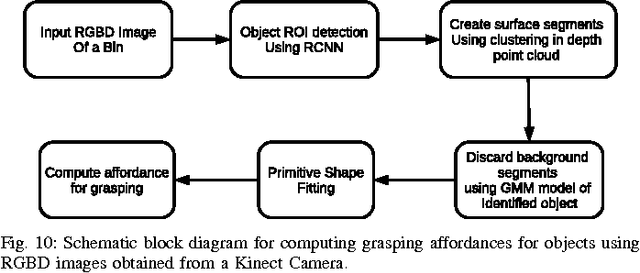
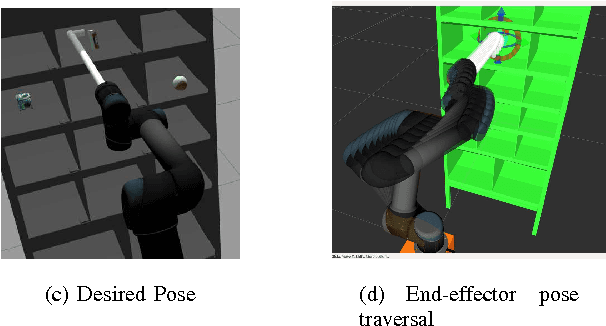
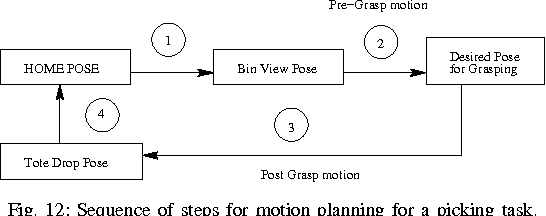
In this paper, we provide details of a robotic system that can automate the task of picking and stowing objects from and to a rack in an e-commerce fulfillment warehouse. The system primarily comprises of four main modules: (1) Perception module responsible for recognizing query objects and localizing them in the 3-dimensional robot workspace; (2) Planning module generates necessary paths that the robot end- effector has to take for reaching the objects in the rack or in the tote; (3) Calibration module that defines the physical workspace for the robot visible through the on-board vision system; and (4) Gripping and suction system for picking and stowing different kinds of objects. The perception module uses a faster region-based Convolutional Neural Network (R-CNN) to recognize objects. We designed a novel two finger gripper that incorporates pneumatic valve based suction effect to enhance its ability to pick different kinds of objects. The system was developed by IITK-TCS team for participation in the Amazon Picking Challenge 2016 event. The team secured a fifth place in the stowing task in the event. The purpose of this article is to share our experiences with students and practicing engineers and enable them to build similar systems. The overall efficacy of the system is demonstrated through several simulation as well as real-world experiments with actual robots.
People Counting in High Density Crowds from Still Images
Jul 30, 2015

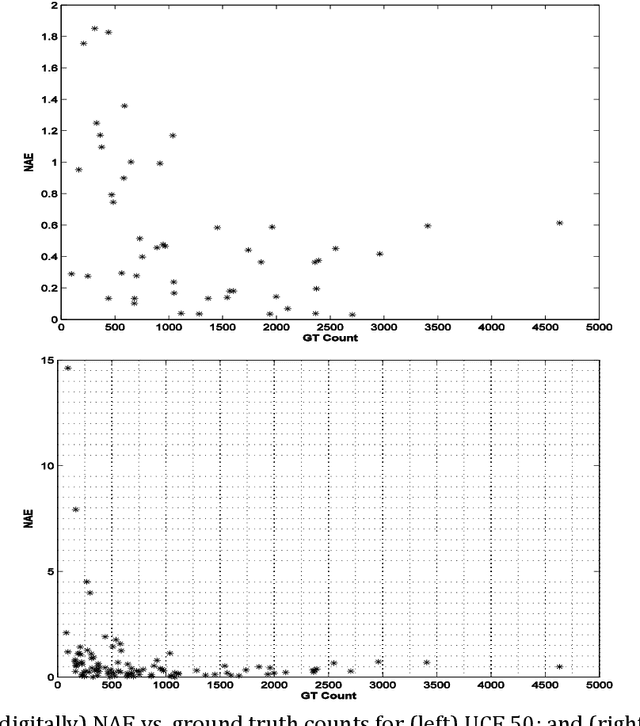

We present a method of estimating the number of people in high density crowds from still images. The method estimates counts by fusing information from multiple sources. Most of the existing work on crowd counting deals with very small crowds (tens of individuals) and use temporal information from videos. Our method uses only still images to estimate the counts in high density images (hundreds to thousands of individuals). At this scale, we cannot rely on only one set of features for count estimation. We, therefore, use multiple sources, viz. interest points (SIFT), Fourier analysis, wavelet decomposition, GLCM features and low confidence head detections, to estimate the counts. Each of these sources gives a separate estimate of the count along with confidences and other statistical measures which are then combined to obtain the final estimate. We test our method on an existing dataset of fifty images containing over 64000 individuals. Further, we added another fifty annotated images of crowds and tested on the complete dataset of hundred images containing over 87000 individuals. The counts per image range from 81 to 4633. We report the performance in terms of mean absolute error, which is a measure of accuracy of the method, and mean normalised absolute error, which is a measure of the robustness.