 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Only Heterogeneous Image-Patch-Text Graph Supervision for Advancing Few-Shot Learning Adapters
Mar 18, 2026Recent adapter-based CLIP tuning (e.g., Tip-Adapter) is a strong few-shot learner, achieving efficiency by caching support features for fast prototype matching. However, these methods rely on global uni-modal feature vectors, overlooking fine-grained patch relations and their structural alignment with class text. To bridge this gap without incurring inference costs, we introduce a novel asymmetric training-only framework. Instead of altering the lightweight adapter, we construct a high-capacity auxiliary Heterogeneous Graph Teacher that operates solely during training. This teacher (i) integrates multi-scale visual patches and text prompts into a unified graph, (ii) performs deep cross-modal reasoning via a Modality-aware Graph Transformer (MGT), and (iii) applies discriminative node filtering to extract high-fidelity class features. Crucially, we employ a cache-aware dual-objective strategy to supervise this relational knowledge directly into the Tip-Adapter's key-value cache, effectively upgrading the prototypes while the graph teacher is discarded at test time. Thus, inference remains identical to Tip-Adapter with zero extra latency or memory. Across standard 1-16-shot benchmarks, our method consistently establishes a new state-of-the-art. Ablations confirm that the auxiliary graph supervision, text-guided reasoning, and node filtering are the essential ingredients for robust few-shot adaptation. Code is available at https://github.com/MR-Sherif/TOGA.git.
CRC-RL: A Novel Visual Feature Representation Architecture for Unsupervised Reinforcement Learning
Jan 31, 2023This paper addresses the problem of visual feature representation learning with an aim to improve the performance of end-to-end reinforcement learning (RL) models. Specifically, a novel architecture is proposed that uses a heterogeneous loss function, called CRC loss, to learn improved visual features which can then be used for policy learning in RL. The CRC-loss function is a combination of three individual loss functions, namely, contrastive, reconstruction and consistency loss. The feature representation is learned in parallel to the policy learning while sharing the weight updates through a Siamese Twin encoder model. This encoder model is augmented with a decoder network and a feature projection network to facilitate computation of the above loss components. Through empirical analysis involving latent feature visualization, an attempt is made to provide an insight into the role played by this loss function in learning new action-dependent features and how they are linked to the complexity of the problems being solved. The proposed architecture, called CRC-RL, is shown to outperform the existing state-of-the-art methods on the challenging Deep mind control suite environments by a significant margin thereby creating a new benchmark in this field.
Benchmarking Deep Reinforcement Learning Algorithms for Vision-based Robotics
Jan 11, 2022
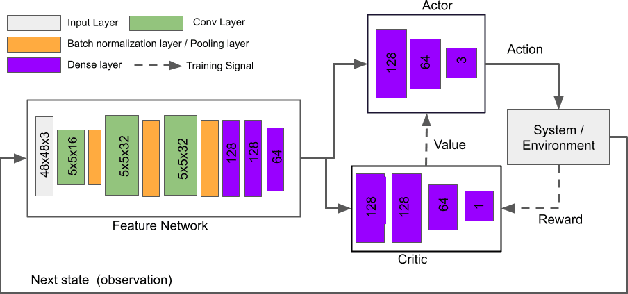
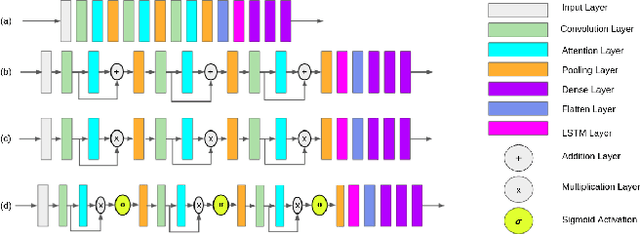
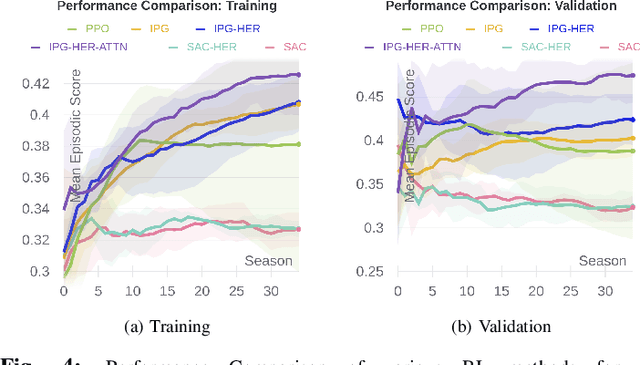
This paper presents a benchmarking study of some of the state-of-the-art reinforcement learning algorithms used for solving two simulated vision-based robotics problems. The algorithms considered in this study include soft actor-critic (SAC), proximal policy optimization (PPO), interpolated policy gradients (IPG), and their variants with Hindsight Experience replay (HER). The performances of these algorithms are compared against PyBullet's two simulation environments known as KukaDiverseObjectEnv and RacecarZEDGymEnv respectively. The state observations in these environments are available in the form of RGB images and the action space is continuous, making them difficult to solve. A number of strategies are suggested to provide intermediate hindsight goals required for implementing HER algorithm on these problems which are essentially single-goal environments. In addition, a number of feature extraction architectures are proposed to incorporate spatial and temporal attention in the learning process. Through rigorous simulation experiments, the improvement achieved with these components are established. To the best of our knowledge, such a benchmarking study is not available for the above two vision-based robotics problems making it a novel contribution in the field.
Controlling an Inverted Pendulum with Policy Gradient Methods-A Tutorial
May 17, 2021
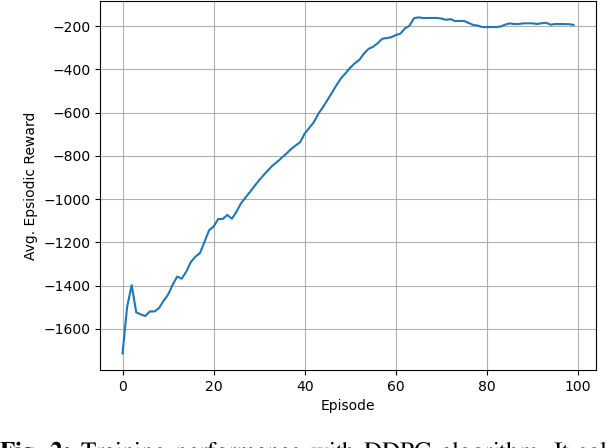
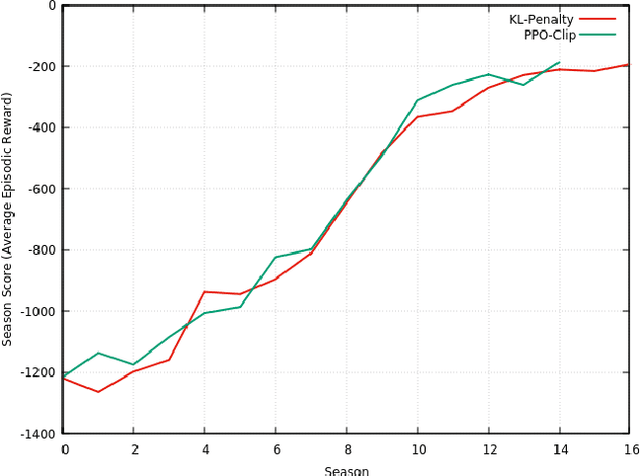
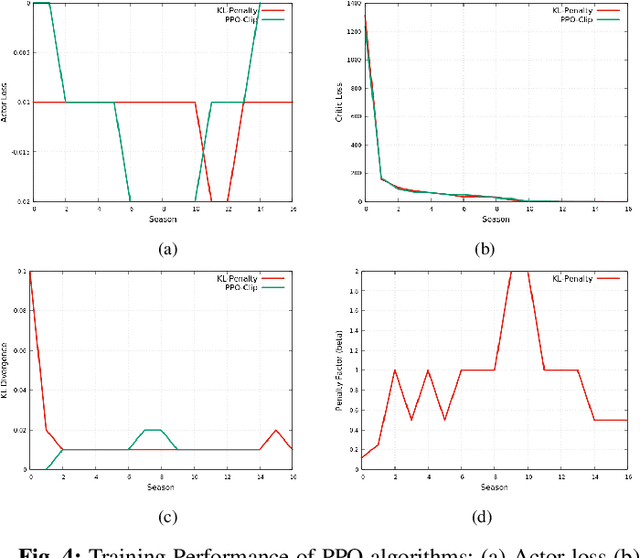
This paper provides the details of implementing two important policy gradient methods to solve the inverted pendulum problem. These are namely the Deep Deterministic Policy Gradient (DDPG) and the Proximal Policy Optimization (PPO) algorithm. The problem is solved by using an actor-critic model where an actor-network is used to learn the policy function and a critic network is to evaluate the actor-network by learning to estimate the Q function. Apart from briefly explaining the mathematics behind these two algorithms, the details of python implementation are provided which helps in demystifying the underlying complexity of the algorithm. In the process, the readers will be introduced to OpenAI/Gym, Tensorflow 2.x and Keras utilities used for implementing the above concepts.
Regional Attention Network for Head Pose and Fine-grained Gesture Recognition
Jan 17, 2021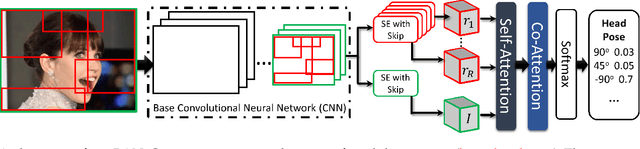
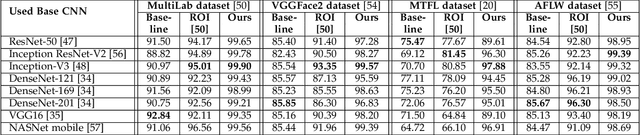
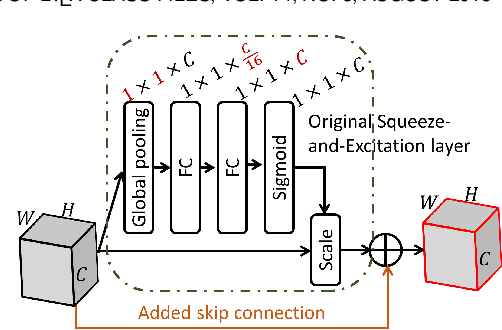
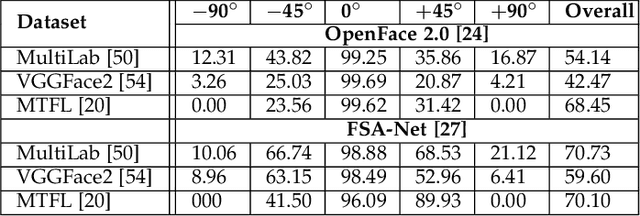
Affect is often expressed via non-verbal body language such as actions/gestures, which are vital indicators for human behaviors. Recent studies on recognition of fine-grained actions/gestures in monocular images have mainly focused on modeling spatial configuration of body parts representing body pose, human-objects interactions and variations in local appearance. The results show that this is a brittle approach since it relies on accurate body parts/objects detection. In this work, we argue that there exist local discriminative semantic regions, whose "informativeness" can be evaluated by the attention mechanism for inferring fine-grained gestures/actions. To this end, we propose a novel end-to-end \textbf{Regional Attention Network (RAN)}, which is a fully Convolutional Neural Network (CNN) to combine multiple contextual regions through attention mechanism, focusing on parts of the images that are most relevant to a given task. Our regions consist of one or more consecutive cells and are adapted from the strategies used in computing HOG (Histogram of Oriented Gradient) descriptor. The model is extensively evaluated on ten datasets belonging to 3 different scenarios: 1) head pose recognition, 2) drivers state recognition, and 3) human action and facial expression recognition. The proposed approach outperforms the state-of-the-art by a considerable margin in different metrics.
* This manuscript is the accepted version of the published paper in IEEE Transaction on Affective Computing
Chitrakar: Robotic System for Drawing Jordan Curve of Facial Portrait
Nov 21, 2020

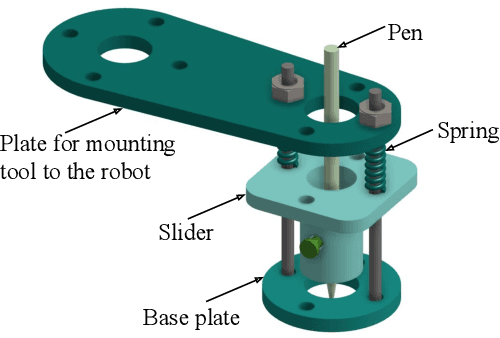
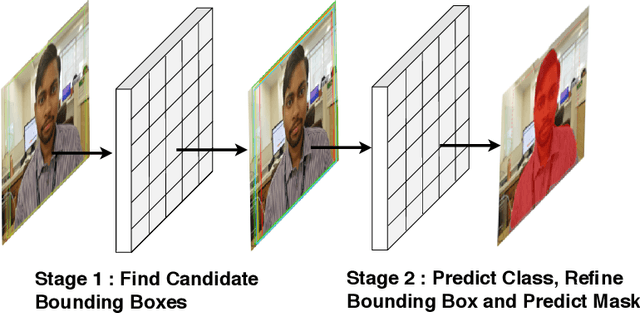
This paper presents a robotic system (\textit{Chitrakar}) which autonomously converts any image of a human face to a recognizable non-self-intersecting loop (Jordan Curve) and draws it on any planar surface. The image is processed using Mask R-CNN for instance segmentation, Laplacian of Gaussian (LoG) for feature enhancement and intensity-based probabilistic stippling for the image to points conversion. These points are treated as a destination for a travelling salesman and are connected with an optimal path which is calculated heuristically by minimizing the total distance to be travelled. This path is converted to a Jordan Curve in feasible time by removing intersections using a combination of image processing, 2-opt, and Bresenham's Algorithm. The robotic system generates $n$ instances of each image for human aesthetic judgement, out of which the most appealing instance is selected for the final drawing. The drawing is executed carefully by the robot's arm using trapezoidal velocity profiles for jerk-free and fast motion. The drawing, with a decent resolution, can be completed in less than 30 minutes which is impossible to do by hand. This work demonstrates the use of robotics to augment humans in executing difficult craft-work instead of replacing them altogether.
A Method for Handling Multi-class Imbalanced Data by Geometry based Information Sampling and Class Prioritized Synthetic Data Generation
Oct 11, 2020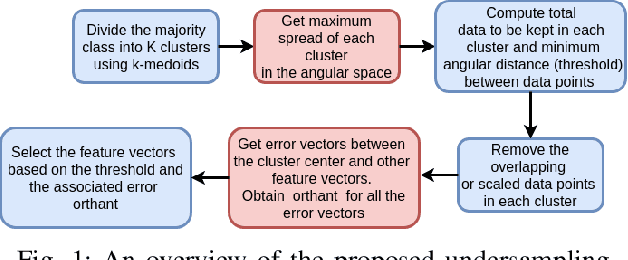
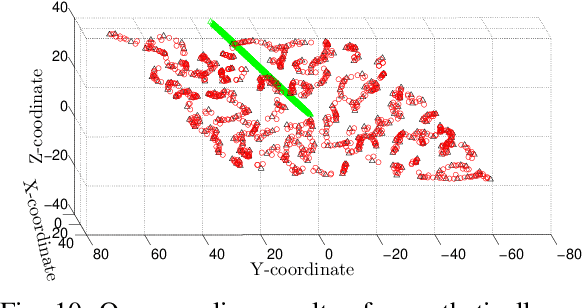
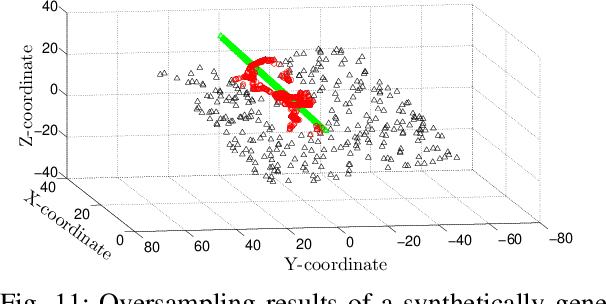
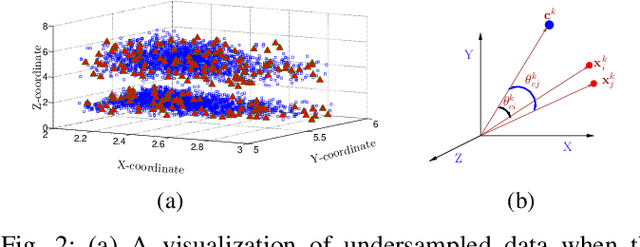
This paper looks into the problem of handling imbalanced data in a multi-label classification problem. The problem is solved by proposing two novel methods that primarily exploit the geometric relationship between the feature vectors. The first one is an undersampling algorithm that uses angle between feature vectors to select more informative samples while rejecting the less informative ones. A suitable criterion is proposed to define the informativeness of a given sample. The second one is an oversampling algorithm that uses a generative algorithm to create new synthetic data that respects all class boundaries. This is achieved by finding \emph{no man's land} based on Euclidean distance between the feature vectors. The efficacy of the proposed methods is analyzed by solving a generic multi-class recognition problem based on mixture of Gaussians. The superiority of the proposed algorithms is established through comparison with other state-of-the-art methods, including SMOTE and ADASYN, over ten different publicly available datasets exhibiting high-to-extreme data imbalance. These two methods are combined into a single data processing framework and is labeled as ``GICaPS'' to highlight the role of geometry-based information (GI) sampling and Class-Prioritized Synthesis (CaPS) in dealing with multi-class data imbalance problem, thereby making a novel contribution in this field.
Unsupervised Monocular Depth Estimation for Night-time Images using Adversarial Domain Feature Adaptation
Oct 03, 2020
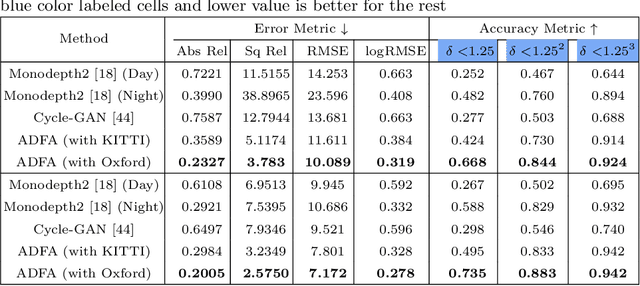
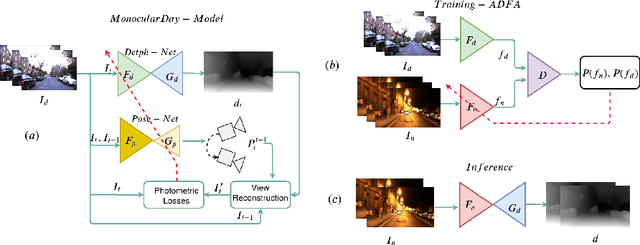
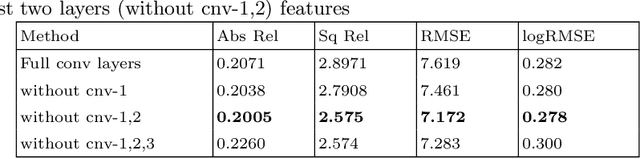
In this paper, we look into the problem of estimating per-pixel depth maps from unconstrained RGB monocular night-time images which is a difficult task that has not been addressed adequately in the literature. The state-of-the-art day-time depth estimation methods fail miserably when tested with night-time images due to a large domain shift between them. The usual photo metric losses used for training these networks may not work for night-time images due to the absence of uniform lighting which is commonly present in day-time images, making it a difficult problem to solve. We propose to solve this problem by posing it as a domain adaptation problem where a network trained with day-time images is adapted to work for night-time images. Specifically, an encoder is trained to generate features from night-time images that are indistinguishable from those obtained from day-time images by using a PatchGAN-based adversarial discriminative learning method. Unlike the existing methods that directly adapt depth prediction (network output), we propose to adapt feature maps obtained from the encoder network so that a pre-trained day-time depth decoder can be directly used for predicting depth from these adapted features. Hence, the resulting method is termed as "Adversarial Domain Feature Adaptation (ADFA)" and its efficacy is demonstrated through experimentation on the challenging Oxford night driving dataset. Also, The modular encoder-decoder architecture for the proposed ADFA method allows us to use the encoder module as a feature extractor which can be used in many other applications. One such application is demonstrated where the features obtained from our adapted encoder network are shown to outperform other state-of-the-art methods in a visual place recognition problem, thereby, further establishing the usefulness and effectiveness of the proposed approach.
A Generalized Reinforcement Learning Algorithm for Online 3D Bin-Packing
Jul 01, 2020
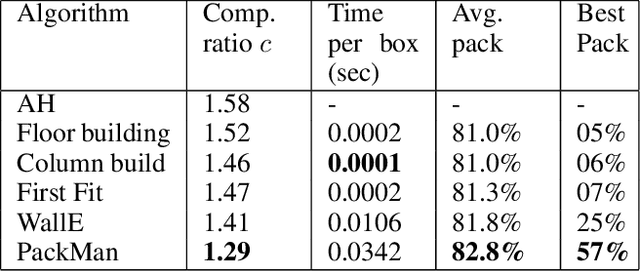
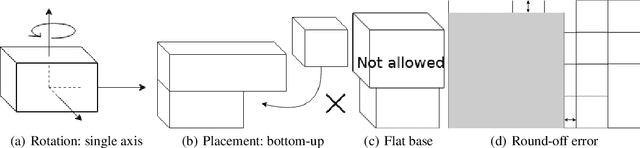

We propose a Deep Reinforcement Learning (Deep RL) algorithm for solving the online 3D bin packing problem for an arbitrary number of bins and any bin size. The focus is on producing decisions that can be physically implemented by a robotic loading arm, a laboratory prototype used for testing the concept. The problem considered in this paper is novel in two ways. First, unlike the traditional 3D bin packing problem, we assume that the entire set of objects to be packed is not known a priori. Instead, a fixed number of upcoming objects is visible to the loading system, and they must be loaded in the order of arrival. Second, the goal is not to move objects from one point to another via a feasible path, but to find a location and orientation for each object that maximises the overall packing efficiency of the bin(s). Finally, the learnt model is designed to work with problem instances of arbitrary size without retraining. Simulation results show that the RL-based method outperforms state-of-the-art online bin packing heuristics in terms of empirical competitive ratio and volume efficiency.
Balancing a CartPole System with Reinforcement Learning -- A Tutorial
Jun 12, 2020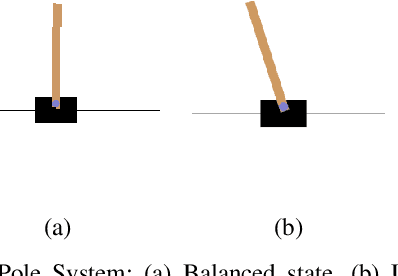
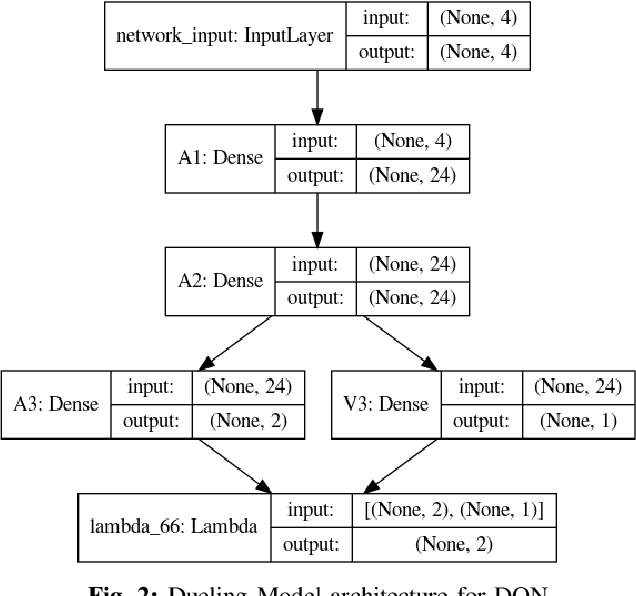
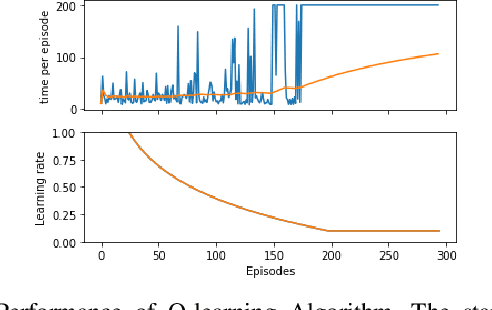
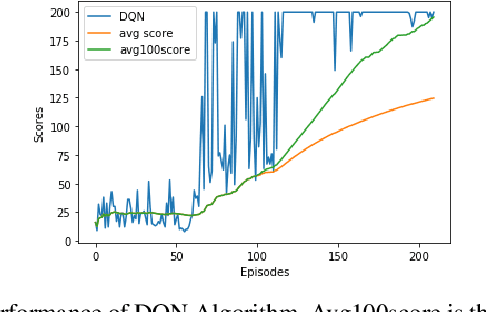
In this paper, we provide the details of implementing various reinforcement learning (RL) algorithms for controlling a Cart-Pole system. In particular, we describe various RL concepts such as Q-learning, Deep Q Networks (DQN), Double DQN, Dueling networks, (prioritized) experience replay and show their effect on the learning performance. In the process, the readers will be introduced to OpenAI/Gym and Keras utilities used for implementing the above concepts. It is observed that DQN with PER provides best performance among all other architectures being able to solve the problem within 150 episodes.