 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling an Inverted Pendulum with Policy Gradient Methods-A Tutorial
Paper and Code
May 17, 2021
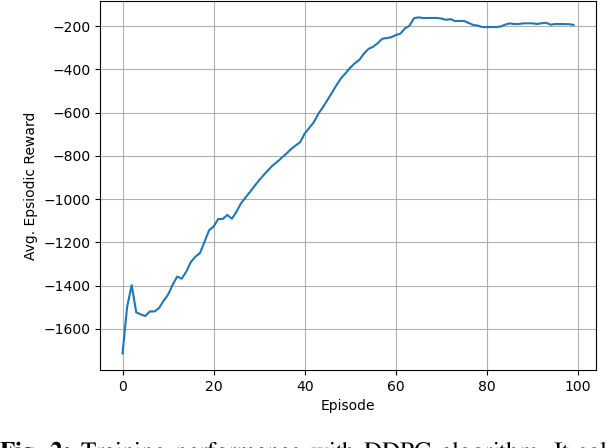
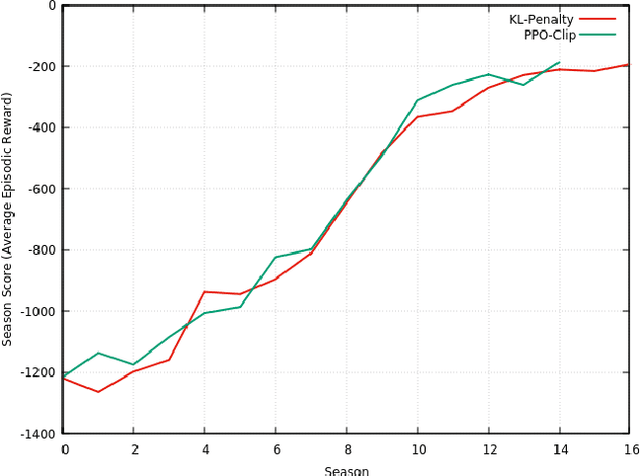
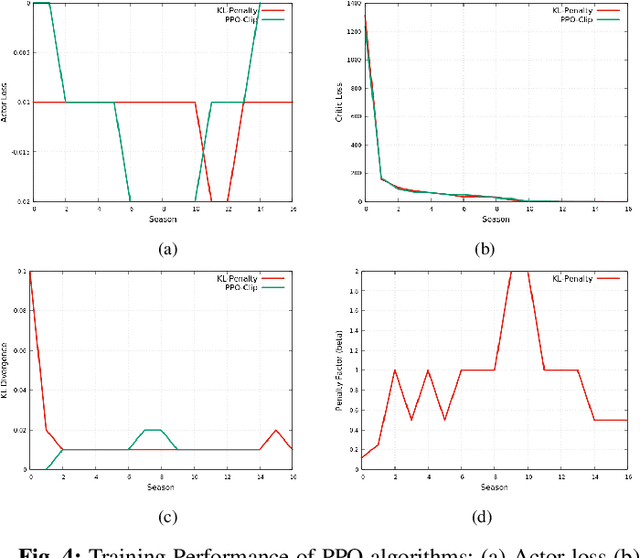
This paper provides the details of implementing two important policy gradient methods to solve the inverted pendulum problem. These are namely the Deep Deterministic Policy Gradient (DDPG) and the Proximal Policy Optimization (PPO) algorithm. The problem is solved by using an actor-critic model where an actor-network is used to learn the policy function and a critic network is to evaluate the actor-network by learning to estimate the Q function. Apart from briefly explaining the mathematics behind these two algorithms, the details of python implementation are provided which helps in demystifying the underlying complexity of the algorithm. In the process, the readers will be introduced to OpenAI/Gym, Tensorflow 2.x and Keras utilities used for implementing the above concepts.