 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Method for Handling Multi-class Imbalanced Data by Geometry based Information Sampling and Class Prioritized Synthetic Data Generation
Paper and Code
Oct 11, 2020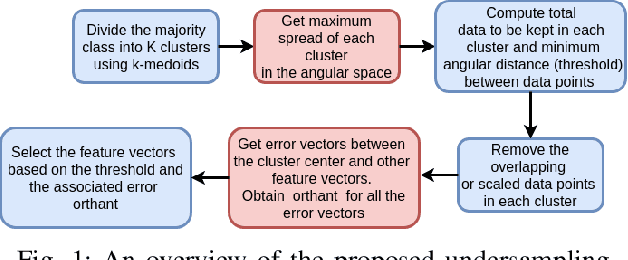
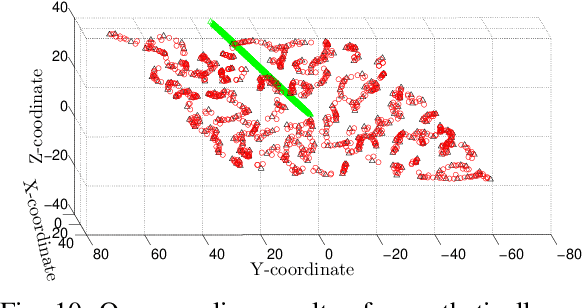
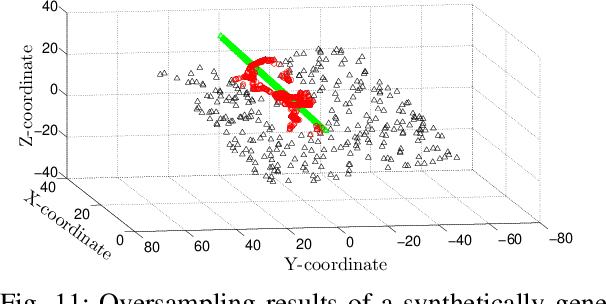
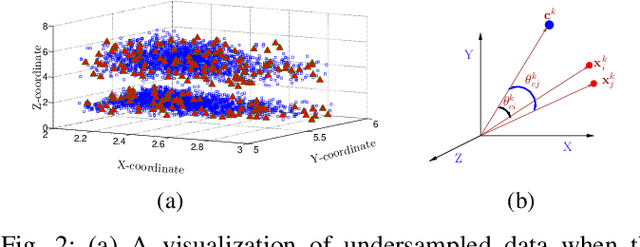
This paper looks into the problem of handling imbalanced data in a multi-label classification problem. The problem is solved by proposing two novel methods that primarily exploit the geometric relationship between the feature vectors. The first one is an undersampling algorithm that uses angle between feature vectors to select more informative samples while rejecting the less informative ones. A suitable criterion is proposed to define the informativeness of a given sample. The second one is an oversampling algorithm that uses a generative algorithm to create new synthetic data that respects all class boundaries. This is achieved by finding \emph{no man's land} based on Euclidean distance between the feature vectors. The efficacy of the proposed methods is analyzed by solving a generic multi-class recognition problem based on mixture of Gaussians. The superiority of the proposed algorithms is established through comparison with other state-of-the-art methods, including SMOTE and ADASYN, over ten different publicly available datasets exhibiting high-to-extreme data imbalance. These two methods are combined into a single data processing framework and is labeled as ``GICaPS'' to highlight the role of geometry-based information (GI) sampling and Class-Prioritized Synthesis (CaPS) in dealing with multi-class data imbalance problem, thereby making a novel contribution in this field.