 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRC-RL: A Novel Visual Feature Representation Architecture for Unsupervised Reinforcement Learning
Jan 31, 2023This paper addresses the problem of visual feature representation learning with an aim to improve the performance of end-to-end reinforcement learning (RL) models. Specifically, a novel architecture is proposed that uses a heterogeneous loss function, called CRC loss, to learn improved visual features which can then be used for policy learning in RL. The CRC-loss function is a combination of three individual loss functions, namely, contrastive, reconstruction and consistency loss. The feature representation is learned in parallel to the policy learning while sharing the weight updates through a Siamese Twin encoder model. This encoder model is augmented with a decoder network and a feature projection network to facilitate computation of the above loss components. Through empirical analysis involving latent feature visualization, an attempt is made to provide an insight into the role played by this loss function in learning new action-dependent features and how they are linked to the complexity of the problems being solved. The proposed architecture, called CRC-RL, is shown to outperform the existing state-of-the-art methods on the challenging Deep mind control suite environments by a significant margin thereby creating a new benchmark in this field.
A Method for Handling Multi-class Imbalanced Data by Geometry based Information Sampling and Class Prioritized Synthetic Data Generation
Oct 11, 2020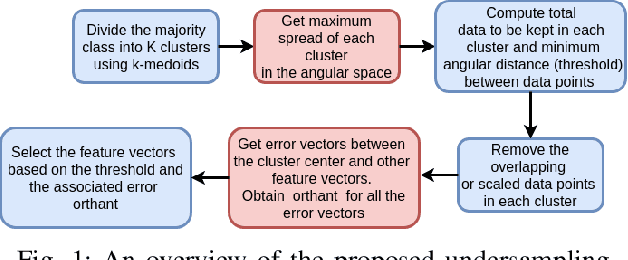
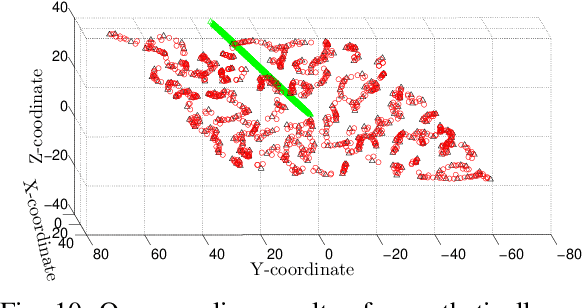
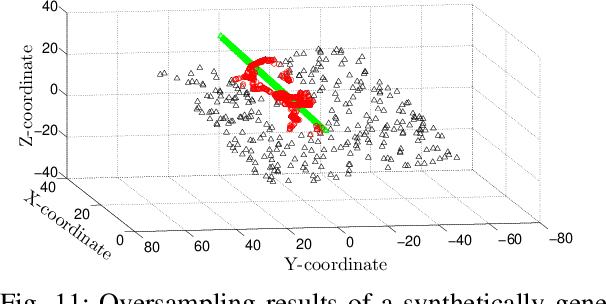
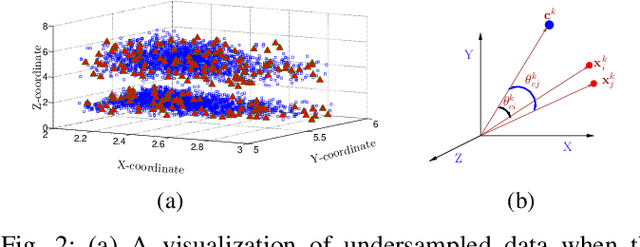
This paper looks into the problem of handling imbalanced data in a multi-label classification problem. The problem is solved by proposing two novel methods that primarily exploit the geometric relationship between the feature vectors. The first one is an undersampling algorithm that uses angle between feature vectors to select more informative samples while rejecting the less informative ones. A suitable criterion is proposed to define the informativeness of a given sample. The second one is an oversampling algorithm that uses a generative algorithm to create new synthetic data that respects all class boundaries. This is achieved by finding \emph{no man's land} based on Euclidean distance between the feature vectors. The efficacy of the proposed methods is analyzed by solving a generic multi-class recognition problem based on mixture of Gaussians. The superiority of the proposed algorithms is established through comparison with other state-of-the-art methods, including SMOTE and ADASYN, over ten different publicly available datasets exhibiting high-to-extreme data imbalance. These two methods are combined into a single data processing framework and is labeled as ``GICaPS'' to highlight the role of geometry-based information (GI) sampling and Class-Prioritized Synthesis (CaPS) in dealing with multi-class data imbalance problem, thereby making a novel contribution in this field.
Unsupervised Monocular Depth Estimation for Night-time Images using Adversarial Domain Feature Adaptation
Oct 03, 2020
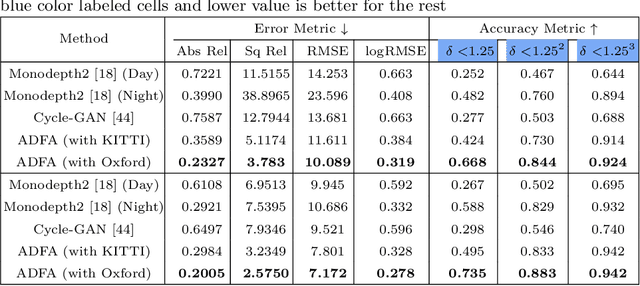
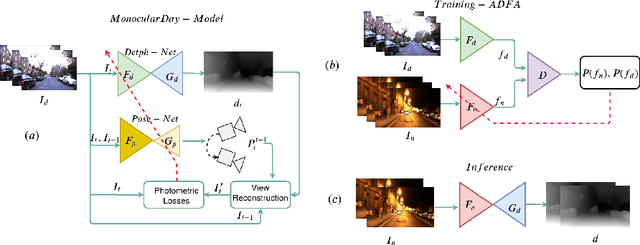
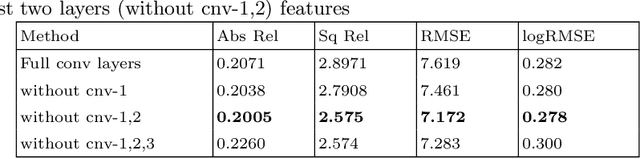
In this paper, we look into the problem of estimating per-pixel depth maps from unconstrained RGB monocular night-time images which is a difficult task that has not been addressed adequately in the literature. The state-of-the-art day-time depth estimation methods fail miserably when tested with night-time images due to a large domain shift between them. The usual photo metric losses used for training these networks may not work for night-time images due to the absence of uniform lighting which is commonly present in day-time images, making it a difficult problem to solve. We propose to solve this problem by posing it as a domain adaptation problem where a network trained with day-time images is adapted to work for night-time images. Specifically, an encoder is trained to generate features from night-time images that are indistinguishable from those obtained from day-time images by using a PatchGAN-based adversarial discriminative learning method. Unlike the existing methods that directly adapt depth prediction (network output), we propose to adapt feature maps obtained from the encoder network so that a pre-trained day-time depth decoder can be directly used for predicting depth from these adapted features. Hence, the resulting method is termed as "Adversarial Domain Feature Adaptation (ADFA)" and its efficacy is demonstrated through experimentation on the challenging Oxford night driving dataset. Also, The modular encoder-decoder architecture for the proposed ADFA method allows us to use the encoder module as a feature extractor which can be used in many other applications. One such application is demonstrated where the features obtained from our adapted encoder network are shown to outperform other state-of-the-art methods in a visual place recognition problem, thereby, further establishing the usefulness and effectiveness of the proposed approach.
UnDEMoN 2.0: Improved Depth and Ego Motion Estimation through Deep Image Sampling
Nov 27, 2018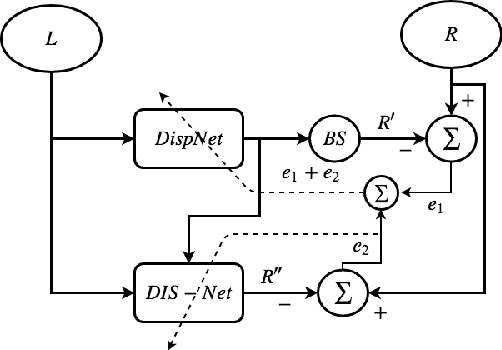
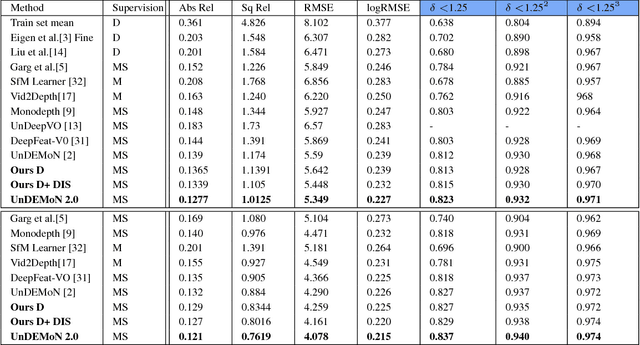


In this paper, we provide an improved version of UnDEMoN model for depth and ego motion estimation from monocular images. The improvement is achieved by combining the standard bi-linear sampler with a deep network based image sampling model (DIS-NET) to provide better image reconstruction capabilities on which the depth estimation accuracy depends in un-supervised learning models. While DIS-NET provides higher order regression and larger input search space, the bi-linear sampler provides geometric constraints necessary for reducing the size of the solution space for an ill-posed problem of this kind. This combination is shown to provide significant improvement in depth and pose estimation accuracy outperforming all existing state-of-the-art methods in this category. In addition, the modified network uses far less number of tunable parameters making it one of the lightest deep network model for depth estimation. The proposed model is labeled as "UnDEMoN 2.0" indicating an improvement over the existing UnDEMoN model. The efficacy of the proposed model is demonstrated through rigorous experimental analysis on the standard KITTI dataset.
A Deeper Insight into the UnDEMoN: Unsupervised Deep Network for Depth and Ego-Motion Estimation
Sep 10, 2018

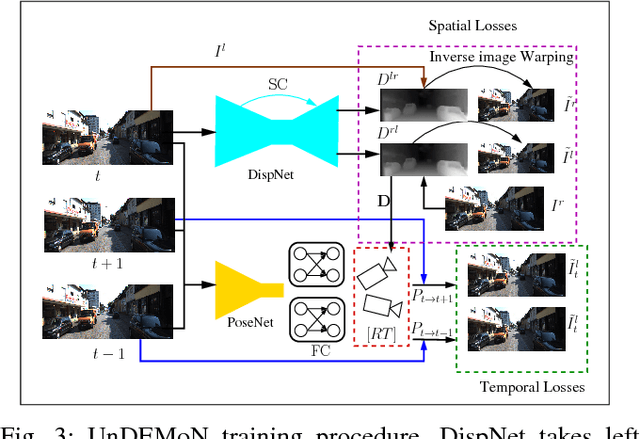
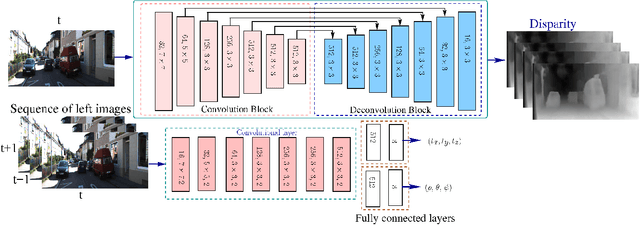
This paper presents an unsupervised deep learning framework called UnDEMoN for estimating dense depth map and 6-DoF camera pose information directly from monocular images. The proposed network is trained using unlabeled monocular stereo image pairs and is shown to provide superior performance in depth and ego-motion estimation compared to the existing state-of-the-art. These improvements are achieved by introducing a new objective function that aims to minimize spatial as well as temporal reconstruction losses simultaneously. These losses are defined using bi-linear sampling kernel and penalized using the Charbonnier penalty function. The objective function, thus created, provides robustness to image gradient noises thereby improving the overall estimation accuracy without resorting to any coarse to fine strategies which are currently prevalent in the literature. Another novelty lies in the fact that we combine a disparity-based depth estimation network with a pose estimation network to obtain absolute scale-aware 6 DOF Camera pose and superior depth map. The effectiveness of the proposed approach is demonstrated through performance comparison with the existing supervised and unsupervised methods on the KITTI driving dataset.
Design and Development of an automated Robotic Pick & Stow System for an e-Commerce Warehouse
Mar 07, 2017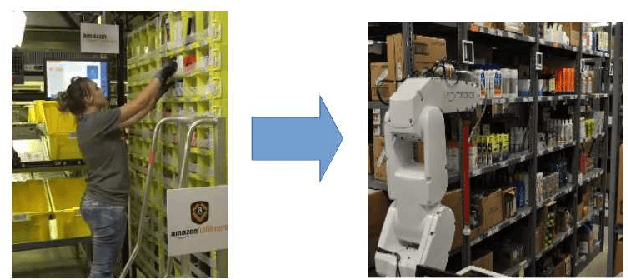
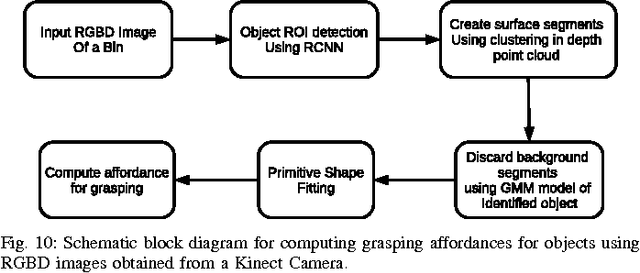
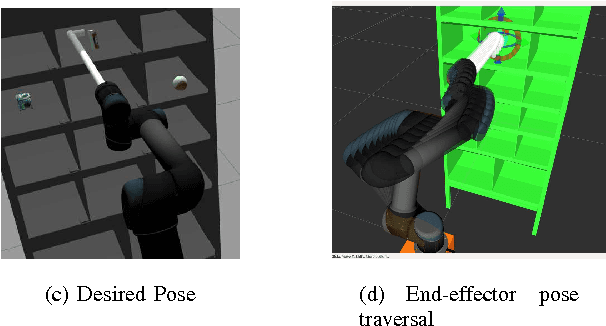
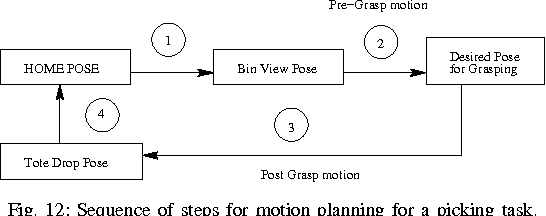
In this paper, we provide details of a robotic system that can automate the task of picking and stowing objects from and to a rack in an e-commerce fulfillment warehouse. The system primarily comprises of four main modules: (1) Perception module responsible for recognizing query objects and localizing them in the 3-dimensional robot workspace; (2) Planning module generates necessary paths that the robot end- effector has to take for reaching the objects in the rack or in the tote; (3) Calibration module that defines the physical workspace for the robot visible through the on-board vision system; and (4) Gripping and suction system for picking and stowing different kinds of objects. The perception module uses a faster region-based Convolutional Neural Network (R-CNN) to recognize objects. We designed a novel two finger gripper that incorporates pneumatic valve based suction effect to enhance its ability to pick different kinds of objects. The system was developed by IITK-TCS team for participation in the Amazon Picking Challenge 2016 event. The team secured a fifth place in the stowing task in the event. The purpose of this article is to share our experiences with students and practicing engineers and enable them to build similar systems. The overall efficacy of the system is demonstrated through several simulation as well as real-world experiments with actual robots.