 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatch or Replay: Self Imitating Proximal Policy Optimization
Mar 29, 2026Reinforcement Learning (RL) agents often struggle with inefficient exploration, particularly in environments with sparse rewards. Traditional exploration strategies can lead to slow learning and suboptimal performance because agents fail to systematically build on previously successful experiences, thereby reducing sample efficiency. To tackle this issue, we propose a self-imitating on-policy algorithm that enhances exploration and sample efficiency by leveraging past high-reward state-action pairs to guide policy updates. Our method incorporates self-imitation by using optimal transport distance in dense reward environments to prioritize state visitation distributions that match the most rewarding trajectory. In sparse-reward environments, we uniformly replay successful self-encountered trajectories to facilitate structured exploration. Experimental results across diverse environments demonstrate substantial improvements in learning efficiency, including MuJoCo for dense rewards and the partially observable 3D Animal-AI Olympics and multi-goal PointMaze for sparse rewards. Our approach achieves faster convergence and significantly higher success rates compared to state-of-the-art self-imitating RL baselines. These findings underscore the potential of self-imitation as a robust strategy for enhancing exploration in RL, with applicability to more complex tasks.
RoboSubtaskNet: Temporal Sub-task Segmentation for Human-to-Robot Skill Transfer in Real-World Environments
Feb 11, 2026Temporally locating and classifying fine-grained sub-task segments in long, untrimmed videos is crucial to safe human-robot collaboration. Unlike generic activity recognition, collaborative manipulation requires sub-task labels that are directly robot-executable. We present RoboSubtaskNet, a multi-stage human-to-robot sub-task segmentation framework that couples attention-enhanced I3D features (RGB plus optical flow) with a modified MS-TCN employing a Fibonacci dilation schedule to capture better short-horizon transitions such as reach-pick-place. The network is trained with a composite objective comprising cross-entropy and temporal regularizers (truncated MSE and a transition-aware term) to reduce over-segmentation and to encourage valid sub-task progressions. To close the gap between vision benchmarks and control, we introduce RoboSubtask, a dataset of healthcare and industrial demonstrations annotated at the sub-task level and designed for deterministic mapping to manipulator primitives. Empirically, RoboSubtaskNet outperforms MS-TCN and MS-TCN++ on GTEA and our RoboSubtask benchmark (boundary-sensitive and sequence metrics), while remaining competitive on the long-horizon Breakfast benchmark. Specifically, RoboSubtaskNet attains F1 @ 50 = 79.5%, Edit = 88.6%, Acc = 78.9% on GTEA; F1 @ 50 = 30.4%, Edit = 52.0%, Acc = 53.5% on Breakfast; and F1 @ 50 = 94.2%, Edit = 95.6%, Acc = 92.2% on RoboSubtask. We further validate the full perception-to-execution pipeline on a 7-DoF Kinova Gen3 manipulator, achieving reliable end-to-end behavior in physical trials (overall task success approx 91.25%). These results demonstrate a practical path from sub-task level video understanding to deployed robotic manipulation in real-world settings.
Instruct2Act: From Human Instruction to Actions Sequencing and Execution via Robot Action Network for Robotic Manipulation
Feb 10, 2026Robots often struggle to follow free-form human instructions in real-world settings due to computational and sensing limitations. We address this gap with a lightweight, fully on-device pipeline that converts natural-language commands into reliable manipulation. Our approach has two stages: (i) the instruction to actions module (Instruct2Act), a compact BiLSTM with a multi-head-attention autoencoder that parses an instruction into an ordered sequence of atomic actions (e.g., reach, grasp, move, place); and (ii) the robot action network (RAN), which uses the dynamic adaptive trajectory radial network (DATRN) together with a vision-based environment analyzer (YOLOv8) to generate precise control trajectories for each sub-action. The entire system runs on a modest system with no cloud services. On our custom proprietary dataset, Instruct2Act attains 91.5% sub-actions prediction accuracy while retaining a small footprint. Real-robot evaluations across four tasks (pick-place, pick-pour, wipe, and pick-give) yield an overall 90% success; sub-action inference completes in < 3.8s, with end-to-end executions in 30-60s depending on task complexity. These results demonstrate that fine-grained instruction-to-action parsing, coupled with DATRN-based trajectory generation and vision-guided grounding, provides a practical path to deterministic, real-time manipulation in resource-constrained, single-camera settings.
Dynamic Hand Gesture Recognition for Robot Manipulator Tasks
Jan 19, 2026This paper proposes a novel approach to recognizing dynamic hand gestures facilitating seamless interaction between humans and robots. Here, each robot manipulator task is assigned a specific gesture. There may be several such tasks, hence, several gestures. These gestures may be prone to several dynamic variations. All such variations for different gestures shown to the robot are accurately recognized in real-time using the proposed unsupervised model based on the Gaussian Mixture model. The accuracy during training and real-time testing prove the efficacy of this methodology.
TEACH: Temporal Variance-Driven Curriculum for Reinforcement Learning
Dec 28, 2025Reinforcement Learning (RL) has achieved significant success in solving single-goal tasks. However, uniform goal selection often results in sample inefficiency in multi-goal settings where agents must learn a universal goal-conditioned policy. Inspired by the adaptive and structured learning processes observed in biological systems, we propose a novel Student-Teacher learning paradigm with a Temporal Variance-Driven Curriculum to accelerate Goal-Conditioned RL. In this framework, the teacher module dynamically prioritizes goals with the highest temporal variance in the policy's confidence score, parameterized by the state-action value (Q) function. The teacher provides an adaptive and focused learning signal by targeting these high-uncertainty goals, fostering continual and efficient progress. We establish a theoretical connection between the temporal variance of Q-values and the evolution of the policy, providing insights into the method's underlying principles. Our approach is algorithm-agnostic and integrates seamlessly with existing RL frameworks. We demonstrate this through evaluation across 11 diverse robotic manipulation and maze navigation tasks. The results show consistent and notable improvements over state-of-the-art curriculum learning and goal-selection methods.
MOORL: A Framework for Integrating Offline-Online Reinforcement Learning
Jun 11, 2025



Sample efficiency and exploration remain critical challenges in Deep Reinforcement Learning (DRL), particularly in complex domains. Offline RL, which enables agents to learn optimal policies from static, pre-collected datasets, has emerged as a promising alternative. However, offline RL is constrained by issues such as out-of-distribution (OOD) actions that limit policy performance and generalization. To overcome these limitations, we propose Meta Offline-Online Reinforcement Learning (MOORL), a hybrid framework that unifies offline and online RL for efficient and scalable learning. While previous hybrid methods rely on extensive design components and added computational complexity to utilize offline data effectively, MOORL introduces a meta-policy that seamlessly adapts across offline and online trajectories. This enables the agent to leverage offline data for robust initialization while utilizing online interactions to drive efficient exploration. Our theoretical analysis demonstrates that the hybrid approach enhances exploration by effectively combining the complementary strengths of offline and online data. Furthermore, we demonstrate that MOORL learns a stable Q-function without added complexity. Extensive experiments on 28 tasks from the D4RL and V-D4RL benchmarks validate its effectiveness, showing consistent improvements over state-of-the-art offline and hybrid RL baselines. With minimal computational overhead, MOORL achieves strong performance, underscoring its potential for practical applications in real-world scenarios.
Thrust Microstepping via Acceleration Feedback in Quadrotor Control for Aerial Grasping of Dynamic Payload
Oct 08, 2024



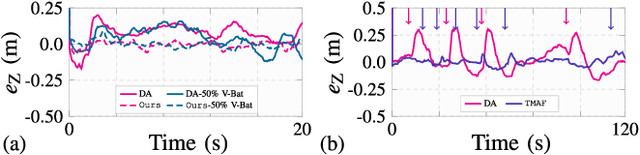
In this work, we propose an end-to-end Thrust Microstepping and Decoupled Control (TMDC) of quadrotors. TMDC focuses on precise off-centered aerial grasping of payloads dynamically, which are attached rigidly to the UAV body via a gripper contrary to the swinging payload. The dynamic payload grasping quickly changes UAV's mass, inertia etc, causing instability while performing a grasping operation in-air. We identify that to handle unknown payload grasping, the role of thrust controller is crucial. Hence, we focus on thrust control without involving system parameters such as mass etc. TMDC is based on our novel Thrust Microstepping via Acceleration Feedback (TMAF) thrust controller and Decoupled Motion Control (DMC). TMAF precisely estimates the desired thrust even at smaller loop rates while DMC decouples the horizontal and vertical motion to counteract disturbances in the case of dynamic payloads. We prove the controller's efficacy via exhaustive experiments in practically interesting and adverse real-world cases, such as fully onboard state estimation without any positioning sensor, narrow and indoor flying workspaces with intense wind turbulence, heavy payloads, non-uniform loop rates, etc. Our TMDC outperforms recent direct acceleration feedback thrust controller (DA) and geometric tracking control (GT) in flying stably for aerial grasping and achieves RMSE below 0.04m in contrast to 0.15m of DA and 0.16m of GT.
Design, Localization, Perception, and Control for GPS-Denied Autonomous Aerial Grasping and Harvesting
Oct 08, 2024
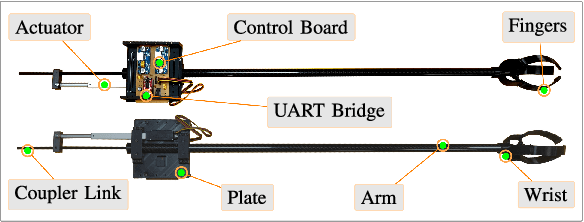
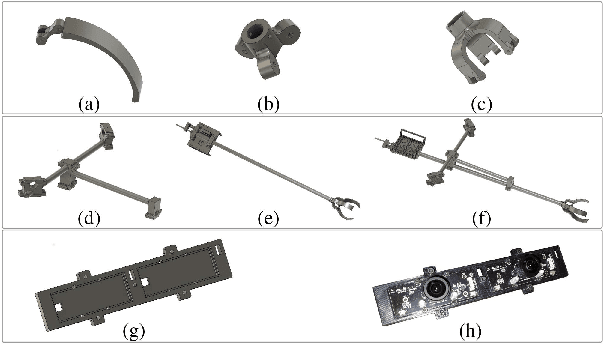
In this paper, we present a comprehensive UAV system design to perform the highly complex task of off-centered aerial grasping. This task has several interdisciplinary research challenges which need to be addressed at once. The main design challenges are GPS-denied functionality, solely onboard computing, and avoiding off-the-shelf costly positioning systems. While in terms of algorithms, visual perception, localization, control, and grasping are the leading research problems. Hence in this paper, we make interdisciplinary contributions: (i) A detailed description of the fundamental challenges in indoor aerial grasping, (ii) a novel lightweight gripper design, (iii) a complete aerial platform design and in-lab fabrication, and (iv) localization, perception, control, grasping systems, and an end-to-end flight autonomy state-machine. Finally, we demonstrate the resulting aerial grasping system Drone-Bee achieving a high grasping rate for a highly challenging agricultural task of apple-like fruit harvesting, indoors in a vertical farming setting (Fig. 1). To our knowledge, such a system has not been previously discussed in the literature, and with its capabilities, this system pushes aerial manipulation towards 4th generation.
High-Speed Stereo Visual SLAM for Low-Powered Computing Devices
Oct 05, 2024We present an accurate and GPU-accelerated Stereo Visual SLAM design called Jetson-SLAM. It exhibits frame-processing rates above 60FPS on NVIDIA's low-powered 10W Jetson-NX embedded computer and above 200FPS on desktop-grade 200W GPUs, even in stereo configuration and in the multiscale setting. Our contributions are threefold: (i) a Bounded Rectification technique to prevent tagging many non-corner points as a corner in FAST detection, improving SLAM accuracy. (ii) A novel Pyramidal Culling and Aggregation (PyCA) technique that yields robust features while suppressing redundant ones at high speeds by harnessing a GPU device. PyCA uses our new Multi-Location Per Thread culling strategy (MLPT) and Thread-Efficient Warp-Allocation (TEWA) scheme for GPU to enable Jetson-SLAM achieving high accuracy and speed on embedded devices. (iii) Jetson-SLAM library achieves resource efficiency by having a data-sharing mechanism. Our experiments on three challenging datasets: KITTI, EuRoC, and KAIST-VIO, and two highly accurate SLAM backends: Full-BA and ICE-BA show that Jetson-SLAM is the fastest available accurate and GPU-accelerated SLAM system (Fig. 1).
Pick-or-Mix: Dynamic Channel Sampling for ConvNets
Jun 16, 2024



Channel pruning approaches for convolutional neural networks (ConvNets) deactivate the channels, statically or dynamically, and require special implementation. In addition, channel squeezing in representative ConvNets is carried out via 1x1 convolutions which dominates a large portion of computations and network parameters. Given these challenges, we propose an effective multi-purpose module for dynamic channel sampling, namely Pick-or-Mix (PiX), which does not require special implementation. PiX divides a set of channels into subsets and then picks from them, where the picking decision is dynamically made per each pixel based on the input activations. We plug PiX into prominent ConvNet architectures and verify its multi-purpose utilities. After replacing 1x1 channel squeezing layers in ResNet with PiX, the network becomes 25% faster without losing accuracy. We show that PiX allows ConvNets to learn better data representation than widely adopted approaches to enhance networks' representation power (e.g., SE, CBAM, AFF, SKNet, and DWP). We also show that PiX achieves state-of-the-art performance on network downscaling and dynamic channel pruning applications.
* Published in Computer Vision and Pattern Recognition (CVPR 2024)