 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Behavior in Multimodal LLMs Across Agricultural Image Interpretation and Generation Tasks
May 26, 2026Large Language Models (LLMs) are being rapidly adopted in agricultural imaging applications, ranging from crop interpretation to synthetic field image generation. However, these models frequently exhibit hallucinations outputs that appear confident yet deviate from biological or environmental reality potentially leading to misinformed agronomic insights. This study investigates such hallucinations in two complementary directions: image-to-text, where LLMs interpret crop or field imagery to describe conditions such as biotic and abiotic stresses, and text-to-image, where models generate synthetic agricultural scenes based on descriptive prompts. We examine errors involving biological inconsistency, contextual inaccuracy, and agronomic implausibility, evaluating the outputs under domain-informed criteria across multiple imaging modalities. Our analysis identifies recurring hallucination patterns within both interpretive and generative tasks. In image interpretation, LLMs (e.g., Gemma, LLAVA, Qwen, and MiniCPM) achieved modest zero-shot accuracy (63 to 75 percent), whereas few-shot prompting improved performance up to 86.8 percent, exhibiting false detections and missed infections, indicating residual hallucination effects. In text-to-image tasks, advanced models such as GPT-5 and Gemini 2.5 Flash generate up to 91 percent biologically inconsistent scenes under relaxed prompt constraints, revealing fundamental weaknesses in current LLMs. This systematic assessment of visual reasoning and generation offers critical insights toward enhancing the reliability and trustworthiness of LLM-based agricultural imaging platforms.
Robotic Strawberry Harvesting with Robust Vision and Deep Reinforcement Learning based Sim-to-Real Control
May 22, 2026This study presents a closed-loop robotic strawberry harvesting system that combines a robust vision module, simulation-trained deep reinforcement learning (DRL) control, and ROS-based realrobot execution. For perception, we propose HRAttnEdge-YOLO26-seg, a modified YOLO26-seg architecture that incorporates a high-resolution P2 branch, segmentation-path attention, and edgesupervised prototype learning to improve instance segmentation in cluttered scenes. For control, we train a target-conditioned Proximal Policy Optimization (PPO) policy in Isaac Lab to produce smooth joint-position commands for a UR10e manipulator and deploy it on a UR10e robot for targetfruit reaching and harvesting. This simulation-based approach reduces hardware dependency, lowers development cost, and allows scalable policy training without exhaustive physical trials before real deployment. The proposed vision model demonstrated the highest overall performance among the evaluated methods. On both self-collected and public datasets, the model showed a 10 to 14% improvement in segmentation performance. In controlled in-house tests, the PPO controller produced stable and dynamically smoother motion than a inverse kinematics (IK)-based MoveIt baseline. In greenhouse trials, the proposed integrated system harvested 281 strawberries, achieving 96.6% reaching success, 91.3% grasp-and-pull success, and 84.3% overall harvesting success. These results illustrate that task-specific perception combined with simulation-trained PPO can serve as a practical and resource-efficient alternative to conventional planner-dependent reaching in manipulation, enabling reliable closed-loop robotic harvesting in complex agricultural environments.
Bin-picking of novel objects through category-agnostic-segmentation: RGB matters
Dec 27, 2023
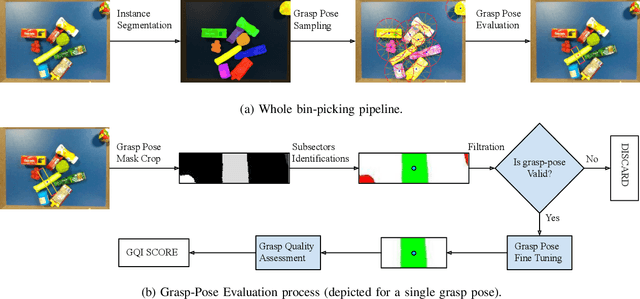
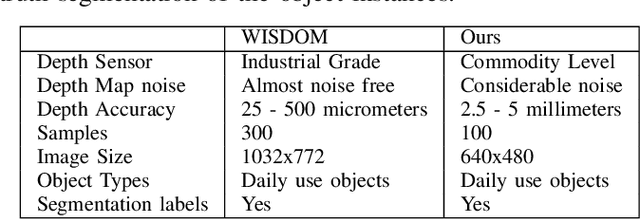
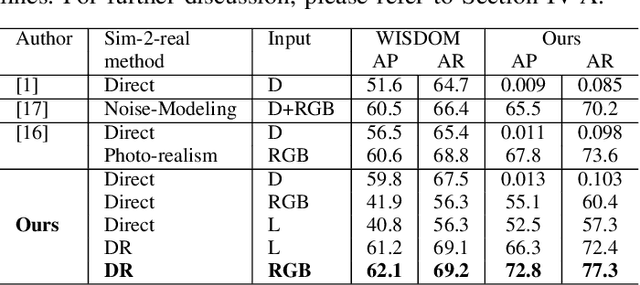
This paper addresses category-agnostic instance segmentation for robotic manipulation, focusing on segmenting objects independent of their class to enable versatile applications like bin-picking in dynamic environments. Existing methods often lack generalizability and object-specific information, leading to grasp failures. We present a novel approach leveraging object-centric instance segmentation and simulation-based training for effective transfer to real-world scenarios. Notably, our strategy overcomes challenges posed by noisy depth sensors, enhancing the reliability of learning. Our solution accommodates transparent and semi-transparent objects which are historically difficult for depth-based grasping methods. Contributions include domain randomization for successful transfer, our collected dataset for warehouse applications, and an integrated framework for efficient bin-picking. Our trained instance segmentation model achieves state-of-the-art performance over WISDOM public benchmark [1] and also over the custom-created dataset. In a real-world challenging bin-picking setup our bin-picking framework method achieves 98% accuracy for opaque objects and 97% accuracy for non-opaque objects, outperforming the state-of-the-art baselines with a greater margin.
Domain-Independent Disperse and Pick method for Robotic Grasping
Dec 19, 2023Picking unseen objects from clutter is a difficult problem because of the variability in objects (shape, size, and material) and occlusion due to clutter. As a result, it becomes difficult for grasping methods to segment the objects properly and they fail to singulate the object to be picked. This may result in grasp failure or picking of multiple objects together in a single attempt. A push-to-move action by the robot will be beneficial to disperse the objects in the workspace and thus assist the grasping and vision algorithm. We propose a disperse and pick method for domain-independent robotic grasping in a highly cluttered heap of objects. The novel contribution of our framework is the introduction of a heuristic clutter removal method that does not require deep learning and can work on unseen objects. At each iteration of the algorithm, the robot either performs a push-to-move action or a grasp action based on the estimated clutter profile. For grasp planning, we present an improved and adaptive version of a recent domain-independent grasping method. The efficacy of the integrated system is demonstrated in simulation as well as in the real-world.
* Published at 2022 International Joint Conference on Neural Networks (IJCNN)
Learning to Switch CNNs with Model Agnostic Meta Learning for Fine Precision Visual Servoing
Jul 09, 2020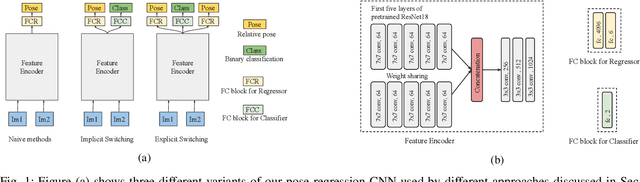

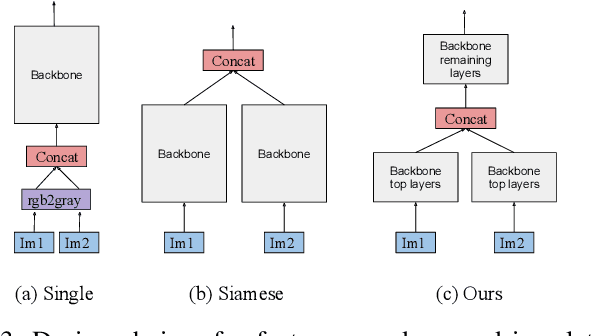
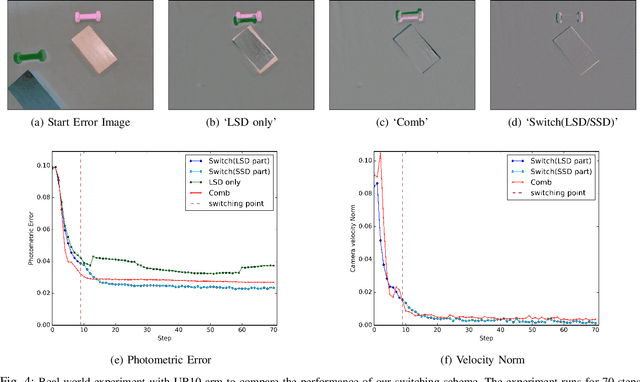
Convolutional Neural Networks (CNNs) have been successfully applied for relative camera pose estimation from labeled image-pair data, without requiring any hand-engineered features, camera intrinsic parameters or depth information. The trained CNN can be utilized for performing pose based visual servo control (PBVS). One of the ways to improve the quality of visual servo output is to improve the accuracy of the CNN for estimating the relative pose estimation. With a given state-of-the-art CNN for relative pose regression, how can we achieve an improved performance for visual servo control? In this paper, we explore switching of CNNs to improve the precision of visual servo control. The idea of switching a CNN is due to the fact that the dataset for training a relative camera pose regressor for visual servo control must contain variations in relative pose ranging from a very small scale to eventually a larger scale. We found that, training two different instances of the CNN, one for large-scale-displacements (LSD) and another for small-scale-displacements (SSD) and switching them during the visual servo execution yields better results than training a single CNN with the combined LSD+SSD data. However, it causes extra storage overhead and switching decision is taken by a manually set threshold which may not be optimal for all the scenes. To eliminate these drawbacks, we propose an efficient switching strategy based on model agnostic meta learning (MAML) algorithm. In this, a single model is trained to learn parameters which are simultaneously good for multiple tasks, namely a binary classification for switching decision, a 6DOF pose regression for LSD data and also a 6DOF pose regression for SSD data. The proposed approach performs far better than the naive approach, while storage and run-time overheads are almost negligible.