 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Independent Disperse and Pick method for Robotic Grasping
Dec 19, 2023Picking unseen objects from clutter is a difficult problem because of the variability in objects (shape, size, and material) and occlusion due to clutter. As a result, it becomes difficult for grasping methods to segment the objects properly and they fail to singulate the object to be picked. This may result in grasp failure or picking of multiple objects together in a single attempt. A push-to-move action by the robot will be beneficial to disperse the objects in the workspace and thus assist the grasping and vision algorithm. We propose a disperse and pick method for domain-independent robotic grasping in a highly cluttered heap of objects. The novel contribution of our framework is the introduction of a heuristic clutter removal method that does not require deep learning and can work on unseen objects. At each iteration of the algorithm, the robot either performs a push-to-move action or a grasp action based on the estimated clutter profile. For grasp planning, we present an improved and adaptive version of a recent domain-independent grasping method. The efficacy of the integrated system is demonstrated in simulation as well as in the real-world.
* Published at 2022 International Joint Conference on Neural Networks (IJCNN)
Towards Deep Learning Assisted Autonomous UAVs for Manipulation Tasks in GPS-Denied Environments
Jan 16, 2021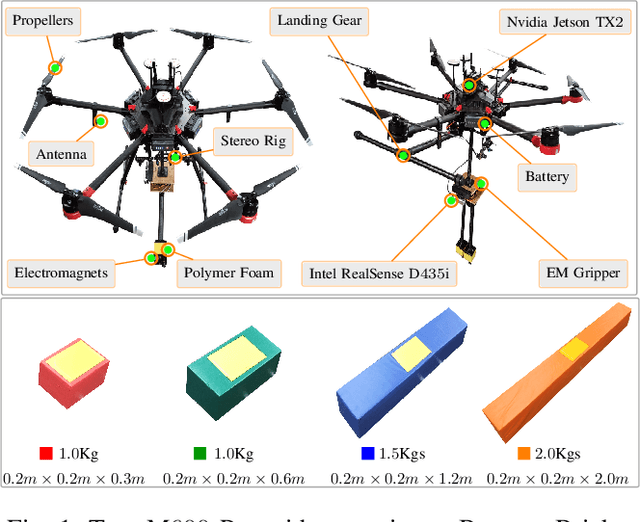

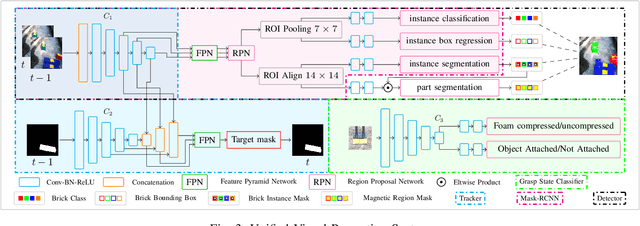
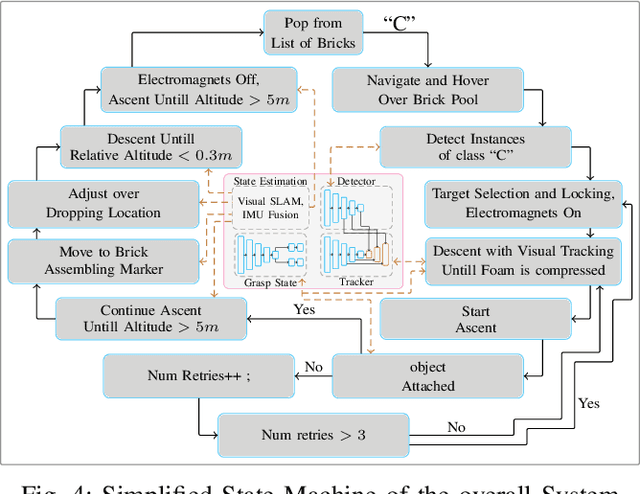
In this work, we present a pragmatic approach to enable unmanned aerial vehicle (UAVs) to autonomously perform highly complicated tasks of object pick and place. This paper is largely inspired by challenge-2 of MBZIRC 2020 and is primarily focused on the task of assembling large 3D structures in outdoors and GPS-denied environments. Primary contributions of this system are: (i) a novel computationally efficient deep learning based unified multi-task visual perception system for target localization, part segmentation, and tracking, (ii) a novel deep learning based grasp state estimation, (iii) a retracting electromagnetic gripper design, (iv) a remote computing approach which exploits state-of-the-art MIMO based high speed (5000Mb/s) wireless links to allow the UAVs to execute compute intensive tasks on remote high end compute servers, and (v) system integration in which several system components are weaved together in order to develop an optimized software stack. We use DJI Matrice-600 Pro, a hex-rotor UAV and interface it with the custom designed gripper. Our framework is deployed on the specified UAV in order to report the performance analysis of the individual modules. Apart from the manipulation system, we also highlight several hidden challenges associated with the UAVs in this context.
Shape Back-Projection In 3D Scenes
Jan 16, 2021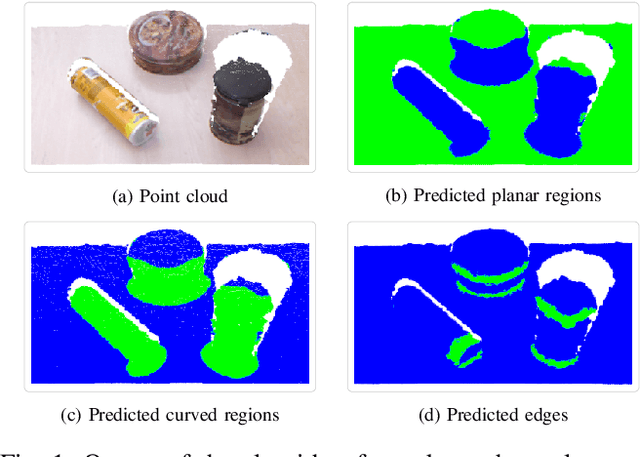
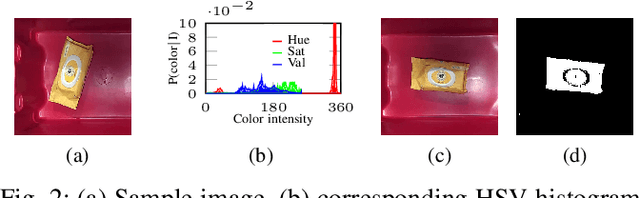
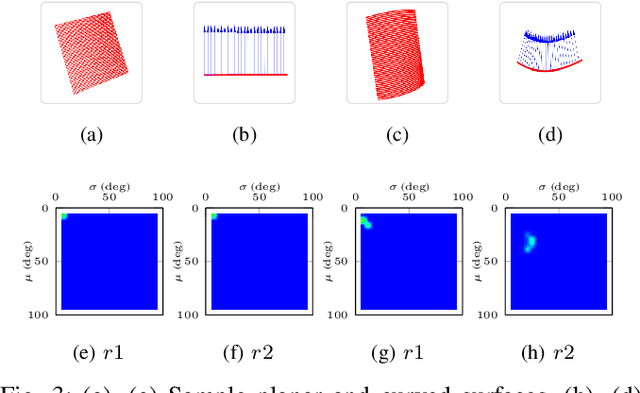

In this work, we propose a novel framework shape back-projection for computationally efficient point cloud processing in a probabilistic manner. The primary component of the technique is shape histogram and a back-projection procedure. The technique measures similarity between 3D surfaces, by analyzing their geometrical properties. It is analogous to color back-projection which measures similarity between images, simply by looking at their color distributions. In the overall process, first, shape histogram of a sample surface (e.g. planar) is computed, which captures the profile of surface normals around a point in form of a probability distribution. Later, the histogram is back-projected onto a test surface and a likelihood score is obtained. The score depicts that how likely a point in the test surface behaves similar to the sample surface, geometrically. Shape back-projection finds its application in binary surface classification, high curvature edge detection in unorganized point cloud, automated point cloud labeling for 3D-CNNs (convolutional neural network) etc. The algorithm can also be used for real-time robotic operations such as autonomous object picking in warehouse automation, ground plane extraction for autonomous vehicles and can be deployed easily on computationally limited platforms (UAVs).
Semi Supervised Deep Quick Instance Detection and Segmentation
Jan 16, 2021
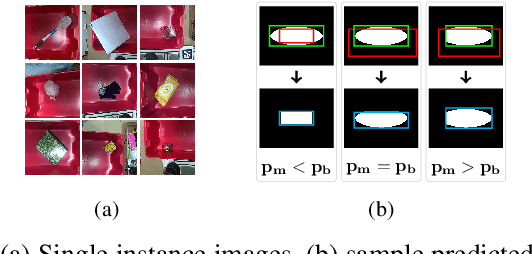


In this paper, we present a semi supervised deep quick learning framework for instance detection and pixel-wise semantic segmentation of images in a dense clutter of items. The framework can quickly and incrementally learn novel items in an online manner by real-time data acquisition and generating corresponding ground truths on its own. To learn various combinations of items, it can synthesize cluttered scenes, in real time. The overall approach is based on the tutor-child analogy in which a deep network (tutor) is pretrained for class-agnostic object detection which generates labeled data for another deep network (child). The child utilizes a customized convolutional neural network head for the purpose of quick learning. There are broadly four key components of the proposed framework semi supervised labeling, occlusion aware clutter synthesis, a customized convolutional neural network head, and instance detection. The initial version of this framework was implemented during our participation in Amazon Robotics Challenge (ARC), 2017. Our system was ranked 3rd, 4th and 5th worldwide in pick, stow-pick and stow task respectively. The proposed framework is an improved version over ARC17 where novel features such as instance detection and online learning has been added.
Learning to Switch CNNs with Model Agnostic Meta Learning for Fine Precision Visual Servoing
Jul 09, 2020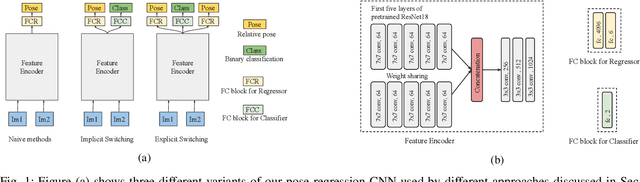

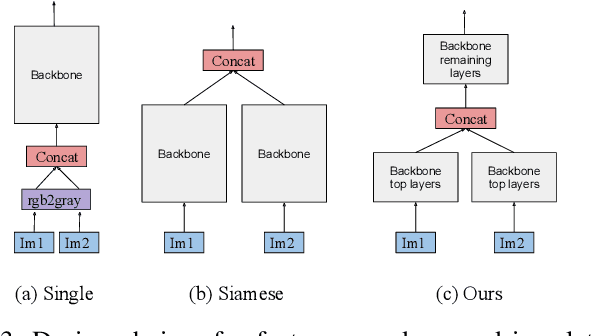
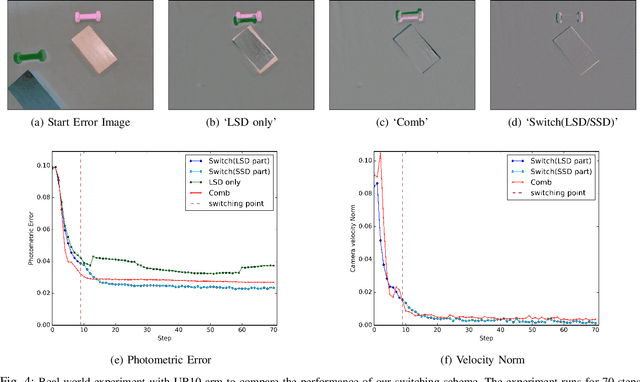
Convolutional Neural Networks (CNNs) have been successfully applied for relative camera pose estimation from labeled image-pair data, without requiring any hand-engineered features, camera intrinsic parameters or depth information. The trained CNN can be utilized for performing pose based visual servo control (PBVS). One of the ways to improve the quality of visual servo output is to improve the accuracy of the CNN for estimating the relative pose estimation. With a given state-of-the-art CNN for relative pose regression, how can we achieve an improved performance for visual servo control? In this paper, we explore switching of CNNs to improve the precision of visual servo control. The idea of switching a CNN is due to the fact that the dataset for training a relative camera pose regressor for visual servo control must contain variations in relative pose ranging from a very small scale to eventually a larger scale. We found that, training two different instances of the CNN, one for large-scale-displacements (LSD) and another for small-scale-displacements (SSD) and switching them during the visual servo execution yields better results than training a single CNN with the combined LSD+SSD data. However, it causes extra storage overhead and switching decision is taken by a manually set threshold which may not be optimal for all the scenes. To eliminate these drawbacks, we propose an efficient switching strategy based on model agnostic meta learning (MAML) algorithm. In this, a single model is trained to learn parameters which are simultaneously good for multiple tasks, namely a binary classification for switching decision, a 6DOF pose regression for LSD data and also a 6DOF pose regression for SSD data. The proposed approach performs far better than the naive approach, while storage and run-time overheads are almost negligible.