 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePalpAid: Multimodal Pneumatic Tactile Sensor for Tissue Palpation
Dec 22, 2025The tactile properties of tissue, such as elasticity and stiffness, often play an important role in surgical oncology when identifying tumors and pathological tissue boundaries. Though extremely valuable, robot-assisted surgery comes at the cost of reduced sensory information to the surgeon; typically, only vision is available. Sensors proposed to overcome this sensory desert are often bulky, complex, and incompatible with the surgical workflow. We present PalpAid, a multimodal pneumatic tactile sensor equipped with a microphone and pressure sensor, converting contact force into an internal pressure differential. The pressure sensor acts as an event detector, while the auditory signature captured by the microphone assists in tissue delineation. We show the design, fabrication, and assembly of sensory units with characterization tests to show robustness to use, inflation-deflation cycles, and integration with a robotic system. Finally, we show the sensor's ability to classify 3D-printed hard objects with varying infills and soft ex vivo tissues. Overall, PalpAid aims to fill the sensory gap intelligently and allow improved clinical decision-making.
V-OCBF: Learning Safety Filters from Offline Data via Value-Guided Offline Control Barrier Functions
Dec 11, 2025Ensuring safety in autonomous systems requires controllers that satisfy hard, state-wise constraints without relying on online interaction. While existing Safe Offline RL methods typically enforce soft expected-cost constraints, they do not guarantee forward invariance. Conversely, Control Barrier Functions (CBFs) provide rigorous safety guarantees but usually depend on expert-designed barrier functions or full knowledge of the system dynamics. We introduce Value-Guided Offline Control Barrier Functions (V-OCBF), a framework that learns a neural CBF entirely from offline demonstrations. Unlike prior approaches, V-OCBF does not assume access to the dynamics model; instead, it derives a recursive finite-difference barrier update, enabling model-free learning of a barrier that propagates safety information over time. Moreover, V-OCBF incorporates an expectile-based objective that avoids querying the barrier on out-of-distribution actions and restricts updates to the dataset-supported action set. The learned barrier is then used with a Quadratic Program (QP) formulation to synthesize real-time safe control. Across multiple case studies, V-OCBF yields substantially fewer safety violations than baseline methods while maintaining strong task performance, highlighting its scalability for offline synthesis of safety-critical controllers without online interaction or hand-engineered barriers.
TumorMap: A Laser-based Surgical Platform for 3D Tumor Mapping and Fully-Automated Tumor Resection
Nov 07, 2025Surgical resection of malignant solid tumors is critically dependent on the surgeon's ability to accurately identify pathological tissue and remove the tumor while preserving surrounding healthy structures. However, building an intraoperative 3D tumor model for subsequent removal faces major challenges due to the lack of high-fidelity tumor reconstruction, difficulties in developing generalized tissue models to handle the inherent complexities of tumor diagnosis, and the natural physical limitations of bimanual operation, physiologic tremor, and fatigue creep during surgery. To overcome these challenges, we introduce "TumorMap", a surgical robotic platform to formulate intraoperative 3D tumor boundaries and achieve autonomous tissue resection using a set of multifunctional lasers. TumorMap integrates a three-laser mechanism (optical coherence tomography, laser-induced endogenous fluorescence, and cutting laser scalpel) combined with deep learning models to achieve fully-automated and noncontact tumor resection. We validated TumorMap in murine osteoscarcoma and soft-tissue sarcoma tumor models, and established a novel histopathological workflow to estimate sensor performance. With submillimeter laser resection accuracy, we demonstrated multimodal sensor-guided autonomous tumor surgery without any human intervention.
Impedance Primitive-augmented Hierarchical Reinforcement Learning for Sequential Tasks
Aug 27, 2025This paper presents an Impedance Primitive-augmented hierarchical reinforcement learning framework for efficient robotic manipulation in sequential contact tasks. We leverage this hierarchical structure to sequentially execute behavior primitives with variable stiffness control capabilities for contact tasks. Our proposed approach relies on three key components: an action space enabling variable stiffness control, an adaptive stiffness controller for dynamic stiffness adjustments during primitive execution, and affordance coupling for efficient exploration while encouraging compliance. Through comprehensive training and evaluation, our framework learns efficient stiffness control capabilities and demonstrates improvements in learning efficiency, compositionality in primitive selection, and success rates compared to the state-of-the-art. The training environments include block lifting, door opening, object pushing, and surface cleaning. Real world evaluations further confirm the framework's sim2real capability. This work lays the foundation for more adaptive and versatile robotic manipulation systems, with potential applications in more complex contact-based tasks.
OVITA: Open-Vocabulary Interpretable Trajectory Adaptations
Aug 24, 2025Adapting trajectories to dynamic situations and user preferences is crucial for robot operation in unstructured environments with non-expert users. Natural language enables users to express these adjustments in an interactive manner. We introduce OVITA, an interpretable, open-vocabulary, language-driven framework designed for adapting robot trajectories in dynamic and novel situations based on human instructions. OVITA leverages multiple pre-trained Large Language Models (LLMs) to integrate user commands into trajectories generated by motion planners or those learned through demonstrations. OVITA employs code as an adaptation policy generated by an LLM, enabling users to adjust individual waypoints, thus providing flexible control. Another LLM, which acts as a code explainer, removes the need for expert users, enabling intuitive interactions. The efficacy and significance of the proposed OVITA framework is demonstrated through extensive simulations and real-world environments with diverse tasks involving spatiotemporal variations on heterogeneous robotic platforms such as a KUKA IIWA robot manipulator, Clearpath Jackal ground robot, and CrazyFlie drone.
Trajectory Adaptation using Large Language Models
Apr 17, 2025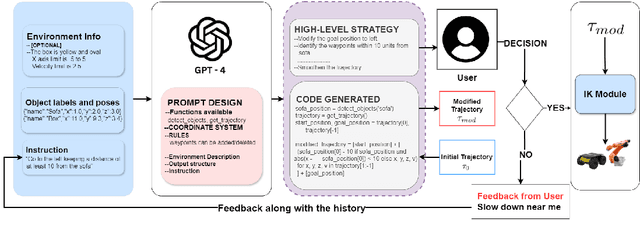
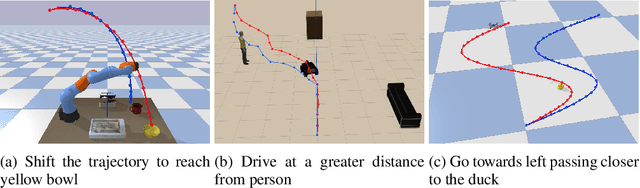
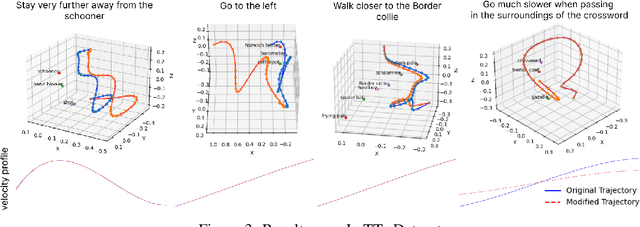
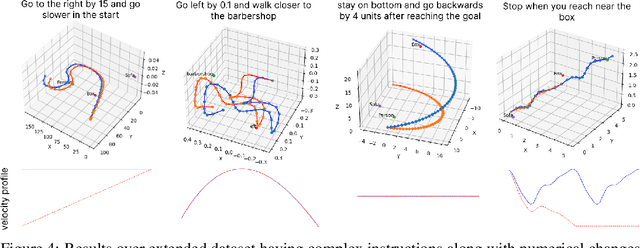
Adapting robot trajectories based on human instructions as per new situations is essential for achieving more intuitive and scalable human-robot interactions. This work proposes a flexible language-based framework to adapt generic robotic trajectories produced by off-the-shelf motion planners like RRT, A-star, etc, or learned from human demonstrations. We utilize pre-trained LLMs to adapt trajectory waypoints by generating code as a policy for dense robot manipulation, enabling more complex and flexible instructions than current methods. This approach allows us to incorporate a broader range of commands, including numerical inputs. Compared to state-of-the-art feature-based sequence-to-sequence models which require training, our method does not require task-specific training and offers greater interpretability and more effective feedback mechanisms. We validate our approach through simulation experiments on the robotic manipulator, aerial vehicle, and ground robot in the Pybullet and Gazebo simulation environments, demonstrating that LLMs can successfully adapt trajectories to complex human instructions.
GenOSIL: Generalized Optimal and Safe Robot Control using Parameter-Conditioned Imitation Learning
Mar 15, 2025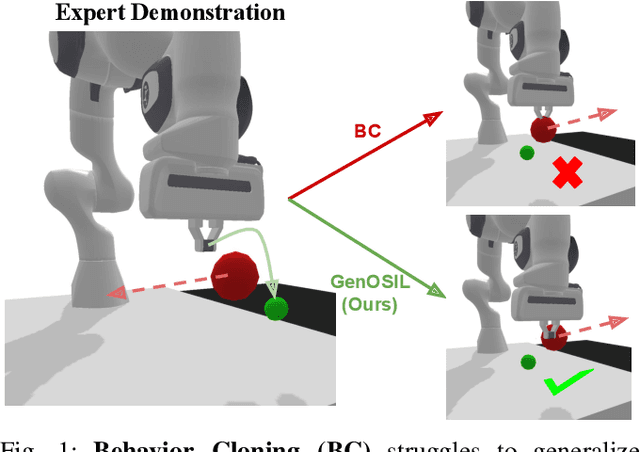
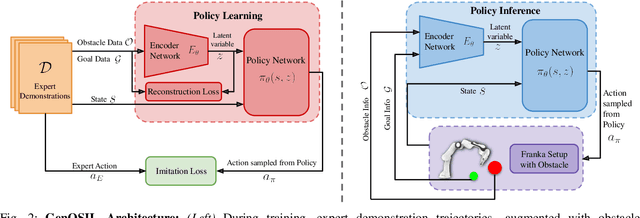
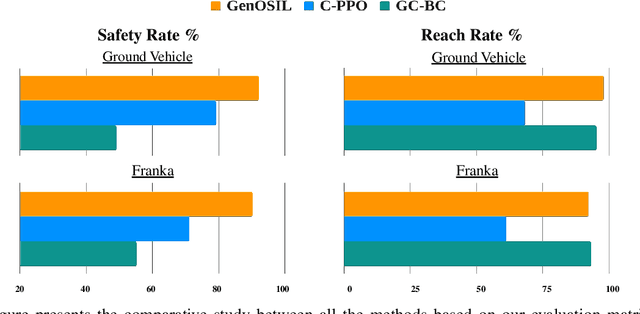
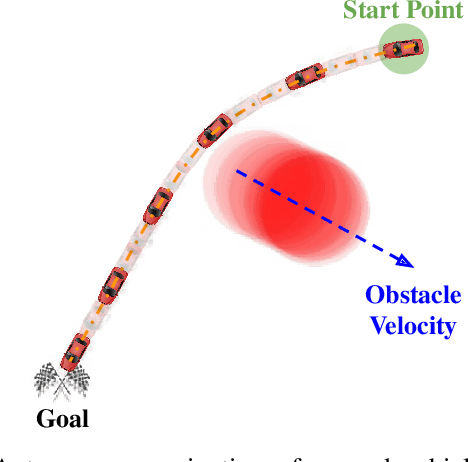
Ensuring safe and generalizable control remains a fundamental challenge in robotics, particularly when deploying imitation learning in dynamic environments. Traditional behavior cloning (BC) struggles to generalize beyond its training distribution, as it lacks an understanding of the safety critical reasoning behind expert demonstrations. To address this limitation, we propose GenOSIL, a novel imitation learning framework that explicitly incorporates environment parameters into policy learning via a structured latent representation. Unlike conventional methods that treat the environment as a black box, GenOSIL employs a variational autoencoder (VAE) to encode measurable safety parameters such as obstacle position, velocity, and geometry into a latent space that captures intrinsic correlations between expert behavior and environmental constraints. This enables the policy to infer the rationale behind expert trajectories rather than merely replicating them. We validate our approach on two robotic platforms an autonomous ground vehicle and a Franka Emika Panda manipulator demonstrating superior safety and goal reaching performance compared to baseline methods. The simulation and hardware videos can be viewed on the project webpage: https://mumukshtayal.github.io/GenOSIL/.
Towards Secure AI-driven Industrial Metaverse with NFT Digital Twins
Dec 20, 2024



The rise of the industrial metaverse has brought digital twins (DTs) to the forefront. Blockchain-powered non-fungible tokens (NFTs) offer a decentralized approach to creating and owning these cloneable DTs. However, the potential for unauthorized duplication, or counterfeiting, poses a significant threat to the security of NFT-DTs. Existing NFT clone detection methods often rely on static information like metadata and images, which can be easily manipulated. To address these limitations, we propose a novel deep-learning-based solution as a combination of an autoencoder and RNN-based classifier. This solution enables real-time pattern recognition to detect fake NFT-DTs. Additionally, we introduce the concept of dynamic metadata, providing a more reliable way to verify authenticity through AI-integrated smart contracts. By effectively identifying counterfeit DTs, our system contributes to strengthening the security of NFT-based assets in the metaverse.
Design and Evaluation of a Compliant Quasi Direct Drive End-effector for Safe Robotic Ultrasound Imaging
Oct 04, 2024Robot-assisted ultrasound scanning promises to advance autonomous and accessible medical imaging. However, ensuring patient safety and compliant human-robot interaction (HRI) during probe contact poses a significant challenge. Most existing systems either have high mechanical stiffness or are compliant but lack sufficient force and precision. This paper presents a novel single-degree-of-freedom end-effector for safe and accurate robotic ultrasound imaging, using a quasi-direct drive actuator to achieve both passive mechanical compliance and precise active force regulation, even during motion. The end-effector demonstrates an effective force control bandwidth of 100 Hz and can apply forces ranging from 2.5N to 15N. To validate the end-effector's performance, we developed a novel ex vivo actuating platform, enabling compliance testing of the end-effector on simulated abdominal breathing and sudden patient movements. Experiments demonstrate that the end-effector can maintain consistent probe contact during simulated respiratory motion at 2.5N, 5N, 10N, and 15N, with an average force tracking RMS error of 0.83N compared to 4.70N on a UR3e robot arm using conventional force control. This system represents the first compliant ultrasound end-effector tested on a tissue platform simulating dynamic movement. The proposed solution provides a novel approach for designing and evaluating compliant robotic ultrasound systems, advancing the path for more compliant and patient-friendly robotic ultrasound systems in clinical settings.
Sampling-Based Model Predictive Control for Volumetric Ablation in Robotic Laser Surgery
Oct 04, 2024



Laser-based surgical ablation relies heavily on surgeon involvement, restricting precision to the limits of human error. The interaction between laser and tissue is governed by various laser parameters that control the laser irradiance on the tissue, including the laser power, distance, spot size, orientation, and exposure time. This complex interaction lends itself to robotic automation, allowing the surgeon to focus on high-level tasks, such as choosing the region and method of ablation, while the lower-level ablation plan can be handled autonomously. This paper describes a sampling-based model predictive control (MPC) scheme to plan ablation sequences for arbitrary tissue volumes. Using a steady-state point ablation model to simulate a single laser-tissue interaction, a random search technique explores the reachable state space while preserving sensitive tissue regions. The sampled MPC strategy provides an ablation sequence that accounts for parameter uncertainty without violating constraints, such as avoiding critical nerve bundles or blood vessels.