 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
Jun 01, 2026Parameter-efficient fine-tuning (PEFT) is usually treated as a cheaper alternative to full fine-tuning. We study a broader role: small trainable adapters as persistent local state on top of strong shared foundation models. In this framing, the base model provides shared competence while adapters carry instance-specific behavior such as preferences, skills, tool habits, and memory-like updates. We organize the problem around three scaling axes: Scale Up, where stronger shared priors make small local updates more useful; Scale Down, where we study how small adapters can be while remaining reliable; and Scale Out, where many persistent adapted instances coexist. MinT provides one infrastructure example for managing adapter identity, revision, provenance, evaluation, and serving residency. Together, the results suggest that PEFT can be a compact substrate for persistent personal models rather than only a budget substitute for full fine-tuning.
MinT: Managed Infrastructure for Training and Serving Millions of LLMs
May 13, 2026We present MindLab Toolkit (MinT), a managed infrastructure system for Low-Rank Adaptation (LoRA) post-training and online serving. MinT targets a setting where many trained policies are produced over a small number of expensive base-model deployments. Instead of materializing each policy as a merged full checkpoint, MinT keeps the base model resident and moves exported LoRA adapter revisions through rollout, update, export, evaluation, serving, and rollback, hiding distributed training, serving, scheduling, and data movement behind a service interface. MinT scales this path along three axes. Scale Up extends LoRA RL to frontier-scale dense and MoE architectures, including MLA and DSA attention paths, with training and serving validated beyond 1T total parameters. Scale Down moves only the exported LoRA adapter, which can be under 1% of base-model size in rank-1 settings; adapter-only handoff reduces the measured step by 18.3x on a 4B dense model and 2.85x on a 30B MoE, while concurrent multi-policy GRPO shortens wall time by 1.77x and 1.45x without raising peak memory. Scale Out separates durable policy addressability from CPU/GPU working sets: a tensor-parallel deployment supports 10^6-scale addressable catalogs (measured single-engine sweeps through 100K) and thousand-adapter active waves at cluster scale, with cold loading treated as scheduled service work and packed MoE LoRA tensors improving live engine loading by 8.5-8.7x. MinT thus manages million-scale LoRA policy catalogs while training and serving selected adapter revisions over shared 1T-class base models.
Spurious Rewards Paradox: Mechanistically Understanding How RLVR Activates Memorization Shortcuts in LLMs
Jan 16, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is highly effective for enhancing LLM reasoning, yet recent evidence shows models like Qwen 2.5 achieve significant gains even with spurious or incorrect rewards. We investigate this phenomenon and identify a "Perplexity Paradox": spurious RLVR triggers a divergence where answer-token perplexity drops while prompt-side coherence degrades, suggesting the model is bypassing reasoning in favor of memorization. Using Path Patching, Logit Lens, JSD analysis, and Neural Differential Equations, we uncover a hidden Anchor-Adapter circuit that facilitates this shortcut. We localize a Functional Anchor in the middle layers (L18-20) that triggers the retrieval of memorized solutions, followed by Structural Adapters in later layers (L21+) that transform representations to accommodate the shortcut signal. Finally, we demonstrate that scaling specific MLP keys within this circuit allows for bidirectional causal steering-artificially amplifying or suppressing contamination-driven performance. Our results provide a mechanistic roadmap for identifying and mitigating data contamination in RLVR-tuned models. Code is available at https://github.com/idwts/How-RLVR-Activates-Memorization-Shortcuts.
Design and Evaluation of a Compliant Quasi Direct Drive End-effector for Safe Robotic Ultrasound Imaging
Oct 04, 2024Robot-assisted ultrasound scanning promises to advance autonomous and accessible medical imaging. However, ensuring patient safety and compliant human-robot interaction (HRI) during probe contact poses a significant challenge. Most existing systems either have high mechanical stiffness or are compliant but lack sufficient force and precision. This paper presents a novel single-degree-of-freedom end-effector for safe and accurate robotic ultrasound imaging, using a quasi-direct drive actuator to achieve both passive mechanical compliance and precise active force regulation, even during motion. The end-effector demonstrates an effective force control bandwidth of 100 Hz and can apply forces ranging from 2.5N to 15N. To validate the end-effector's performance, we developed a novel ex vivo actuating platform, enabling compliance testing of the end-effector on simulated abdominal breathing and sudden patient movements. Experiments demonstrate that the end-effector can maintain consistent probe contact during simulated respiratory motion at 2.5N, 5N, 10N, and 15N, with an average force tracking RMS error of 0.83N compared to 4.70N on a UR3e robot arm using conventional force control. This system represents the first compliant ultrasound end-effector tested on a tissue platform simulating dynamic movement. The proposed solution provides a novel approach for designing and evaluating compliant robotic ultrasound systems, advancing the path for more compliant and patient-friendly robotic ultrasound systems in clinical settings.
Forecasting SEP Events During Solar Cycles 23 and 24 Using Interpretable Machine Learning
Mar 04, 2024



Prediction of the Solar Energetic Particle (SEP) events garner increasing interest as space missions extend beyond Earth's protective magnetosphere. These events, which are, in most cases, products of magnetic reconnection-driven processes during solar flares or fast coronal-mass-ejection-driven shock waves, pose significant radiation hazards to aviation, space-based electronics, and particularly, space exploration. In this work, we utilize the recently developed dataset that combines the Solar Dynamics Observatory/Helioseismic and Magnetic Imager's (SDO/HMI) Space weather HMI Active Region Patches (SHARP) and the Solar and Heliospheric Observatory/Michelson Doppler Imager's (SoHO/MDI) Space Weather MDI Active Region Patches (SMARP). We employ a suite of machine learning strategies, including Support Vector Machines (SVM) and regression models, to evaluate the predictive potential of this new data product for a forecast of post-solar flare SEP events. Our study indicates that despite the augmented volume of data, the prediction accuracy reaches 0.7 +- 0.1, which aligns with but does not exceed these published benchmarks. A linear SVM model with training and testing configurations that mimic an operational setting (positive-negative imbalance) reveals a slight increase (+ 0.04 +- 0.05) in the accuracy of a 14-hour SEP forecast compared to previous studies. This outcome emphasizes the imperative for more sophisticated, physics-informed models to better understand the underlying processes leading to SEP events.
Zero-shot sampling of adversarial entities in biomedical question answering
Feb 16, 2024The increasing depth of parametric domain knowledge in large language models (LLMs) is fueling their rapid deployment in real-world applications. In high-stakes and knowledge-intensive tasks, understanding model vulnerabilities is essential for quantifying the trustworthiness of model predictions and regulating their use. The recent discovery of named entities as adversarial examples in natural language processing tasks raises questions about their potential guises in other settings. Here, we propose a powerscaled distance-weighted sampling scheme in embedding space to discover diverse adversarial entities as distractors. We demonstrate its advantage over random sampling in adversarial question answering on biomedical topics. Our approach enables the exploration of different regions on the attack surface, which reveals two regimes of adversarial entities that markedly differ in their characteristics. Moreover, we show that the attacks successfully manipulate token-wise Shapley value explanations, which become deceptive in the adversarial setting. Our investigations illustrate the brittleness of domain knowledge in LLMs and reveal a shortcoming of standard evaluations for high-capacity models.
Evading Adversarial Example Detection Defenses with Orthogonal Projected Gradient Descent
Jun 28, 2021
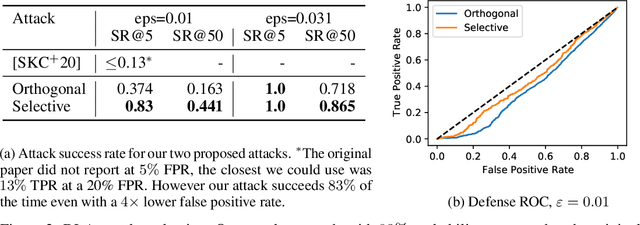
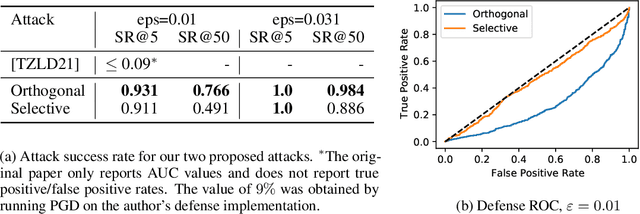
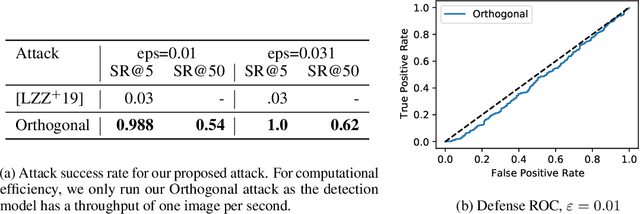
Evading adversarial example detection defenses requires finding adversarial examples that must simultaneously (a) be misclassified by the model and (b) be detected as non-adversarial. We find that existing attacks that attempt to satisfy multiple simultaneous constraints often over-optimize against one constraint at the cost of satisfying another. We introduce Orthogonal Projected Gradient Descent, an improved attack technique to generate adversarial examples that avoids this problem by orthogonalizing the gradients when running standard gradient-based attacks. We use our technique to evade four state-of-the-art detection defenses, reducing their accuracy to 0% while maintaining a 0% detection rate.
Grammar Equations
Jun 14, 2021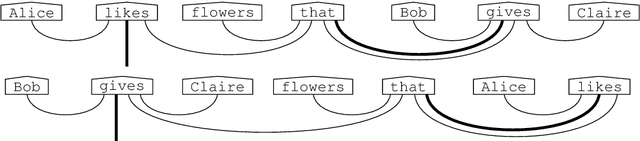
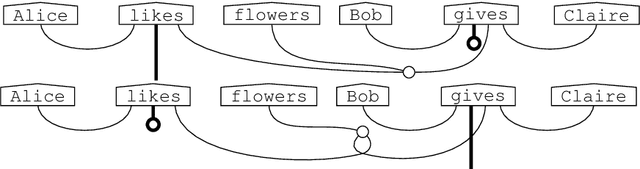
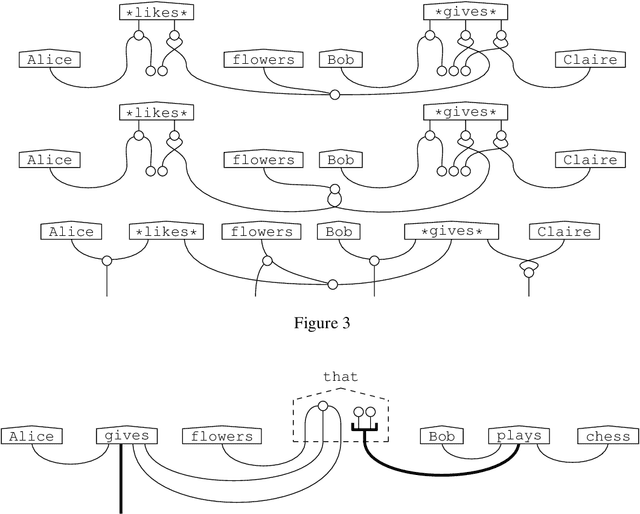
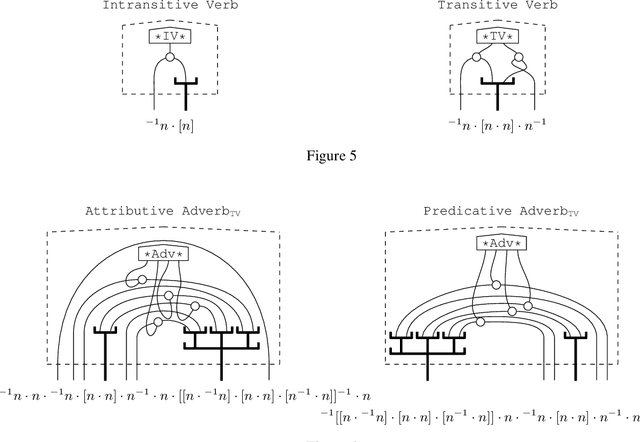
Diagrammatically speaking, grammatical calculi such as pregroups provide wires between words in order to elucidate their interactions, and this enables one to verify grammatical correctness of phrases and sentences. In this paper we also provide wirings within words. This will enable us to identify grammatical constructs that we expect to be either equal or closely related. Hence, our work paves the way for a new theory of grammar, that provides novel `grammatical truths'. We give a nogo-theorem for the fact that our wirings for words make no sense for preordered monoids, the form which grammatical calculi usually take. Instead, they require diagrams -- or equivalently, (free) monoidal categories.
The Safari of Update Structures: Visiting the Lens and Quantum Enclosures
May 12, 2020We build upon our recently introduced concept of an update structure to show that they are a generalisation of very-well-behaved lenses, that is, there is a bijection between a strict subset of update structures and vwb lenses in cartesian categories. We then begin to investigate the zoo of possible update structures. We show that update structures survive decoherence and are sufficiently general to capture quantum observables, pinpointing the additional assumptions required to make the two coincide. In doing so, we shift the focus from dagger-special commutative Frobenius algebras to interacting (co)magma (co)module pairs, showing that the algebraic properties of the (co)multiplication arise from the module-comodule interaction, rather than direct assumptions about the magma comagma pair. Thus this work is of foundational interest as update structures form a strictly more general class of algebraic objects, the taming of which promises to illuminate novel relationships between separately studied mathematical structures.
Categories of Semantic Concepts
Apr 22, 2020Modelling concept representation is a foundational problem in the study of cognition and linguistics. This work builds on the confluence of conceptual tools from Gardenfors semantic spaces, categorical compositional linguistics, and applied category theory to present a domain-independent and categorial formalism of 'concept'.