 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSki Rental with Distributional Predictions of Unknown Quality
Feb 24, 2026We revisit the central online problem of ski rental in the "algorithms with predictions" framework from the point of view of distributional predictions. Ski rental was one of the first problems to be studied with predictions, where a natural prediction is simply the number of ski days. But it is both more natural and potentially more powerful to think of a prediction as a distribution p-hat over the ski days. If the true number of ski days is drawn from some true (but unknown) distribution p, then we show as our main result that there is an algorithm with expected cost at most OPT + O(min(max({eta}, 1) * sqrt(b), b log b)), where OPT is the expected cost of the optimal policy for the true distribution p, b is the cost of buying, and {eta} is the Earth Mover's (Wasserstein-1) distance between p and p-hat. Note that when {eta} < o(sqrt(b)) this gives additive loss less than b (the trivial bound), and when {eta} is arbitrarily large (corresponding to an extremely inaccurate prediction) we still do not pay more than O(b log b) additive loss. An implication of these bounds is that our algorithm has consistency O(sqrt(b)) (additive loss when the prediction error is 0) and robustness O(b log b) (additive loss when the prediction error is arbitrarily large). Moreover, we do not need to assume that we know (or have any bound on) the prediction error {eta}, in contrast with previous work in robust optimization which assumes that we know this error. We complement this upper bound with a variety of lower bounds showing that it is essentially tight: not only can the consistency/robustness tradeoff not be improved, but our particular loss function cannot be meaningfully improved.
Pre-trained Transformer-models using chronic invasive electrophysiology for symptom decoding without patient-individual training
Aug 13, 2025Neural decoding of pathological and physiological states can enable patient-individualized closed-loop neuromodulation therapy. Recent advances in pre-trained large-scale foundation models offer the potential for generalized state estimation without patient-individual training. Here we present a foundation model trained on chronic longitudinal deep brain stimulation recordings spanning over 24 days. Adhering to long time-scale symptom fluctuations, we highlight the extended context window of 30 minutes. We present an optimized pre-training loss function for neural electrophysiological data that corrects for the frequency bias of common masked auto-encoder loss functions due to the 1-over-f power law. We show in a downstream task the decoding of Parkinson's disease symptoms with leave-one-subject-out cross-validation without patient-individual training.
Measuring temporal effects of agent knowledge by date-controlled tool use
Mar 06, 2025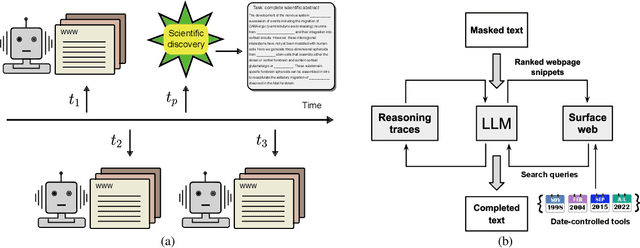
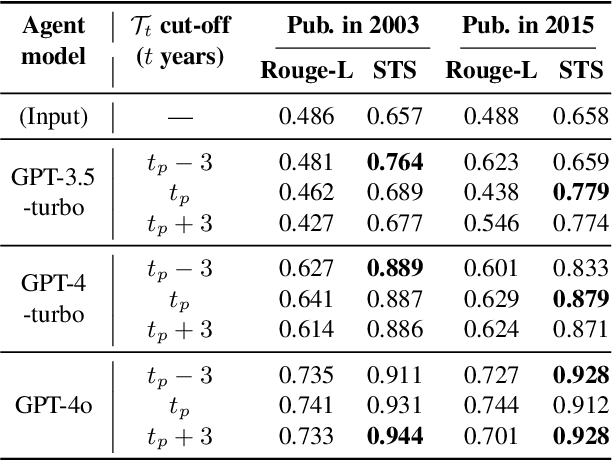
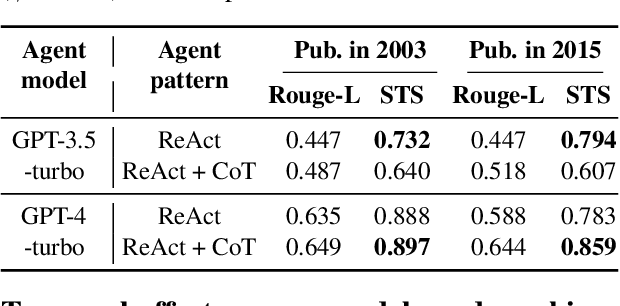

Temporal progression is an integral part of knowledge accumulation and update. Web search is frequently adopted as grounding for agent knowledge, yet its inappropriate configuration affects the quality of agent responses. Here, we construct a tool-based out-of-sample testing framework to measure the knowledge variability of large language model (LLM) agents from distinct date-controlled tools (DCTs). We demonstrate the temporal effects of an LLM agent as a writing assistant, which can use web search to help complete scientific publication abstracts. We show that temporal effects of the search engine translates into tool-dependent agent performance but can be alleviated with base model choice and explicit reasoning instructions such as chain-of-thought prompting. Our results indicate that agent evaluation should take a dynamical view and account for the temporal influence of tools and the updates of external resources.
7T MRI Synthesization from 3T Acquisitions
Mar 13, 2024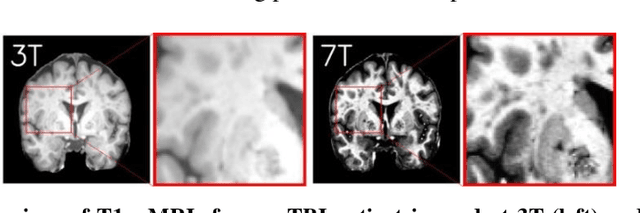

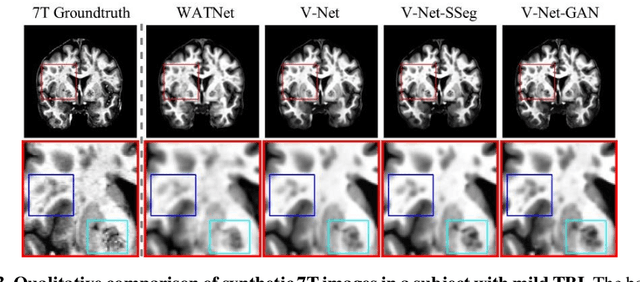
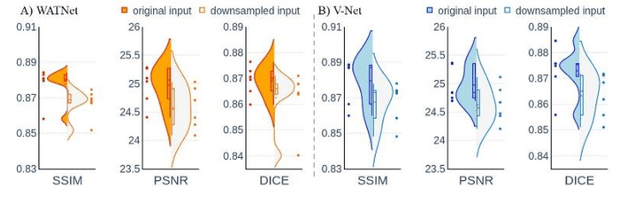
Supervised deep learning techniques can be used to generate synthetic 7T MRIs from 3T MRI inputs. This image enhancement process leverages the advantages of ultra-high-field MRI to improve the signal-to-noise and contrast-to-noise ratios of 3T acquisitions. In this paper, we introduce multiple novel 7T synthesization algorithms based on custom-designed variants of the V-Net convolutional neural network. We demonstrate that the V-Net based model has superior performance in enhancing both single-site and multi-site MRI datasets compared to the existing benchmark model. When trained on 3T-7T MRI pairs from 8 subjects with mild Traumatic Brain Injury (TBI), our model achieves state-of-the-art 7T synthesization performance. Compared to previous works, synthetic 7T images generated from our pipeline also display superior enhancement of pathological tissue. Additionally, we implement and test a data augmentation scheme for training models that are robust to variations in the input distribution. This allows synthetic 7T models to accommodate intra-scanner and inter-scanner variability in multisite datasets. On a harmonized dataset consisting of 18 3T-7T MRI pairs from two institutions, including both healthy subjects and those with mild TBI, our model maintains its performance and can generalize to 3T MRI inputs with lower resolution. Our findings demonstrate the promise of V-Net based models for MRI enhancement and offer a preliminary probe into improving the generalizability of synthetic 7T models with data augmentation.
Zero-shot sampling of adversarial entities in biomedical question answering
Feb 16, 2024The increasing depth of parametric domain knowledge in large language models (LLMs) is fueling their rapid deployment in real-world applications. In high-stakes and knowledge-intensive tasks, understanding model vulnerabilities is essential for quantifying the trustworthiness of model predictions and regulating their use. The recent discovery of named entities as adversarial examples in natural language processing tasks raises questions about their potential guises in other settings. Here, we propose a powerscaled distance-weighted sampling scheme in embedding space to discover diverse adversarial entities as distractors. We demonstrate its advantage over random sampling in adversarial question answering on biomedical topics. Our approach enables the exploration of different regions on the attack surface, which reveals two regimes of adversarial entities that markedly differ in their characteristics. Moreover, we show that the attacks successfully manipulate token-wise Shapley value explanations, which become deceptive in the adversarial setting. Our investigations illustrate the brittleness of domain knowledge in LLMs and reveal a shortcoming of standard evaluations for high-capacity models.