 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighboring state-based RL Exploration
Dec 21, 2022



Reinforcement Learning is a powerful tool to model decision-making processes. However, it relies on an exploration-exploitation trade-off that remains an open challenge for many tasks. In this work, we study neighboring state-based, model-free exploration led by the intuition that, for an early-stage agent, considering actions derived from a bounded region of nearby states may lead to better actions when exploring. We propose two algorithms that choose exploratory actions based on a survey of nearby states, and find that one of our methods, ${\rho}$-explore, consistently outperforms the Double DQN baseline in an discrete environment by 49\% in terms of Eval Reward Return.
Evading Adversarial Example Detection Defenses with Orthogonal Projected Gradient Descent
Jun 28, 2021
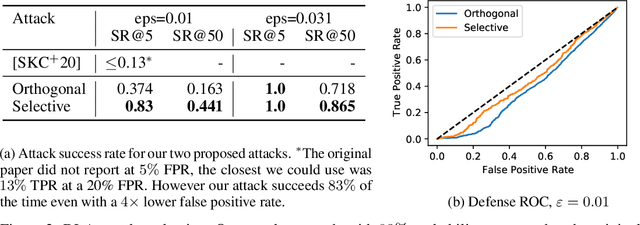
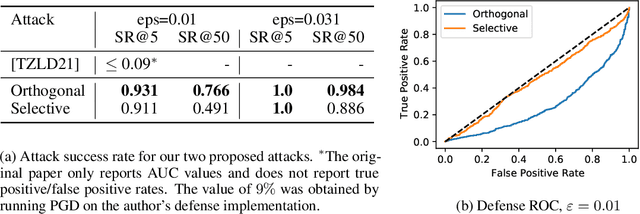
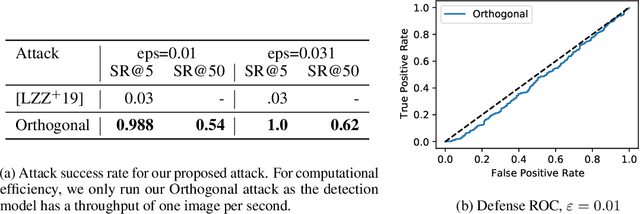
Evading adversarial example detection defenses requires finding adversarial examples that must simultaneously (a) be misclassified by the model and (b) be detected as non-adversarial. We find that existing attacks that attempt to satisfy multiple simultaneous constraints often over-optimize against one constraint at the cost of satisfying another. We introduce Orthogonal Projected Gradient Descent, an improved attack technique to generate adversarial examples that avoids this problem by orthogonalizing the gradients when running standard gradient-based attacks. We use our technique to evade four state-of-the-art detection defenses, reducing their accuracy to 0% while maintaining a 0% detection rate.