 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interactive Tool for Analyzing High-Dimensional Clusterings
Sep 04, 2025Technological advances have spurred an increase in data complexity and dimensionality. We are now in an era in which data sets containing thousands of features are commonplace. To digest and analyze such high-dimensional data, dimension reduction techniques have been developed and advanced along with computational power. Of these techniques, nonlinear methods are most commonly employed because of their ability to construct visually interpretable embeddings. Unlike linear methods, these methods non-uniformly stretch and shrink space to create a visual impression of the high-dimensional data. Since capturing high-dimensional structures in a significantly lower number of dimensions requires drastic manipulation of space, nonlinear dimension reduction methods are known to occasionally produce false structures, especially in noisy settings. In an effort to deal with this phenomenon, we developed an interactive tool that enables analysts to better understand and diagnose their dimension reduction results. It uses various analytical plots to provide a multi-faceted perspective on results to determine legitimacy. The tool is available via an R package named DRtool.
VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks
Oct 24, 2024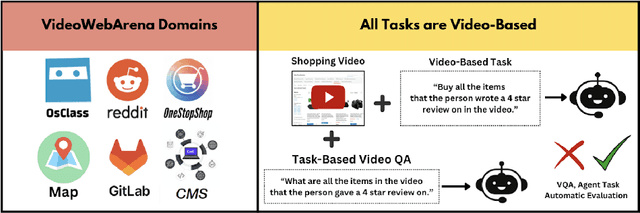
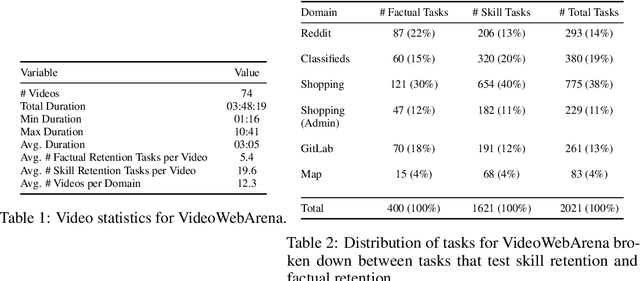
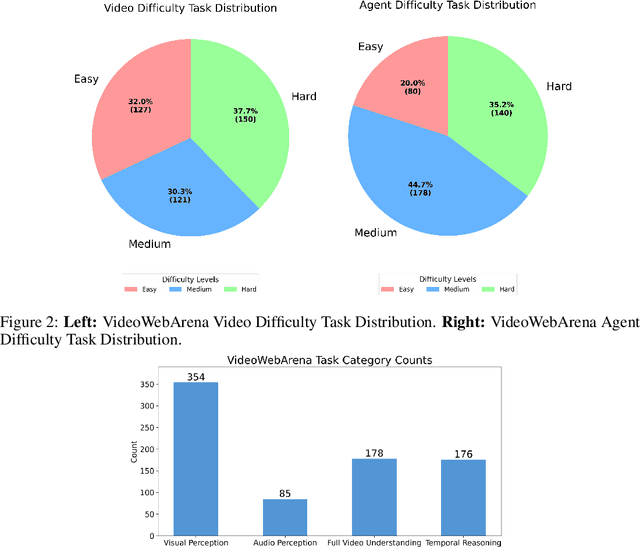
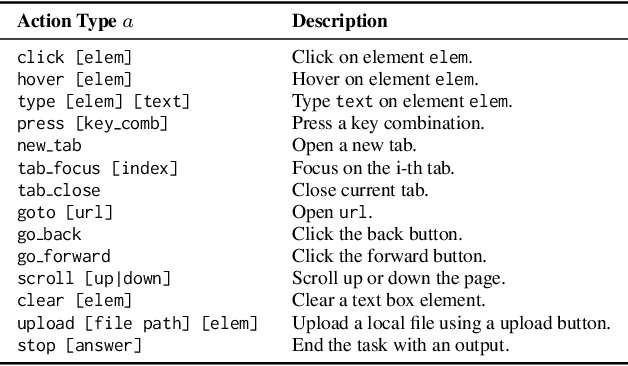
Videos are often used to learn or extract the necessary information to complete tasks in ways different than what text and static imagery alone can provide. However, many existing agent benchmarks neglect long-context video understanding, instead focusing on text or static image inputs. To bridge this gap, we introduce VideoWebArena (VideoWA), a benchmark for evaluating the capabilities of long-context multimodal agents for video understanding. VideoWA consists of 2,021 web agent tasks based on manually crafted video tutorials, which total almost four hours of content. For our benchmark, we define a taxonomy of long-context video-based agent tasks with two main areas of focus: skill retention and factual retention. While skill retention tasks evaluate whether an agent can use a given human demonstration to complete a task efficiently, the factual retention task evaluates whether an agent can retrieve instruction-relevant information from a video to complete a task. We find that the best model achieves 13.3% success on factual retention tasks and 45.8% on factual retention QA pairs, far below human performance at 73.9% and 79.3%, respectively. On skill retention tasks, long-context models perform worse with tutorials than without, exhibiting a 5% performance decrease in WebArena tasks and a 10.3% decrease in VisualWebArena tasks. Our work highlights the need to improve the agentic abilities of long-context multimodal models and provides a testbed for future development with long-context video agents.
Consistency Models Made Easy
Jun 20, 2024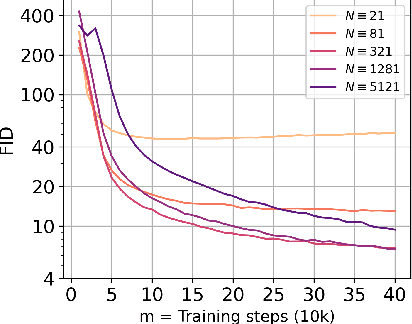
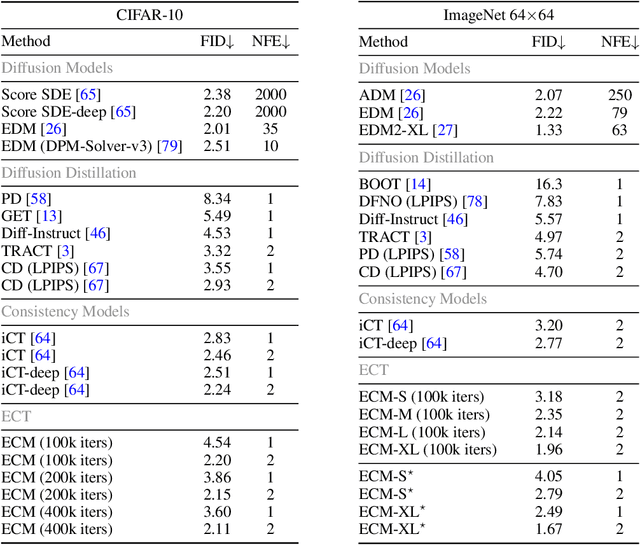
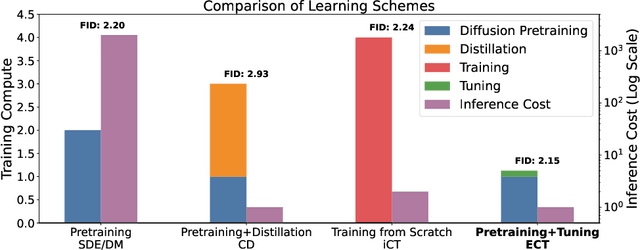

Consistency models (CMs) are an emerging class of generative models that offer faster sampling than traditional diffusion models. CMs enforce that all points along a sampling trajectory are mapped to the same initial point. But this target leads to resource-intensive training: for example, as of 2024, training a SoTA CM on CIFAR-10 takes one week on 8 GPUs. In this work, we propose an alternative scheme for training CMs, vastly improving the efficiency of building such models. Specifically, by expressing CM trajectories via a particular differential equation, we argue that diffusion models can be viewed as a special case of CMs with a specific discretization. We can thus fine-tune a consistency model starting from a pre-trained diffusion model and progressively approximate the full consistency condition to stronger degrees over the training process. Our resulting method, which we term Easy Consistency Tuning (ECT), achieves vastly improved training times while indeed improving upon the quality of previous methods: for example, ECT achieves a 2-step FID of 2.73 on CIFAR10 within 1 hour on a single A100 GPU, matching Consistency Distillation trained of hundreds of GPU hours. Owing to this computational efficiency, we investigate the scaling law of CMs under ECT, showing that they seem to obey classic power law scaling, hinting at their ability to improve efficiency and performance at larger scales. Code (https://github.com/locuslab/ect) is available.
Calibrating dimension reduction hyperparameters in the presence of noise
Dec 09, 2023



The goal of dimension reduction tools is to construct a low-dimensional representation of high-dimensional data. These tools are employed for a variety of reasons such as noise reduction, visualization, and to lower computational costs. However, there is a fundamental issue that is highly discussed in other modeling problems, but almost entirely ignored in the dimension reduction literature: overfitting. If we interpret data as a combination of signal and noise, prior works judge dimension reduction techniques on their ability to capture the entirety of the data, i.e. both the signal and the noise. In the context of other modeling problems, techniques such as feature-selection, cross-validation, and regularization are employed to combat overfitting, but no such precautions are taken when performing dimension reduction. In this paper, we present a framework that models dimension reduction problems in the presence of noise and use this framework to explore the role perplexity and number of neighbors play in overfitting data when applying t-SNE and UMAP. More specifically, we show previously recommended values for perplexity and number of neighbors are too small and tend to overfit the noise. We also present a workflow others may use to calibrate perplexity or number of neighbors in the presence of noise.
DRAGON: A Dialogue-Based Robot for Assistive Navigation with Visual Language Grounding
Jul 13, 2023Persons with visual impairments (PwVI) have difficulties understanding and navigating spaces around them. Current wayfinding technologies either focus solely on navigation or provide limited communication about the environment. Motivated by recent advances in visual-language grounding and semantic navigation, we propose DRAGON, a guiding robot powered by a dialogue system and the ability to associate the environment with natural language. By understanding the commands from the user, DRAGON is able to guide the user to the desired landmarks on the map, describe the environment, and answer questions from visual observations. Through effective utilization of dialogue, the robot can ground the user's free-form descriptions to landmarks in the environment, and give the user semantic information through spoken language. We conduct a user study with blindfolded participants in an everyday indoor environment. Our results demonstrate that DRAGON is able to communicate with the user smoothly, provide a good guiding experience, and connect users with their surrounding environment in an intuitive manner.
Designing a Wayfinding Robot for People with Visual Impairments
Feb 17, 2023People with visual impairments (PwVI) often have difficulties navigating through unfamiliar indoor environments. However, current wayfinding tools are fairly limited. In this short paper, we present our in-progress work on a wayfinding robot for PwVI. The robot takes an audio command from the user that specifies the intended destination. Then, the robot autonomously plans a path to navigate to the goal. We use sensors to estimate the real-time position of the user, which is fed to the planner to improve the safety and comfort of the user. In addition, the robot describes the surroundings to the user periodically to prevent disorientation and potential accidents. We demonstrate the feasibility of our design in a public indoor environment. Finally, we analyze the limitations of our current design, as well as our insights and future work. A demonstration video can be found at https://youtu.be/BS9r5bkIass.
Neighboring state-based RL Exploration
Dec 21, 2022



Reinforcement Learning is a powerful tool to model decision-making processes. However, it relies on an exploration-exploitation trade-off that remains an open challenge for many tasks. In this work, we study neighboring state-based, model-free exploration led by the intuition that, for an early-stage agent, considering actions derived from a bounded region of nearby states may lead to better actions when exploring. We propose two algorithms that choose exploratory actions based on a survey of nearby states, and find that one of our methods, ${\rho}$-explore, consistently outperforms the Double DQN baseline in an discrete environment by 49\% in terms of Eval Reward Return.
Learning to Identify Object Instances by Touch: Tactile Recognition via Multimodal Matching
Mar 08, 2019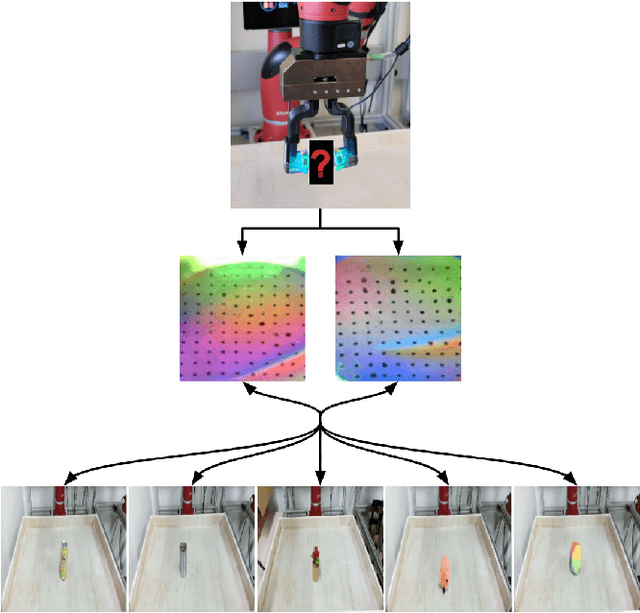


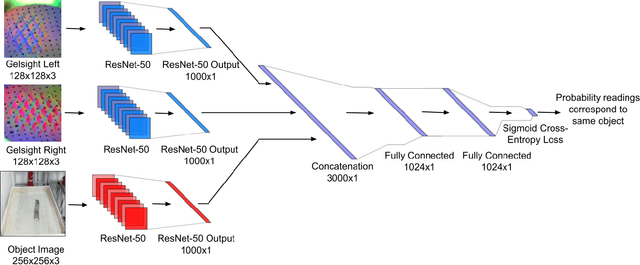
Much of the literature on robotic perception focuses on the visual modality. Vision provides a global observation of a scene, making it broadly useful. However, in the domain of robotic manipulation, vision alone can sometimes prove inadequate: in the presence of occlusions or poor lighting, visual object identification might be difficult. The sense of touch can provide robots with an alternative mechanism for recognizing objects. In this paper, we study the problem of touch-based instance recognition. We propose a novel framing of the problem as multi-modal recognition: the goal of our system is to recognize, given a visual and tactile observation, whether or not these observations correspond to the same object. To our knowledge, our work is the first to address this type of multi-modal instance recognition problem on such a large-scale with our analysis spanning 98 different objects. We employ a robot equipped with two GelSight touch sensors, one on each finger, and a self-supervised, autonomous data collection procedure to collect a dataset of tactile observations and images. Our experimental results show that it is possible to accurately recognize object instances by touch alone, including instances of novel objects that were never seen during training. Our learned model outperforms other methods on this complex task, including that of human volunteers.
More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch
Jul 26, 2018

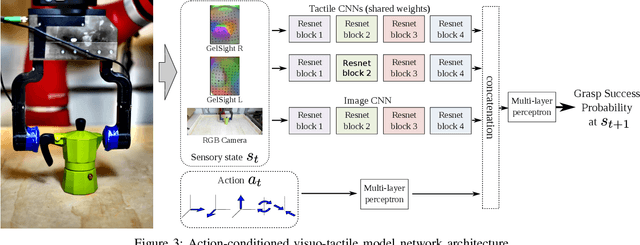

For humans, the process of grasping an object relies heavily on rich tactile feedback. Most recent robotic grasping work, however, has been based only on visual input, and thus cannot easily benefit from feedback after initiating contact. In this paper, we investigate how a robot can learn to use tactile information to iteratively and efficiently adjust its grasp. To this end, we propose an end-to-end action-conditional model that learns regrasping policies from raw visuo-tactile data. This model -- a deep, multimodal convolutional network -- predicts the outcome of a candidate grasp adjustment, and then executes a grasp by iteratively selecting the most promising actions. Our approach requires neither calibration of the tactile sensors, nor any analytical modeling of contact forces, thus reducing the engineering effort required to obtain efficient grasping policies. We train our model with data from about 6,450 grasping trials on a two-finger gripper equipped with GelSight high-resolution tactile sensors on each finger. Across extensive experiments, our approach outperforms a variety of baselines at (i) estimating grasp adjustment outcomes, (ii) selecting efficient grasp adjustments for quick grasping, and (iii) reducing the amount of force applied at the fingers, while maintaining competitive performance. Finally, we study the choices made by our model and show that it has successfully acquired useful and interpretable grasping behaviors.
The Feeling of Success: Does Touch Sensing Help Predict Grasp Outcomes?
Oct 16, 2017
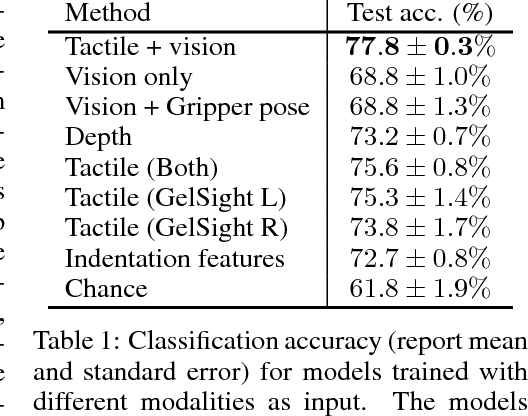
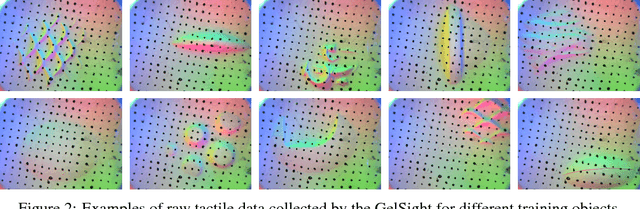

A successful grasp requires careful balancing of the contact forces. Deducing whether a particular grasp will be successful from indirect measurements, such as vision, is therefore quite challenging, and direct sensing of contacts through touch sensing provides an appealing avenue toward more successful and consistent robotic grasping. However, in order to fully evaluate the value of touch sensing for grasp outcome prediction, we must understand how touch sensing can influence outcome prediction accuracy when combined with other modalities. Doing so using conventional model-based techniques is exceptionally difficult. In this work, we investigate the question of whether touch sensing aids in predicting grasp outcomes within a multimodal sensing framework that combines vision and touch. To that end, we collected more than 9,000 grasping trials using a two-finger gripper equipped with GelSight high-resolution tactile sensors on each finger, and evaluated visuo-tactile deep neural network models to directly predict grasp outcomes from either modality individually, and from both modalities together. Our experimental results indicate that incorporating tactile readings substantially improve grasping performance.