 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAGON: A Dialogue-Based Robot for Assistive Navigation with Visual Language Grounding
Jul 13, 2023Persons with visual impairments (PwVI) have difficulties understanding and navigating spaces around them. Current wayfinding technologies either focus solely on navigation or provide limited communication about the environment. Motivated by recent advances in visual-language grounding and semantic navigation, we propose DRAGON, a guiding robot powered by a dialogue system and the ability to associate the environment with natural language. By understanding the commands from the user, DRAGON is able to guide the user to the desired landmarks on the map, describe the environment, and answer questions from visual observations. Through effective utilization of dialogue, the robot can ground the user's free-form descriptions to landmarks in the environment, and give the user semantic information through spoken language. We conduct a user study with blindfolded participants in an everyday indoor environment. Our results demonstrate that DRAGON is able to communicate with the user smoothly, provide a good guiding experience, and connect users with their surrounding environment in an intuitive manner.
Learning Rewards and Skills to Follow Commands with A Data Efficient Visual-Audio Representation
Jan 23, 2023Based on the recent advancements in representation learning, we propose a novel framework for command-following robots with raw sensor inputs. Previous RL-based methods are either difficult to continuously improve after the deployment or require a large number of new labels during the fine-tuning. Motivated by (self-)supervised contrastive learning literature, we propose a novel representation, named VAR++, that generates an intrinsic reward function for command-following robot tasks by associating images with sound commands. After the robot is deployed in a new domain, the representation can be updated intuitively and data-efficiently by non-experts, and the robot is able to fulfill sound commands without any hand-crafted reward functions. We demonstrate our approach on various sound types and robotic tasks, including navigation and manipulation with raw sensor inputs. In the simulated experiments, we show that our system can continually self-improve in previously unseen scenarios given fewer new labeled data, yet achieves better performance, compared with previous methods.
Socially Aware Robot Crowd Navigation with Interaction Graphs and Human Trajectory Prediction
Mar 03, 2022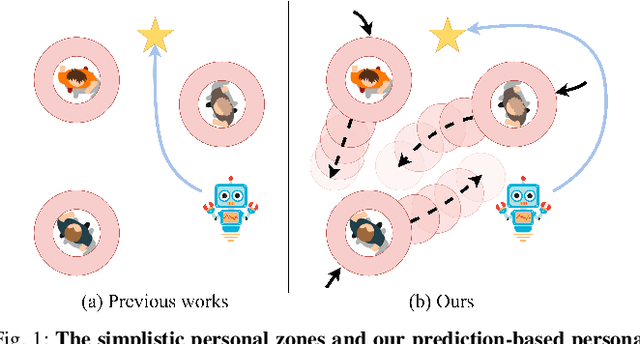
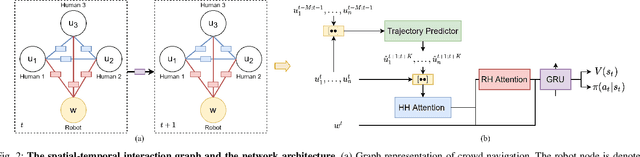
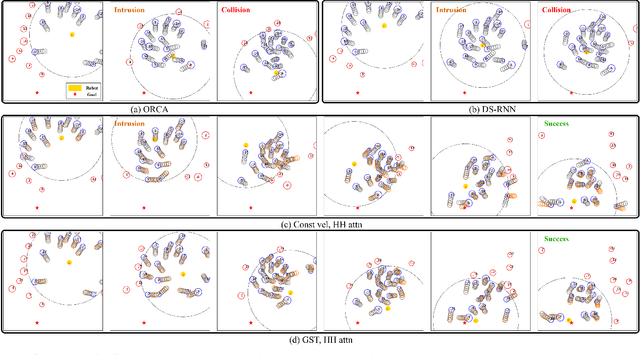

We study the problem of safe and socially aware robot navigation in dense and interactive human crowds. Previous works use simplified methods to model the personal spaces of pedestrians and ignore the social compliance of the robot behaviors. In this paper, we provide a more accurate representation of personal zones of walking pedestrians with their future trajectories. The predicted personal zones are incorporated into a reinforcement learning framework to prevent the robot from intruding into the personal zones. To learn socially aware navigation policies, we propose a novel recurrent graph neural network with attention mechanisms to capture the interactions among agents through space and time. We demonstrate that our method enables the robot to achieve good navigation performance and non-invasiveness in challenging crowd navigation scenarios. We successfully transfer the policy learned in the simulator to a real-world TurtleBot 2i.
Learning to Navigate Intersections with Unsupervised Driver Trait Inference
Sep 14, 2021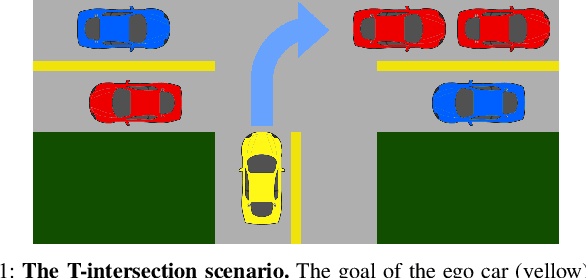



Navigation through uncontrolled intersections is one of the key challenges for autonomous vehicles. Identifying the subtle differences in hidden traits of other drivers can bring significant benefits when navigating in such environments. We propose an unsupervised method for inferring driver traits such as driving styles from observed vehicle trajectories. We use a variational autoencoder with recurrent neural networks to learn a latent representation of traits without any ground truth trait labels. Then, we use this trait representation to learn a policy for an autonomous vehicle to navigate through a T-intersection with deep reinforcement learning. Our pipeline enables the autonomous vehicle to adjust its actions when dealing with drivers of different traits to ensure safety and efficiency. Our method demonstrates promising performance and outperforms state-of-the-art baselines in the T-intersection scenario.
Robot Sound Interpretation: Learning Visual-Audio Representations for Voice-Controlled Robots
Sep 07, 2021



Inspired by sensorimotor theory, we propose a novel pipeline for voice-controlled robots. Previous work relies on explicit labels of sounds and images as well as extrinsic reward functions. Not only do such approaches have little resemblance to human sensorimotor development, but also require hand-tuning rewards and extensive human labor. To address these problems, we learn a representation that associates images and sound commands with minimal supervision. Using this representation, we generate an intrinsic reward function to learn robotic tasks with reinforcement learning. We demonstrate our approach on three robot platforms, a TurtleBot3, a Kuka-IIWA arm, and a Kinova Gen3 robot, which hear a command word, identify the associated target object, and perform precise control to approach the target. We show that our method outperforms previous work across various sound types and robotic tasks empirically. We successfully deploy the policy learned in simulator to a real-world Kinova Gen3.
Decentralized Structural-RNN for Robot Crowd Navigation with Deep Reinforcement Learning
Nov 09, 2020
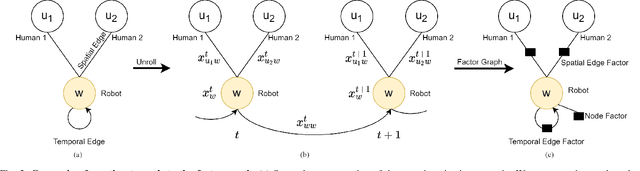
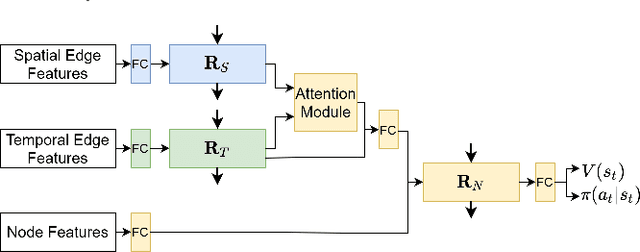

Safe and efficient navigation through human crowds is an essential capability for mobile robots. Previous work on robot crowd navigation assumes that the dynamics of all agents are known and well-defined. In addition, the performance of previous methods deteriorates in partially observable environments and environments with dense crowds. To tackle these problems, we propose decentralized structural-Recurrent Neural Network (DS-RNN), a novel network that reasons about spatial and temporal relationships for robot decision making in crowd navigation. We train our network with model-free deep reinforcement learning without any expert supervision. We demonstrate that our model outperforms previous methods and successfully transfer the policy learned in the simulator to a real-world TurtleBot 2i.
Robot Sound Interpretation: Combining Sight and Sound in Learning-Based Control
Sep 19, 2019
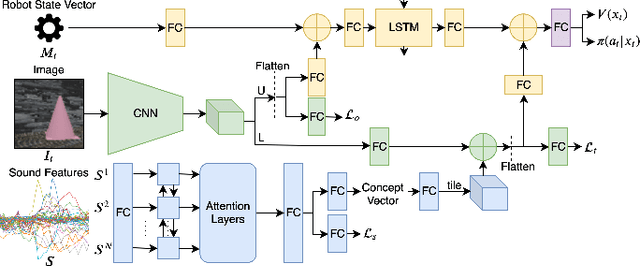


We explore the interpretation of sound for robot decision-making, inspired by human speech comprehension. While previous methods use natural language processing to translate sound to text, we propose an end-to-end deep neural network which directly learns control polices from images and sound signals. The network is trained using reinforcement learning with auxiliary losses on the sight and sound network branches. We demonstrate our approach on two robots, a TurtleBot3 and a Kuka-IIWA arm, which hear a command word, identify the associated target object, and perform precise control to reach the target. For both systems, we perform ablation studies in simulation to show the effectiveness of our network empirically. We also successfully transfer the policy learned in simulator to a real-world TurtleBot3, which effectively understands word commands, searches for the object, and moves toward that location with more intuitive motion than a traditional motion planner with perfect information.