 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilevel Layer-Positioning LoRA for Real Image Dehazing
Mar 11, 2026Learning-based real image dehazing methods have achieved notable progress, yet they still face adaptation challenges in diverse real haze scenes. These challenges mainly stem from the lack of effective unsupervised mechanisms for unlabeled data and the heavy cost of full model fine-tuning. To address these challenges, we propose the haze-to-clear text-directed loss that leverages CLIP's cross-modal capabilities to reformulate real image dehazing as a semantic alignment problem in latent space, thereby providing explicit unsupervised cross-modal guidance in the absence of reference images. Furthermore, we introduce the Bilevel Layer-positioning LoRA (BiLaLoRA) strategy, which learns both the LoRA parameters and automatically search the injection layers, enabling targeted adaptation of critical network layers. Extensive experiments demonstrate our superiority against state-of-the-art methods on multiple real-world dehazing benchmarks. The code is publicly available at https://github.com/YanZhang-zy/BiLaLoRA.
MIRAGE: Knowledge Graph-Guided Cross-Cohort MRI Synthesis for Alzheimer's Disease Prediction
Mar 02, 2026Reliable Alzheimer's disease (AD) diagnosis increasingly relies on multimodal assessments combining structural Magnetic Resonance Imaging (MRI) and Electronic Health Records (EHR). However, deploying these models is bottlenecked by modality missingness, as MRI scans are expensive and frequently unavailable in many patient cohorts. Furthermore, synthesizing de novo 3D anatomical scans from sparse, high-dimensional tabular records is technically challenging and poses severe clinical risks. To address this, we introduce MIRAGE, a novel framework that reframes the missing-MRI problem as an anatomy-guided cross-modal latent distillation task. First, MIRAGE leverages a Biomedical Knowledge Graph (KG) and Graph Attention Networks to map heterogeneous EHR variables into a unified embedding space that can be propagated from cohorts with real MRIs to cohorts without them. To bridge the semantic gap and enforce physical spatial awareness, we employ a frozen pre-trained 3D U-Net decoder strictly as an auxiliary regularization engine. Supported by a novel cohort-aggregated skip feature compensation strategy, this decoder acts as a rigorous structural penalty, forcing 1D latent representations to encode biologically plausible, macro-level pathological semantics. By exclusively utilizing this distilled "diagnostic-surrogate" representation during inference, MIRAGE completely bypasses computationally expensive 3D voxel reconstruction. Experiments demonstrate that our framework successfully bridges the missing-modality gap, improving the AD classification rate by 13% compared to unimodal baselines in cohorts without real MRIs.
Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
Jan 11, 2026In real-world video question answering scenarios, videos often provide only localized visual cues, while verifiable answers are distributed across the open web; models therefore need to jointly perform cross-frame clue extraction, iterative retrieval, and multi-hop reasoning-based verification. To bridge this gap, we construct the first video deep research benchmark, VideoDR. VideoDR centers on video-conditioned open-domain video question answering, requiring cross-frame visual anchor extraction, interactive web retrieval, and multi-hop reasoning over joint video-web evidence; through rigorous human annotation and quality control, we obtain high-quality video deep research samples spanning six semantic domains. We evaluate multiple closed-source and open-source multimodal large language models under both the Workflow and Agentic paradigms, and the results show that Agentic is not consistently superior to Workflow: its gains depend on a model's ability to maintain the initial video anchors over long retrieval chains. Further analysis indicates that goal drift and long-horizon consistency are the core bottlenecks. In sum, VideoDR provides a systematic benchmark for studying video agents in open-web settings and reveals the key challenges for next-generation video deep research agents.
Taming Hallucinations: Boosting MLLMs' Video Understanding via Counterfactual Video Generation
Dec 30, 2025Multimodal Large Language Models (MLLMs) have made remarkable progress in video understanding. However, they suffer from a critical vulnerability: an over-reliance on language priors, which can lead to visual ungrounded hallucinations, especially when processing counterfactual videos that defy common sense. This limitation, stemming from the intrinsic data imbalance between text and video, is challenging to address due to the substantial cost of collecting and annotating counterfactual data. To address this, we introduce DualityForge, a novel counterfactual data synthesis framework that employs controllable, diffusion-based video editing to transform real-world videos into counterfactual scenarios. By embedding structured contextual information into the video editing and QA generation processes, the framework automatically produces high-quality QA pairs together with original-edited video pairs for contrastive training. Based on this, we build DualityVidQA, a large-scale video dataset designed to reduce MLLM hallucinations. In addition, to fully exploit the contrastive nature of our paired data, we propose Duality-Normalized Advantage Training (DNA-Train), a two-stage SFT-RL training regime where the RL phase applies pair-wise $\ell_1$ advantage normalization, thereby enabling a more stable and efficient policy optimization. Experiments on DualityVidQA-Test demonstrate that our method substantially reduces model hallucinations on counterfactual videos, yielding a relative improvement of 24.0% over the Qwen2.5-VL-7B baseline. Moreover, our approach achieves significant gains across both hallucination and general-purpose benchmarks, indicating strong generalization capability. We will open-source our dataset and code.
GRAFT: Grid-Aware Load Forecasting with Multi-Source Textual Alignment and Fusion
Dec 16, 2025



Electric load is simultaneously affected across multiple time scales by exogenous factors such as weather and calendar rhythms, sudden events, and policies. Therefore, this paper proposes GRAFT (GRid-Aware Forecasting with Text), which modifies and improves STanHOP to better support grid-aware forecasting and multi-source textual interventions. Specifically, GRAFT strictly aligns daily-aggregated news, social media, and policy texts with half-hour load, and realizes text-guided fusion to specific time positions via cross-attention during both training and rolling forecasting. In addition, GRAFT provides a plug-and-play external-memory interface to accommodate different information sources in real-world deployment. We construct and release a unified aligned benchmark covering 2019--2021 for five Australian states (half-hour load, daily-aligned weather/calendar variables, and three categories of external texts), and conduct systematic, reproducible evaluations at three scales -- hourly, daily, and monthly -- under a unified protocol for comparison across regions, external sources, and time scales. Experimental results show that GRAFT significantly outperforms strong baselines and reaches or surpasses the state of the art across multiple regions and forecasting horizons. Moreover, the model is robust in event-driven scenarios and enables temporal localization and source-level interpretation of text-to-load effects through attention read-out. We release the benchmark, preprocessing scripts, and forecasting results to facilitate standardized empirical evaluation and reproducibility in power grid load forecasting.
Learning Safety for Obstacle Avoidance via Control Barrier Functions
Sep 19, 2025



Obstacle avoidance is central to safe navigation, especially for robots with arbitrary and nonconvex geometries operating in cluttered environments. Existing Control Barrier Function (CBF) approaches often rely on analytic clearance computations, which are infeasible for complex geometries, or on polytopic approximations, which become intractable when robot configurations are unknown. To address these limitations, this paper trains a residual neural network on a large dataset of robot-obstacle configurations to enable fast and tractable clearance prediction, even at unseen configurations. The predicted clearance defines the radius of a Local Safety Ball (LSB), which ensures continuous-time collision-free navigation. The LSB boundary is encoded as a Discrete-Time High-Order CBF (DHOCBF), whose constraints are incorporated into a nonlinear optimization framework. To improve feasibility, a novel relaxation technique is applied. The resulting framework ensure that the robot's rigid-body motion between consecutive time steps remains collision-free, effectively bridging discrete-time control and continuous-time safety. We show that the proposed method handles arbitrary, including nonconvex, robot geometries and generates collision-free, dynamically feasible trajectories in cluttered environments. Experiments demonstrate millisecond-level solve times and high prediction accuracy, highlighting both safety and efficiency beyond existing CBF-based methods.
Hierarchical Intention Tracking with Switching Trees for Real-Time Adaptation to Dynamic Human Intentions during Collaboration
Jun 08, 2025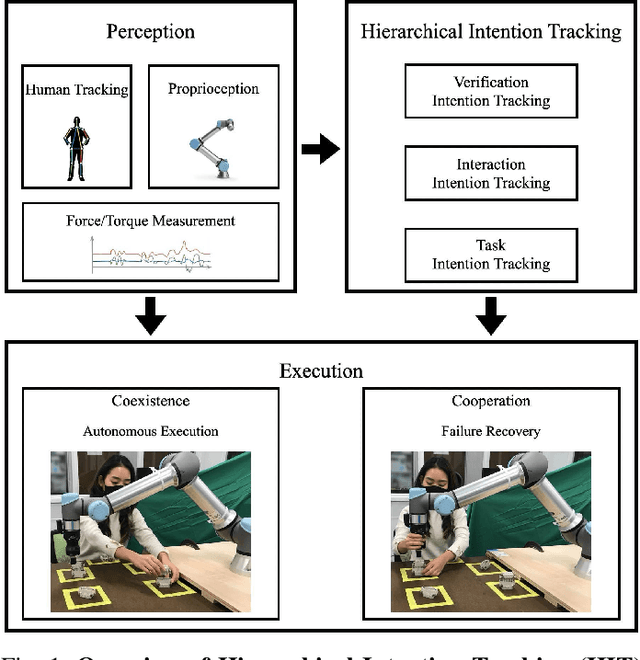
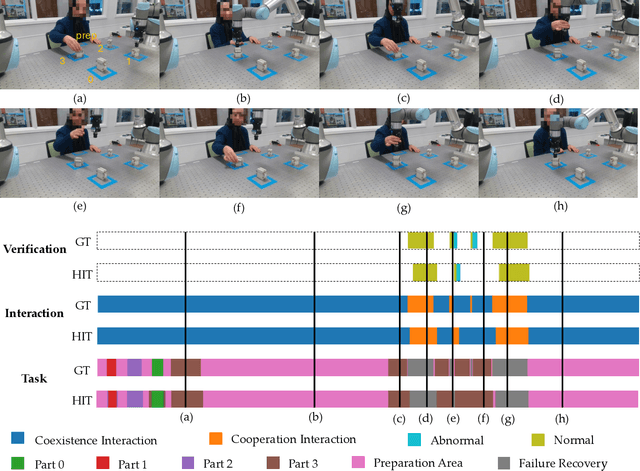
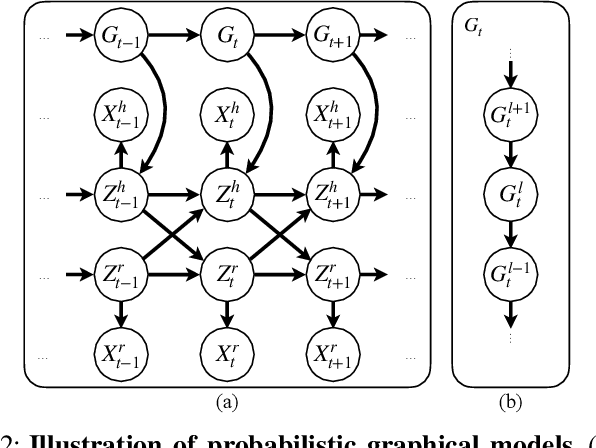
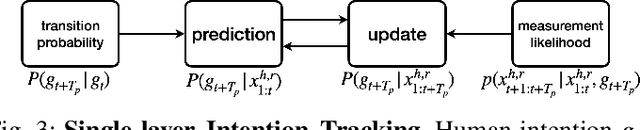
During collaborative tasks, human behavior is guided by multiple levels of intentions that evolve over time, such as task sequence preferences and interaction strategies. To adapt to these changing preferences and promptly correct any inaccurate estimations, collaborative robots must accurately track these dynamic human intentions in real time. We propose a Hierarchical Intention Tracking (HIT) algorithm for collaborative robots to track dynamic and hierarchical human intentions effectively in real time. HIT represents human intentions as intention trees with arbitrary depth, and probabilistically tracks human intentions by Bayesian filtering, upward measurement propagation, and downward posterior propagation across all levels. We develop a HIT-based robotic system that dynamically switches between Interaction-Task and Verification-Task trees for a collaborative assembly task, allowing the robot to effectively coordinate human intentions at three levels: task-level (subtask goal locations), interaction-level (mode of engagement with the robot), and verification-level (confirming or correcting intention recognition). Our user study shows that our HIT-based collaborative robot system surpasses existing collaborative robot solutions by achieving a balance between efficiency, physical workload, and user comfort while ensuring safety and task completion. Post-experiment surveys further reveal that the HIT-based system enhances the user trust and minimizes interruptions to user's task flow through its effective understanding of human intentions across multiple levels.
From predictions to confidence intervals: an empirical study of conformal prediction methods for in-context learning
Apr 22, 2025Transformers have become a standard architecture in machine learning, demonstrating strong in-context learning (ICL) abilities that allow them to learn from the prompt at inference time. However, uncertainty quantification for ICL remains an open challenge, particularly in noisy regression tasks. This paper investigates whether ICL can be leveraged for distribution-free uncertainty estimation, proposing a method based on conformal prediction to construct prediction intervals with guaranteed coverage. While traditional conformal methods are computationally expensive due to repeated model fitting, we exploit ICL to efficiently generate confidence intervals in a single forward pass. Our empirical analysis compares this approach against ridge regression-based conformal methods, showing that conformal prediction with in-context learning (CP with ICL) achieves robust and scalable uncertainty estimates. Additionally, we evaluate its performance under distribution shifts and establish scaling laws to guide model training. These findings bridge ICL and conformal prediction, providing a theoretically grounded and new framework for uncertainty quantification in transformer-based models.
Layton: Latent Consistency Tokenizer for 1024-pixel Image Reconstruction and Generation by 256 Tokens
Mar 12, 2025



Image tokenization has significantly advanced visual generation and multimodal modeling, particularly when paired with autoregressive models. However, current methods face challenges in balancing efficiency and fidelity: high-resolution image reconstruction either requires an excessive number of tokens or compromises critical details through token reduction. To resolve this, we propose Latent Consistency Tokenizer (Layton) that bridges discrete visual tokens with the compact latent space of pre-trained Latent Diffusion Models (LDMs), enabling efficient representation of 1024x1024 images using only 256 tokens-a 16 times compression over VQGAN. Layton integrates a transformer encoder, a quantized codebook, and a latent consistency decoder. Direct application of LDM as the decoder results in color and brightness discrepancies. Thus, we convert it to latent consistency decoder, reducing multi-step sampling to 1-2 steps for direct pixel-level supervision. Experiments demonstrate Layton's superiority in high-fidelity reconstruction, with 10.8 reconstruction Frechet Inception Distance on MSCOCO-2017 5K benchmark for 1024x1024 image reconstruction. We also extend Layton to a text-to-image generation model, LaytonGen, working in autoregression. It achieves 0.73 score on GenEval benchmark, surpassing current state-of-the-art methods. Project homepage: https://github.com/OPPO-Mente-Lab/Layton
Interaction-aware Conformal Prediction for Crowd Navigation
Feb 10, 2025During crowd navigation, robot motion plan needs to consider human motion uncertainty, and the human motion uncertainty is dependent on the robot motion plan. We introduce Interaction-aware Conformal Prediction (ICP) to alternate uncertainty-aware robot motion planning and decision-dependent human motion uncertainty quantification. ICP is composed of a trajectory predictor to predict human trajectories, a model predictive controller to plan robot motion with confidence interval radii added for probabilistic safety, a human simulator to collect human trajectory calibration dataset conditioned on the planned robot motion, and a conformal prediction module to quantify trajectory prediction error on the decision-dependent calibration dataset. Crowd navigation simulation experiments show that ICP strikes a good balance of performance among navigation efficiency, social awareness, and uncertainty quantification compared to previous works. ICP generalizes well to navigation tasks under various crowd densities. The fast runtime and efficient memory usage make ICP practical for real-world applications. Code is available at https://github.com/tedhuang96/icp.