 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSLAMOT: A Tracklet and Query Graph-based Simultaneous Locating, Mapping, and Multiple Object Tracking System
Aug 17, 2024For interacting with mobile objects in unfamiliar environments, simultaneously locating, mapping, and tracking the 3D poses of multiple objects are crucially required. This paper proposes a Tracklet Graph and Query Graph-based framework, i.e., GSLAMOT, to address this challenge. GSLAMOT utilizes camera and LiDAR multimodal information as inputs and divides the representation of the dynamic scene into a semantic map for representing the static environment, a trajectory of the ego-agent, and an online maintained Tracklet Graph (TG) for tracking and predicting the 3D poses of the detected mobile objects. A Query Graph (QG) is constructed in each frame by object detection to query and update TG. For accurate object association, a Multi-criteria Star Graph Association (MSGA) method is proposed to find matched objects between the detections in QG and the predicted tracklets in TG. Then, an Object-centric Graph Optimization (OGO) method is proposed to simultaneously optimize the TG, the semantic map, and the agent trajectory. It triangulates the detected objects into the map to enrich the map's semantic information. We address the efficiency issues to handle the three tightly coupled tasks in parallel. Experiments are conducted on KITTI, Waymo, and an emulated Traffic Congestion dataset that highlights challenging scenarios. Experiments show that GSLAMOT enables accurate crowded object tracking while conducting SLAM accurately in challenging scenarios, demonstrating more excellent performances than the state-of-the-art methods. The code and dataset are at https://gslamot.github.io.
IDLL: Inverse Depth Line based Visual Localization in Challenging Environments
Apr 23, 2023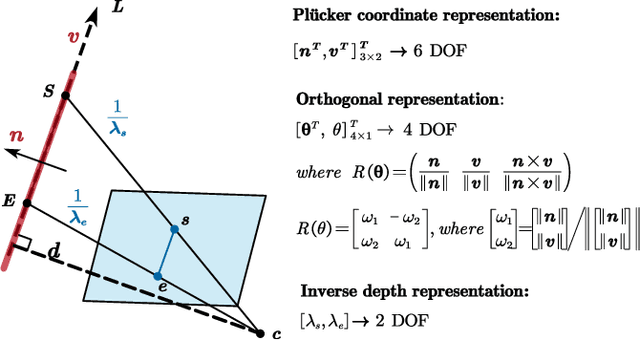

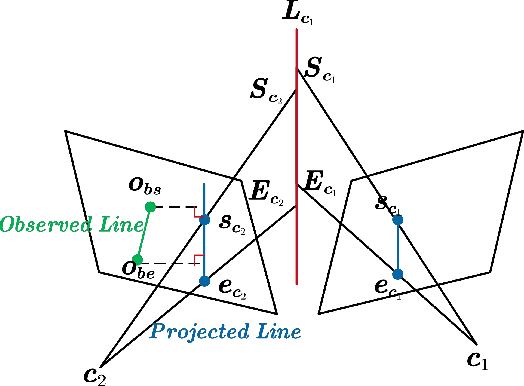
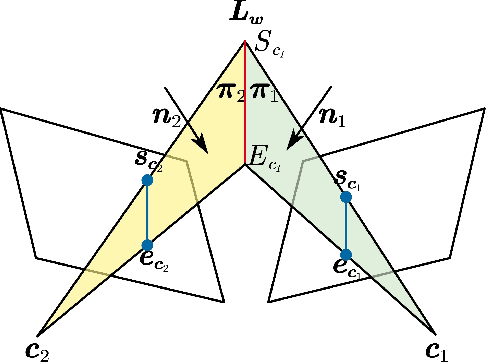
Precise and real-time localization of unmanned aerial vehicles (UAVs) or robots in GNSS denied indoor environments are critically important for various logistics and surveillance applications. Vision-based simultaneously locating and mapping (VSLAM) are key solutions but suffer location drifts in texture-less, man-made indoor environments. Line features are rich in man-made environments which can be exploited to improve the localization robustness, but existing point-line based VSLAM methods still lack accuracy and efficiency for the representation of lines introducing unnecessary degrees of freedoms. In this paper, we propose Inverse Depth Line Localization(IDLL), which models each extracted line feature using two inverse depth variables exploiting the fact that the projected pixel coordinates on the image plane are rather accurate, which partially restrict the lines. This freedom-reduced representation of lines enables easier line determination and faster convergence of bundle adjustment in each step, therefore achieves more accurate and more efficient frame-to-frame registration and frame-to-map registration using both point and line visual features. We redesign the whole front-end and back-end modules of VSLAM using this line model. IDLL is extensively evaluated in multiple perceptually-challenging datasets. The results show it is more accurate, robust, and needs lower computational overhead than the current state-of-the-art of feature-based VSLAM methods.
ViPFormer: Efficient Vision-and-Pointcloud Transformer for Unsupervised Pointcloud Understanding
Mar 25, 2023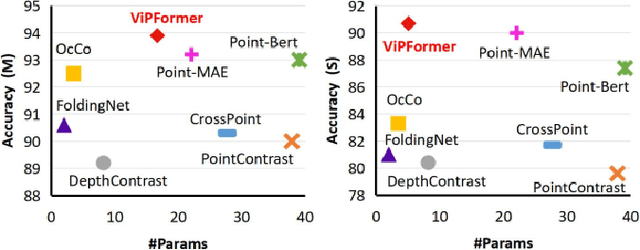
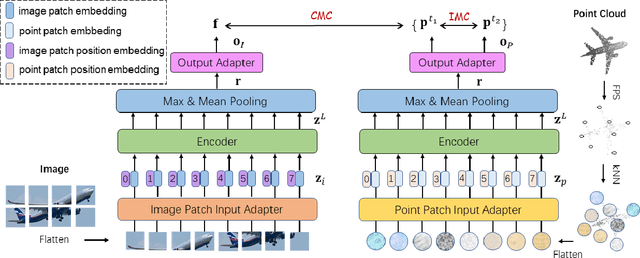

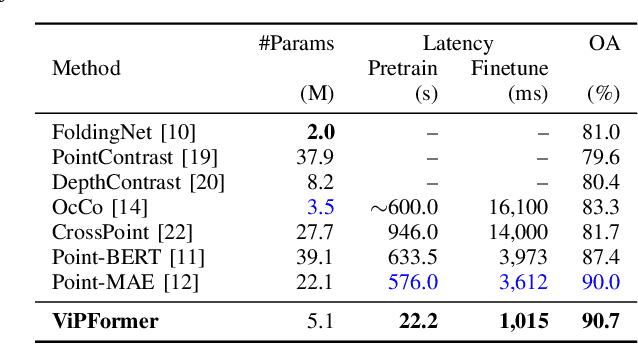
Recently, a growing number of work design unsupervised paradigms for point cloud processing to alleviate the limitation of expensive manual annotation and poor transferability of supervised methods. Among them, CrossPoint follows the contrastive learning framework and exploits image and point cloud data for unsupervised point cloud understanding. Although the promising performance is presented, the unbalanced architecture makes it unnecessarily complex and inefficient. For example, the image branch in CrossPoint is $\sim$8.3x heavier than the point cloud branch leading to higher complexity and latency. To address this problem, in this paper, we propose a lightweight Vision-and-Pointcloud Transformer (ViPFormer) to unify image and point cloud processing in a single architecture. ViPFormer learns in an unsupervised manner by optimizing intra-modal and cross-modal contrastive objectives. Then the pretrained model is transferred to various downstream tasks, including 3D shape classification and semantic segmentation. Experiments on different datasets show ViPFormer surpasses previous state-of-the-art unsupervised methods with higher accuracy, lower model complexity and runtime latency. Finally, the effectiveness of each component in ViPFormer is validated by extensive ablation studies. The implementation of the proposed method is available at https://github.com/auniquesun/ViPFormer.