 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSS-UAgent: An Agent-based Usability Evaluation Framework for Open Source Software
May 29, 2025Usability evaluation is critical to the impact and adoption of open source software (OSS), yet traditional methods relying on human evaluators suffer from high costs and limited scalability. To address these limitations, we introduce OSS-UAgent, an automated, configurable, and interactive agent-based usability evaluation framework specifically designed for open source software. Our framework employs intelligent agents powered by large language models (LLMs) to simulate developers performing programming tasks across various experience levels (from Junior to Expert). By dynamically constructing platform-specific knowledge bases, OSS-UAgent ensures accurate and context-aware code generation. The generated code is automatically evaluated across multiple dimensions, including compliance, correctness, and readability, providing a comprehensive measure of the software's usability. Additionally, our demonstration showcases OSS-UAgent's practical application in evaluating graph analytics platforms, highlighting its effectiveness in automating usability evaluation.
A Novel Methodology in Credit Spread Prediction Based on Ensemble Learning and Feature Selection
Dec 13, 2024The credit spread is a key indicator in bond investments, offering valuable insights for fixed-income investors to devise effective trading strategies. This study proposes a novel credit spread forecasting model leveraging ensemble learning techniques. To enhance predictive accuracy, a feature selection method based on mutual information is incorporated. Empirical results demonstrate that the proposed methodology delivers superior accuracy in credit spread predictions. Additionally, we present a forecast of future credit spread trends using current data, providing actionable insights for investment decision-making.
1-bit Quantized On-chip Hybrid Diffraction Neural Network Enabled by Authentic All-optical Fully-connected Architecture
Apr 11, 2024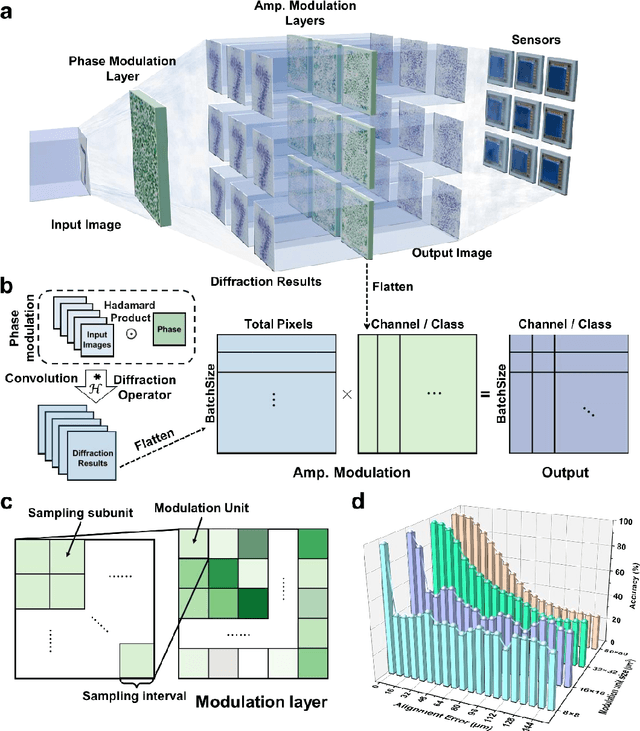
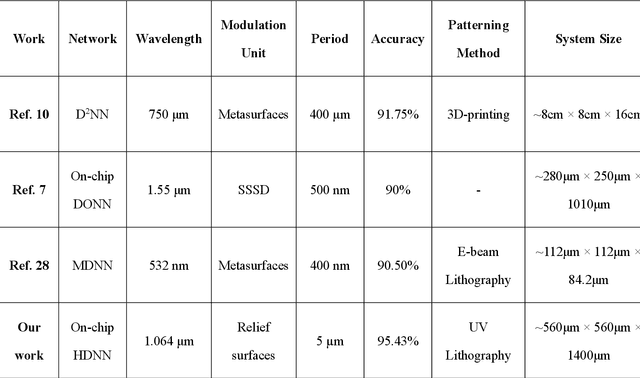

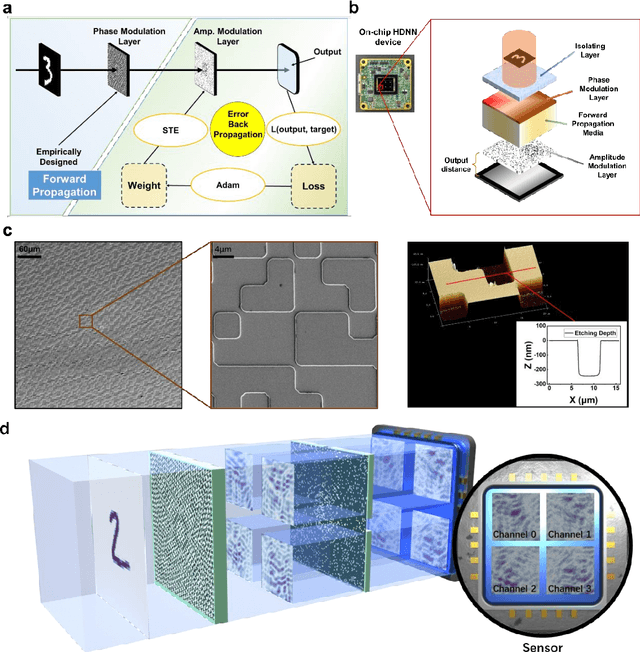
Optical Diffraction Neural Networks (DNNs), a subset of Optical Neural Networks (ONNs), show promise in mirroring the prowess of electronic networks. This study introduces the Hybrid Diffraction Neural Network (HDNN), a novel architecture that incorporates matrix multiplication into DNNs, synergizing the benefits of conventional ONNs with those of DNNs to surmount the modulation limitations inherent in optical diffraction neural networks. Utilizing a singular phase modulation layer and an amplitude modulation layer, the trained neural network demonstrated remarkable accuracies of 96.39% and 89% in digit recognition tasks in simulation and experiment, respectively. Additionally, we develop the Binning Design (BD) method, which effectively mitigates the constraints imposed by sampling intervals on diffraction units, substantially streamlining experimental procedures. Furthermore, we propose an on-chip HDNN that not only employs a beam-splitting phase modulation layer for enhanced integration level but also significantly relaxes device fabrication requirements, replacing metasurfaces with relief surfaces designed by 1-bit quantization. Besides, we conceptualized an all-optical HDNN-assisted lesion detection network, achieving detection outcomes that were 100% aligned with simulation predictions. This work not only advances the performance of DNNs but also streamlines the path towards industrial optical neural network production.
VOLoc: Visual Place Recognition by Querying Compressed Lidar Map
Feb 25, 2024



The availability of city-scale Lidar maps enables the potential of city-scale place recognition using mobile cameras. However, the city-scale Lidar maps generally need to be compressed for storage efficiency, which increases the difficulty of direct visual place recognition in compressed Lidar maps. This paper proposes VOLoc, an accurate and efficient visual place recognition method that exploits geometric similarity to directly query the compressed Lidar map via the real-time captured image sequence. In the offline phase, VOLoc compresses the Lidar maps using a \emph{Geometry-Preserving Compressor} (GPC), in which the compression is reversible, a crucial requirement for the downstream 6DoF pose estimation. In the online phase, VOLoc proposes an online Geometric Recovery Module (GRM), which is composed of online Visual Odometry (VO) and a point cloud optimization module, such that the local scene structure around the camera is online recovered to build the \emph{Querying Point Cloud} (QPC). Then the QPC is compressed by the same GPC, and is aggregated into a global descriptor by an attention-based aggregation module, to query the compressed Lidar map in the vector space. A transfer learning mechanism is also proposed to improve the accuracy and the generality of the aggregation network. Extensive evaluations show that VOLoc provides localization accuracy even better than the Lidar-to-Lidar place recognition, setting up a new record for utilizing the compressed Lidar map by low-end mobile cameras. The code are publicly available at https://github.com/Master-cai/VOLoc.
IDLL: Inverse Depth Line based Visual Localization in Challenging Environments
Apr 23, 2023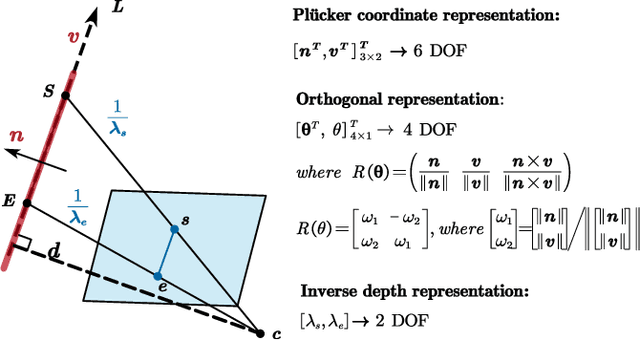

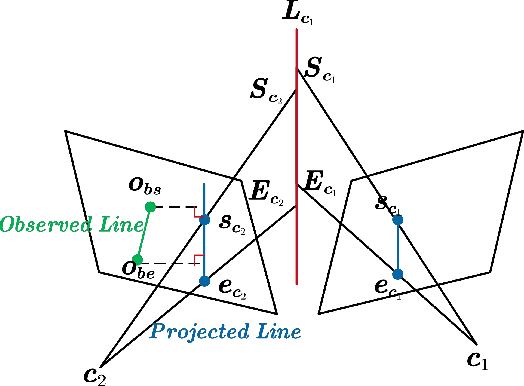
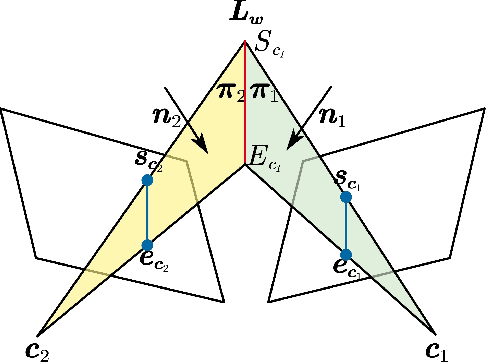
Precise and real-time localization of unmanned aerial vehicles (UAVs) or robots in GNSS denied indoor environments are critically important for various logistics and surveillance applications. Vision-based simultaneously locating and mapping (VSLAM) are key solutions but suffer location drifts in texture-less, man-made indoor environments. Line features are rich in man-made environments which can be exploited to improve the localization robustness, but existing point-line based VSLAM methods still lack accuracy and efficiency for the representation of lines introducing unnecessary degrees of freedoms. In this paper, we propose Inverse Depth Line Localization(IDLL), which models each extracted line feature using two inverse depth variables exploiting the fact that the projected pixel coordinates on the image plane are rather accurate, which partially restrict the lines. This freedom-reduced representation of lines enables easier line determination and faster convergence of bundle adjustment in each step, therefore achieves more accurate and more efficient frame-to-frame registration and frame-to-map registration using both point and line visual features. We redesign the whole front-end and back-end modules of VSLAM using this line model. IDLL is extensively evaluated in multiple perceptually-challenging datasets. The results show it is more accurate, robust, and needs lower computational overhead than the current state-of-the-art of feature-based VSLAM methods.
AirBirds: A Large-scale Challenging Dataset for Bird Strike Prevention in Real-world Airports
Apr 23, 2023One fundamental limitation to the research of bird strike prevention is the lack of a large-scale dataset taken directly from real-world airports. Existing relevant datasets are either small in size or not dedicated for this purpose. To advance the research and practical solutions for bird strike prevention, in this paper, we present a large-scale challenging dataset AirBirds that consists of 118,312 time-series images, where a total of 409,967 bounding boxes of flying birds are manually, carefully annotated. The average size of all annotated instances is smaller than 10 pixels in 1920x1080 images. Images in the dataset are captured over 4 seasons of a whole year by a network of cameras deployed at a real-world airport, covering diverse bird species, lighting conditions and 13 meteorological scenarios. To the best of our knowledge, it is the first large-scale image dataset that directly collects flying birds in real-world airports for bird strike prevention. This dataset is publicly available at https://airbirdsdata.github.io/.