 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Image: Pushing the Boundaries of Generative Visual Intelligence
Apr 21, 2026We present Wan-Image, a unified visual generation system explicitly engineered to paradigm-shift image generation models from casual synthesizers into professional-grade productivity tools. While contemporary diffusion models excel at aesthetic generation, they frequently encounter critical bottlenecks in rigorous design workflows that demand absolute controllability, complex typography rendering, and strict identity preservation. To address these challenges, Wan-Image features a natively unified multi-modal architecture by synergizing the cognitive capabilities of large language models with the high-fidelity pixel synthesis of diffusion transformers, which seamlessly translates highly nuanced user intents into precise visual outputs. It is fundamentally powered by large-scale multi-modal data scaling, a systematic fine-grained annotation engine, and curated reinforcement learning data to surpass basic instruction following and unlock expert-level professional capabilities. These include ultra-long complex text rendering, hyper-diverse portrait generation, palette-guided generation, multi-subject identity preservation, coherent sequential visual generation, precise multi-modal interactive editing, native alpha-channel generation, and high-efficiency 4K synthesis. Across diverse human evaluations, Wan-Image exceeds Seedream 5.0 Lite and GPT Image 1.5 in overall performance, reaching parity with Nano Banana Pro in challenging tasks. Ultimately, Wan-Image revolutionizes visual content creation across e-commerce, entertainment, education, and personal productivity, redefining the boundaries of professional visual synthesis.
A Hypergraph-Based Framework for Exploratory Business Intelligence
Mar 11, 2026Business Intelligence (BI) analysis is evolving towards Exploratory BI, an iterative, multi-round exploration paradigm where analysts progressively refine their understanding. However, traditional BI systems impose critical limits for Exploratory BI: heavy reliance on expert knowledge, high computational costs, static schemas, and lack of reusability. We present ExBI, a novel system that introduces the hypergraph data model with operators, including Source, Join, and View, to enable dynamic schema evolution and materialized view reuse. Using sampling-based algorithms with provable estimation guarantees, ExBI addresses the computational bottlenecks, while maintaining analytical accuracy. Experiments on LDBC datasets demonstrate that ExBI achieves significant speedups over existing systems: on average 16.21x (up to 146.25x) compared to Neo4j and 46.67x (up to 230.53x) compared to MySQL, while maintaining high accuracy with an average error rate of only 0.27% for COUNT, enabling efficient and accurate large-scale exploratory BI workflows.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
OSS-UAgent: An Agent-based Usability Evaluation Framework for Open Source Software
May 29, 2025Usability evaluation is critical to the impact and adoption of open source software (OSS), yet traditional methods relying on human evaluators suffer from high costs and limited scalability. To address these limitations, we introduce OSS-UAgent, an automated, configurable, and interactive agent-based usability evaluation framework specifically designed for open source software. Our framework employs intelligent agents powered by large language models (LLMs) to simulate developers performing programming tasks across various experience levels (from Junior to Expert). By dynamically constructing platform-specific knowledge bases, OSS-UAgent ensures accurate and context-aware code generation. The generated code is automatically evaluated across multiple dimensions, including compliance, correctness, and readability, providing a comprehensive measure of the software's usability. Additionally, our demonstration showcases OSS-UAgent's practical application in evaluating graph analytics platforms, highlighting its effectiveness in automating usability evaluation.
SRDiffusion: Accelerate Video Diffusion Inference via Sketching-Rendering Cooperation
May 25, 2025Leveraging the diffusion transformer (DiT) architecture, models like Sora, CogVideoX and Wan have achieved remarkable progress in text-to-video, image-to-video, and video editing tasks. Despite these advances, diffusion-based video generation remains computationally intensive, especially for high-resolution, long-duration videos. Prior work accelerates its inference by skipping computation, usually at the cost of severe quality degradation. In this paper, we propose SRDiffusion, a novel framework that leverages collaboration between large and small models to reduce inference cost. The large model handles high-noise steps to ensure semantic and motion fidelity (Sketching), while the smaller model refines visual details in low-noise steps (Rendering). Experimental results demonstrate that our method outperforms existing approaches, over 3$\times$ speedup for Wan with nearly no quality loss for VBench, and 2$\times$ speedup for CogVideoX. Our method is introduced as a new direction orthogonal to existing acceleration strategies, offering a practical solution for scalable video generation.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
Static Batching of Irregular Workloads on GPUs: Framework and Application to Efficient MoE Model Inference
Jan 27, 2025
It has long been a problem to arrange and execute irregular workloads on massively parallel devices. We propose a general framework for statically batching irregular workloads into a single kernel with a runtime task mapping mechanism on GPUs. We further apply this framework to Mixture-of-Experts (MoE) model inference and implement an optimized and efficient CUDA kernel. Our MoE kernel achieves up to 91% of the peak Tensor Core throughput on NVIDIA H800 GPU and 95% on NVIDIA H20 GPU.
Qwen2.5-1M Technical Report
Jan 26, 2025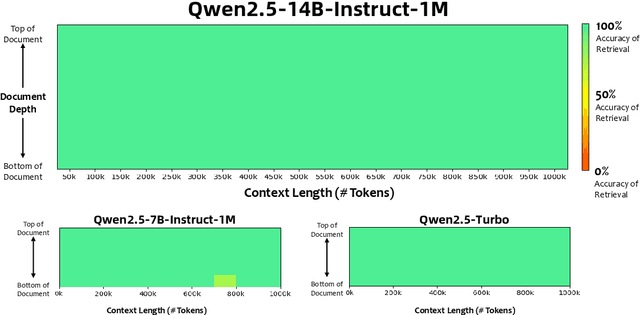

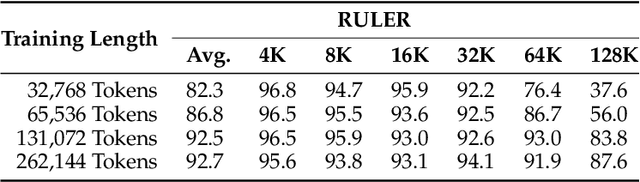
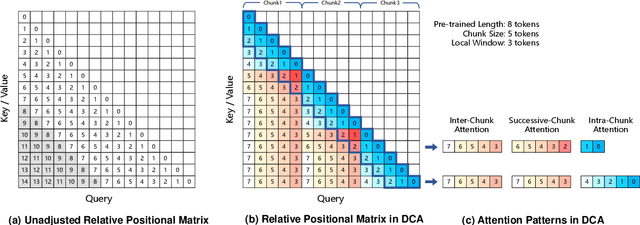
We introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series have significantly enhanced long-context capabilities through long-context pre-training and post-training. Key techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to effectively enhance long-context performance while reducing training costs. To promote the use of long-context models among a broader user base, we present and open-source our inference framework. This framework includes a length extrapolation method that can expand the model context lengths by at least four times, or even more, without additional training. To reduce inference costs, we implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, we detail our optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. By leveraging our inference framework, the Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context. This framework provides an efficient and powerful solution for developing applications that require long-context processing using open-source models. The Qwen2.5-1M series currently includes the open-source models Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, as well as the API-accessed model Qwen2.5-Turbo. Evaluations show that Qwen2.5-1M models have been greatly improved in long-context tasks without compromising performance in short-context scenarios. Specifically, the Qwen2.5-14B-Instruct-1M model significantly outperforms GPT-4o-mini in long-context tasks and supports contexts eight times longer.
Exact Acceleration of Subgraph Graph Neural Networks by Eliminating Computation Redundancy
Dec 24, 2024



Graph neural networks (GNNs) have become a prevalent framework for graph tasks. Many recent studies have proposed the use of graph convolution methods over the numerous subgraphs of each graph, a concept known as subgraph graph neural networks (subgraph GNNs), to enhance GNNs' ability to distinguish non-isomorphic graphs. To maximize the expressiveness, subgraph GNNs often require each subgraph to have equal size to the original graph. Despite their impressive performance, subgraph GNNs face challenges due to the vast number and large size of subgraphs which lead to a surge in training data, resulting in both storage and computational inefficiencies. In response to this problem, this paper introduces Ego-Nets-Fit-All (ENFA), a model that uniformly takes the smaller ego nets as subgraphs, thereby providing greater storage and computational efficiency, while at the same time guarantees identical outputs to the original subgraph GNNs even taking the whole graph as subgraphs. The key is to identify and eliminate the redundant computation among subgraphs. For example, a node $v_i$ may appear in multiple subgraphs but is far away from all of their centers (the unsymmetric part between subgraphs). Therefore, its first few rounds of message passing within each subgraph can be computed once in the original graph instead of being computed multiple times within each subgraph. Such strategy enables our ENFA to accelerate subgraph GNNs in an exact way, unlike previous sampling approaches that often lose the performance. Extensive experiments across various datasets reveal that compared with the conventional subgraph GNNs, ENFA can reduce storage space by 29.0% to 84.5% and improve training efficiency by up to 1.66x.
AsymKV: Enabling 1-Bit Quantization of KV Cache with Layer-Wise Asymmetric Quantization Configurations
Oct 17, 2024



Large language models have shown exceptional capabilities in a wide range of tasks, such as text generation and video generation, among others. However, due to their massive parameter count, these models often require substantial storage space, imposing significant constraints on the machines deploying LLMs. To overcome this limitation, one research direction proposes to compress the models using integer replacements for floating-point numbers, in a process known as Quantization. Some recent studies suggest quantizing the key and value cache (KV Cache) of LLMs, and designing quantization techniques that treat the key and value matrices equivalently. This work delves deeper into the asymmetric structural roles of KV Cache, a phenomenon where the transformer's output loss is more sensitive to the quantization of key matrices. We conduct a systematic examination of the attention output error resulting from key and value quantization. The phenomenon inspires us to propose an asymmetric quantization strategy. Our approach allows for 1-bit quantization of the KV cache by implementing distinct configurations for key and value matrices. We carry out experiments across a variety of datasets, demonstrating that our proposed model allows for the quantization of up to 75% decoder layers with 1 bit, while simultaneously maintaining performance levels comparable to those of the models with floating parameters.