 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRDiffusion: Accelerate Video Diffusion Inference via Sketching-Rendering Cooperation
May 25, 2025Leveraging the diffusion transformer (DiT) architecture, models like Sora, CogVideoX and Wan have achieved remarkable progress in text-to-video, image-to-video, and video editing tasks. Despite these advances, diffusion-based video generation remains computationally intensive, especially for high-resolution, long-duration videos. Prior work accelerates its inference by skipping computation, usually at the cost of severe quality degradation. In this paper, we propose SRDiffusion, a novel framework that leverages collaboration between large and small models to reduce inference cost. The large model handles high-noise steps to ensure semantic and motion fidelity (Sketching), while the smaller model refines visual details in low-noise steps (Rendering). Experimental results demonstrate that our method outperforms existing approaches, over 3$\times$ speedup for Wan with nearly no quality loss for VBench, and 2$\times$ speedup for CogVideoX. Our method is introduced as a new direction orthogonal to existing acceleration strategies, offering a practical solution for scalable video generation.
Galaxy: A Resource-Efficient Collaborative Edge AI System for In-situ Transformer Inference
May 27, 2024



Transformer-based models have unlocked a plethora of powerful intelligent applications at the edge, such as voice assistant in smart home. Traditional deployment approaches offload the inference workloads to the remote cloud server, which would induce substantial pressure on the backbone network as well as raise users' privacy concerns. To address that, in-situ inference has been recently recognized for edge intelligence, but it still confronts significant challenges stemming from the conflict between intensive workloads and limited on-device computing resources. In this paper, we leverage our observation that many edge environments usually comprise a rich set of accompanying trusted edge devices with idle resources and propose Galaxy, a collaborative edge AI system that breaks the resource walls across heterogeneous edge devices for efficient Transformer inference acceleration. Galaxy introduces a novel hybrid model parallelism to orchestrate collaborative inference, along with a heterogeneity-aware parallelism planning for fully exploiting the resource potential. Furthermore, Galaxy devises a tile-based fine-grained overlapping of communication and computation to mitigate the impact of tensor synchronizations on inference latency under bandwidth-constrained edge environments. Extensive evaluation based on prototype implementation demonstrates that Galaxy remarkably outperforms state-of-the-art approaches under various edge environment setups, achieving up to 2.5x end-to-end latency reduction.
SAIH: A Scalable Evaluation Methodology for Understanding AI Performance Trend on HPC Systems
Dec 07, 2022Novel artificial intelligence (AI) technology has expedited various scientific research, e.g., cosmology, physics and bioinformatics, inevitably becoming a significant category of workload on high performance computing (HPC) systems. Existing AI benchmarks tend to customize well-recognized AI applications, so as to evaluate the AI performance of HPC systems under predefined problem size, in terms of datasets and AI models. Due to lack of scalability on the problem size, static AI benchmarks might be under competent to help understand the performance trend of evolving AI applications on HPC systems, in particular, the scientific AI applications on large-scale systems. In this paper, we propose a scalable evaluation methodology (SAIH) for analyzing the AI performance trend of HPC systems with scaling the problem sizes of customized AI applications. To enable scalability, SAIH builds a set of novel mechanisms for augmenting problem sizes. As the data and model constantly scale, we can investigate the trend and range of AI performance on HPC systems, and further diagnose system bottlenecks. To verify our methodology, we augment a cosmological AI application to evaluate a real HPC system equipped with GPUs as a case study of SAIH.
EnergonAI: An Inference System for 10-100 Billion Parameter Transformer Models
Sep 06, 2022
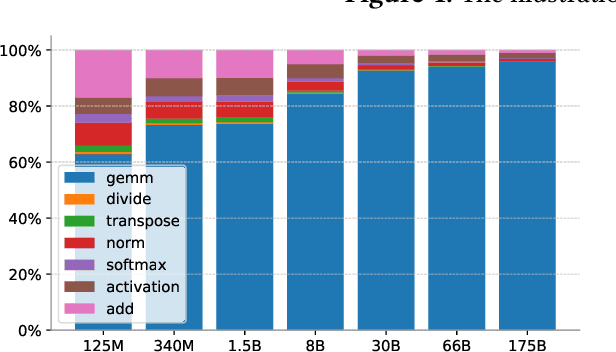
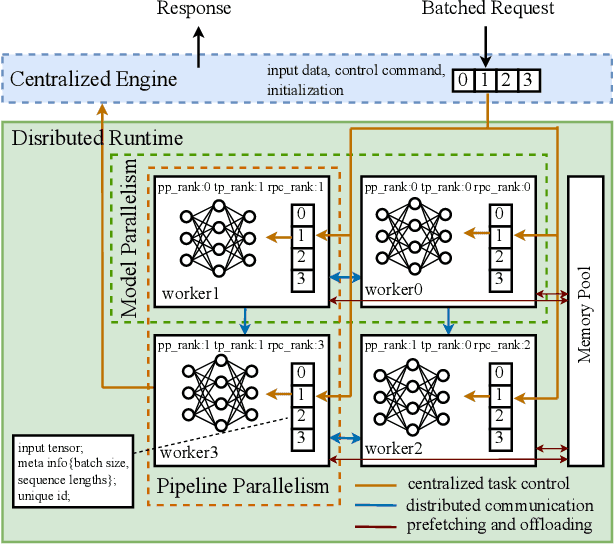
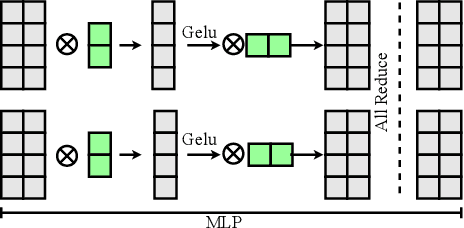
Large transformer models display promising performance on a wide range of natural language processing (NLP) tasks. Although the AI community has expanded the model scale to the trillion parameter level, the practical deployment of 10-100 billion parameter models is still uncertain due to the latency, throughput, and memory constraints. In this paper, we proposed EnergonAI to solve the challenges of the efficient deployment of 10-100 billion parameter transformer models on single- or multi-GPU systems. EnergonAI adopts a hierarchy-controller system architecture to coordinate multiple devices and efficiently support different parallel patterns. It delegates the execution of sub-models to multiple workers in the single-controller style and applies tensor parallelism and pipeline parallelism among the workers in a multi-controller style. Upon the novel architecture, we propose three techniques, i.e. non-blocking pipeline parallelism, distributed redundant computation elimination, and peer memory pooling. EnergonAI enables the users to program complex parallel code the same as a serial one. Compared with the FasterTransformer, we have proven that EnergonAI has superior performance on latency and throughput. In our experiments, EnergonAI can achieve 37% latency reduction in tensor parallelism, 10% scalability improvement in pipeline parallelism, and it improves the model scale inferred on a single GPU by using a larger heterogeneous memory space at cost of limited performance reduction.