 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Diffusion for Crystal Structure Prediction
Dec 08, 2025In addressing the challenge of Crystal Structure Prediction (CSP), symmetry-aware deep learning models, particularly diffusion models, have been extensively studied, which treat CSP as a conditional generation task. However, ensuring permutation, rotation, and periodic translation equivariance during diffusion process remains incompletely addressed. In this work, we propose EquiCSP, a novel equivariant diffusion-based generative model. We not only address the overlooked issue of lattice permutation equivariance in existing models, but also develop a unique noising algorithm that rigorously maintains periodic translation equivariance throughout both training and inference processes. Our experiments indicate that EquiCSP significantly surpasses existing models in terms of generating accurate structures and demonstrates faster convergence during the training process.
PolyKAN: Efficient Fused GPU Operators for Polynomial Kolmogorov-Arnold Network Variants
Nov 18, 2025Kolmogorov-Arnold Networks (KANs) promise higher expressive capability and stronger interpretability than Multi-Layer Perceptron, particularly in the domain of AI for Science. However, practical adoption has been hindered by low GPU utilization of existing parallel implementations. To address this challenge, we present a GPU-accelerated operator library, named PolyKAN which is the first general open-source implementation of KAN and its variants. PolyKAN fuses the forward and backward passes of polynomial KAN layers into a concise set of optimized CUDA kernels. Four orthogonal techniques underpin the design: (i) \emph{lookup-table} with linear interpolation that replaces runtime expensive math-library functions; (ii) \emph{2D tiling} to expose thread-level parallelism with preserving memory locality; (iii) a \emph{two-stage reduction} scheme converting scattered atomic updates into a single controllable merge step; and (iv) \emph{coefficient-layout reordering} yielding unit-stride reads under the tiled schedule. Using a KAN variant, Chebyshev KAN, as a case-study, PolyKAN delivers $1.2$--$10\times$ faster inference and $1.4$--$12\times$ faster training than a Triton + cuBLAS baseline, with identical accuracy on speech, audio-enhancement, and tabular-regression workloads on both highend GPU and consumer-grade GPU.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025



Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
PDeepPP:A Deep learning framework with Pretrained Protein language for peptide classification
Feb 21, 2025Protein post-translational modifications (PTMs) and bioactive peptides (BPs) play critical roles in various biological processes and have significant therapeutic potential. However, identifying PTM sites and bioactive peptides through experimental methods is often labor-intensive, costly, and time-consuming. As a result, computational tools, particularly those based on deep learning, have become effective solutions for predicting PTM sites and peptide bioactivity. Despite progress in this field, existing methods still struggle with the complexity of protein sequences and the challenge of requiring high-quality predictions across diverse datasets. To address these issues, we propose a deep learning framework that integrates pretrained protein language models with a neural network combining transformer and CNN for peptide classification. By leveraging the ability of pretrained models to capture complex relationships within protein sequences, combined with the predictive power of parallel networks, our approach improves feature extraction while enhancing prediction accuracy. This framework was applied to multiple tasks involving PTM site and bioactive peptide prediction, utilizing large-scale datasets to enhance the model's robustness. In the comparison across 33 tasks, the model achieved state-of-the-art (SOTA) performance in 25 of them, surpassing existing methods and demonstrating its versatility across different datasets. Our results suggest that this approach provides a scalable and effective solution for large-scale peptide discovery and PTM analysis, paving the way for more efficient peptide classification and functional annotation.
LessLeak-Bench: A First Investigation of Data Leakage in LLMs Across 83 Software Engineering Benchmarks
Feb 10, 2025
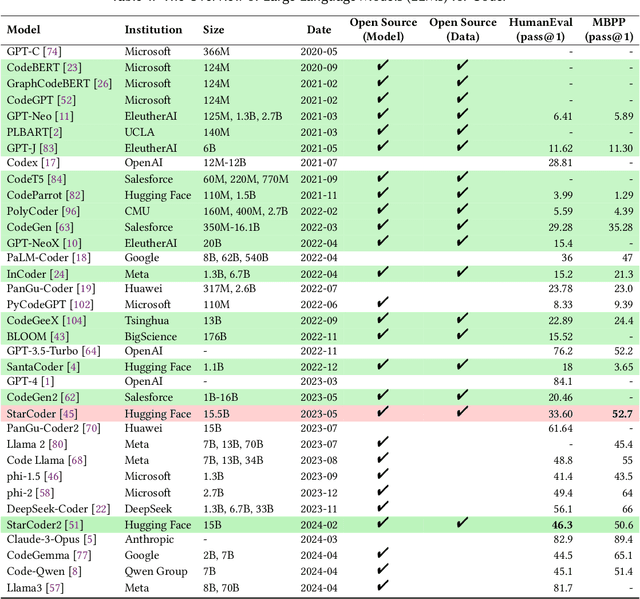

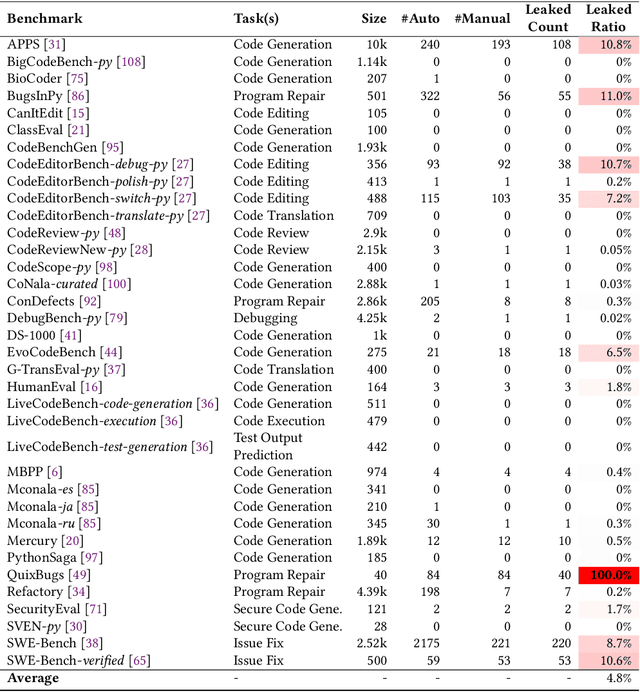
Large Language Models (LLMs) are widely utilized in software engineering (SE) tasks, such as code generation and automated program repair. However, their reliance on extensive and often undisclosed pre-training datasets raises significant concerns about data leakage, where the evaluation benchmark data is unintentionally ``seen'' by LLMs during the model's construction phase. The data leakage issue could largely undermine the validity of LLM-based research and evaluations. Despite the increasing use of LLMs in the SE community, there is no comprehensive study that assesses the extent of data leakage in SE benchmarks for LLMs yet. To address this gap, this paper presents the first large-scale analysis of data leakage in 83 SE benchmarks concerning LLMs. Our results show that in general, data leakage in SE benchmarks is minimal, with average leakage ratios of only 4.8\%, 2.8\%, and 0.7\% for Python, Java, and C/C++ benchmarks, respectively. However, some benchmarks exhibit relatively higher leakage ratios, which raises concerns about their bias in evaluation. For instance, QuixBugs and BigCloneBench have leakage ratios of 100.0\% and 55.7\%, respectively. Furthermore, we observe that data leakage has a substantial impact on LLM evaluation. We also identify key causes of high data leakage, such as the direct inclusion of benchmark data in pre-training datasets and the use of coding platforms like LeetCode for benchmark construction. To address the data leakage, we introduce \textbf{LessLeak-Bench}, a new benchmark that removes leaked samples from the 83 SE benchmarks, enabling more reliable LLM evaluations in future research. Our study enhances the understanding of data leakage in SE benchmarks and provides valuable insights for future research involving LLMs in SE.
Multi-modal Data Binding for Survival Analysis Modeling with Incomplete Data and Annotations
Jul 25, 2024Survival analysis stands as a pivotal process in cancer treatment research, crucial for predicting patient survival rates accurately. Recent advancements in data collection techniques have paved the way for enhancing survival predictions by integrating information from multiple modalities. However, real-world scenarios often present challenges with incomplete data, particularly when dealing with censored survival labels. Prior works have addressed missing modalities but have overlooked incomplete labels, which can introduce bias and limit model efficacy. To bridge this gap, we introduce a novel framework that simultaneously handles incomplete data across modalities and censored survival labels. Our approach employs advanced foundation models to encode individual modalities and align them into a universal representation space for seamless fusion. By generating pseudo labels and incorporating uncertainty, we significantly enhance predictive accuracy. The proposed method demonstrates outstanding prediction accuracy in two survival analysis tasks on both employed datasets. This innovative approach overcomes limitations associated with disparate modalities and improves the feasibility of comprehensive survival analysis using multiple large foundation models.
Pathology-knowledge Enhanced Multi-instance Prompt Learning for Few-shot Whole Slide Image Classification
Jul 15, 2024



Current multi-instance learning algorithms for pathology image analysis often require a substantial number of Whole Slide Images for effective training but exhibit suboptimal performance in scenarios with limited learning data. In clinical settings, restricted access to pathology slides is inevitable due to patient privacy concerns and the prevalence of rare or emerging diseases. The emergence of the Few-shot Weakly Supervised WSI Classification accommodates the significant challenge of the limited slide data and sparse slide-level labels for diagnosis. Prompt learning based on the pre-trained models (\eg, CLIP) appears to be a promising scheme for this setting; however, current research in this area is limited, and existing algorithms often focus solely on patch-level prompts or confine themselves to language prompts. This paper proposes a multi-instance prompt learning framework enhanced with pathology knowledge, \ie, integrating visual and textual prior knowledge into prompts at both patch and slide levels. The training process employs a combination of static and learnable prompts, effectively guiding the activation of pre-trained models and further facilitating the diagnosis of key pathology patterns. Lightweight Messenger (self-attention) and Summary (attention-pooling) layers are introduced to model relationships between patches and slides within the same patient data. Additionally, alignment-wise contrastive losses ensure the feature-level alignment between visual and textual learnable prompts for both patches and slides. Our method demonstrates superior performance in three challenging clinical tasks, significantly outperforming comparative few-shot methods.
Group Benefits Instances Selection for Data Purification
Mar 23, 2024Manually annotating datasets for training deep models is very labor-intensive and time-consuming. To overcome such inferiority, directly leveraging web images to conduct training data becomes a natural choice. Nevertheless, the presence of label noise in web data usually degrades the model performance. Existing methods for combating label noise are typically designed and tested on synthetic noisy datasets. However, they tend to fail to achieve satisfying results on real-world noisy datasets. To this end, we propose a method named GRIP to alleviate the noisy label problem for both synthetic and real-world datasets. Specifically, GRIP utilizes a group regularization strategy that estimates class soft labels to improve noise robustness. Soft label supervision reduces overfitting on noisy labels and learns inter-class similarities to benefit classification. Furthermore, an instance purification operation globally identifies noisy labels by measuring the difference between each training sample and its class soft label. Through operations at both group and instance levels, our approach integrates the advantages of noise-robust and noise-cleaning methods and remarkably alleviates the performance degradation caused by noisy labels. Comprehensive experimental results on synthetic and real-world datasets demonstrate the superiority of GRIP over the existing state-of-the-art methods.
AdaNAS: Adaptively Post-processing with Self-supervised Neural Architecture Search for Ensemble Rainfall Forecasts
Dec 26, 2023



Previous post-processing studies on rainfall forecasts using numerical weather prediction (NWP) mainly focus on statistics-based aspects, while learning-based aspects are rarely investigated. Although some manually-designed models are proposed to raise accuracy, they are customized networks, which need to be repeatedly tried and verified, at a huge cost in time and labor. Therefore, a self-supervised neural architecture search (NAS) method without significant manual efforts called AdaNAS is proposed in this study to perform rainfall forecast post-processing and predict rainfall with high accuracy. In addition, we design a rainfall-aware search space to significantly improve forecasts for high-rainfall areas. Furthermore, we propose a rainfall-level regularization function to eliminate the effect of noise data during the training. Validation experiments have been performed under the cases of \emph{None}, \emph{Light}, \emph{Moderate}, \emph{Heavy} and \emph{Violent} on a large-scale precipitation benchmark named TIGGE. Finally, the average mean-absolute error (MAE) and average root-mean-square error (RMSE) of the proposed AdaNAS model are 0.98 and 2.04 mm/day, respectively. Additionally, the proposed AdaNAS model is compared with other neural architecture search methods and previous studies. Compared results reveal the satisfactory performance and superiority of the proposed AdaNAS model in terms of precipitation amount prediction and intensity classification. Concretely, the proposed AdaNAS model outperformed previous best-performing manual methods with MAE and RMSE improving by 80.5\% and 80.3\%, respectively.
Co-attention Propagation Network for Zero-Shot Video Object Segmentation
Apr 08, 2023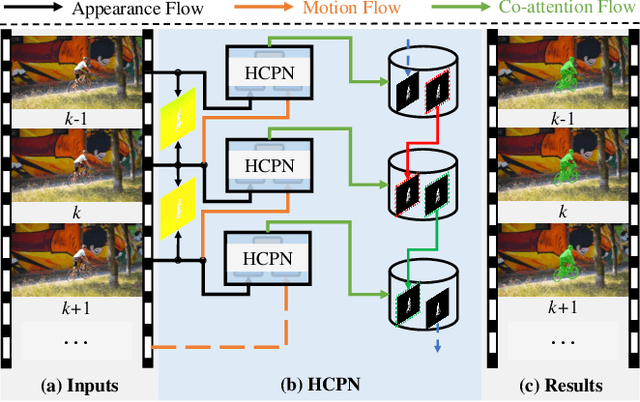
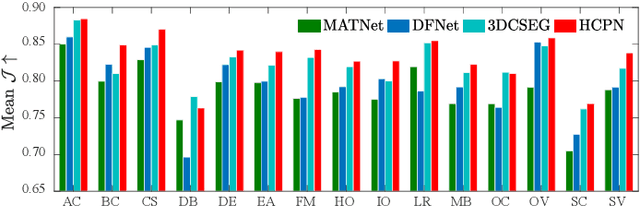

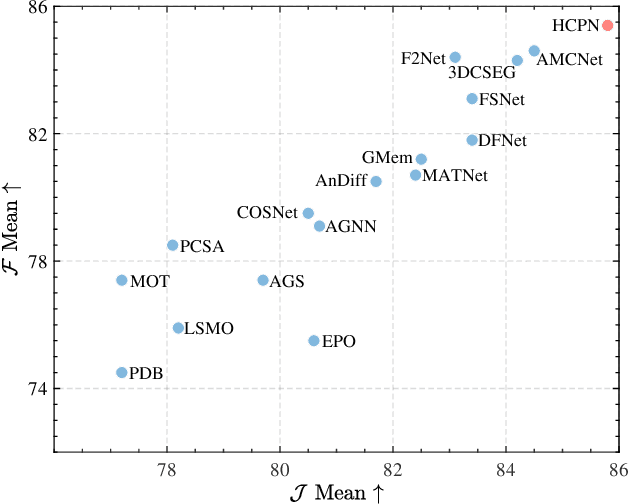
Zero-shot video object segmentation (ZS-VOS) aims to segment foreground objects in a video sequence without prior knowledge of these objects. However, existing ZS-VOS methods often struggle to distinguish between foreground and background or to keep track of the foreground in complex scenarios. The common practice of introducing motion information, such as optical flow, can lead to overreliance on optical flow estimation. To address these challenges, we propose an encoder-decoder-based hierarchical co-attention propagation network (HCPN) capable of tracking and segmenting objects. Specifically, our model is built upon multiple collaborative evolutions of the parallel co-attention module (PCM) and the cross co-attention module (CCM). PCM captures common foreground regions among adjacent appearance and motion features, while CCM further exploits and fuses cross-modal motion features returned by PCM. Our method is progressively trained to achieve hierarchical spatio-temporal feature propagation across the entire video. Experimental results demonstrate that our HCPN outperforms all previous methods on public benchmarks, showcasing its effectiveness for ZS-VOS.