 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEARL: Geometry Aligns Semantics for Training-Free Open-Vocabulary Semantic Segmentation
Mar 23, 2026Training-free open-vocabulary semantic segmentation (OVSS) promises rapid adaptation to new label sets without retraining. Yet, many methods rely on heavy post-processing or handle text and vision in isolation, leaving cross-modal geometry underutilized. Others introduce auxiliary vision backbones or multi-model pipelines, which increase complexity and latency while compromising design simplicity. We present PEARL, \textbf{\underline{P}}rocrust\textbf{\underline{e}}s \textbf{\underline{a}}lignment with text-awa\textbf{\underline{r}}e \textbf{\underline{L}}aplacian propagation, a compact two-step inference that follows an align-then-propagate principle. The Procrustes alignment step performs an orthogonal projection inside the last self-attention block, rotating keys toward the query subspace via a stable polar iteration. The text-aware Laplacian propagation then refines per-pixel logits on a small grid through a confidence-weighted, text-guided graph solve: text provides both a data-trust signal and neighbor gating, while image gradients preserve boundaries. In this work, our method is fully training-free, plug-and-play, and uses only fixed constants, adding minimal latency with a small per-head projection and a few conjugate-gradient steps. Our approach, PEARL, sets a new state-of-the-art in training-free OVSS without extra data or auxiliary backbones across standard benchmarks, achieving superior performance under both with-background and without-background protocols.
Beyond Quadratic: Linear-Time Change Detection with RWKV
Mar 20, 2026Existing paradigms for remote sensing change detection are caught in a trade-off: CNNs excel at efficiency but lack global context, while Transformers capture long-range dependencies at a prohibitive computational cost. This paper introduces ChangeRWKV, a new architecture that reconciles this conflict. By building upon the Receptance Weighted Key Value (RWKV) framework, our ChangeRWKV uniquely combines the parallelizable training of Transformers with the linear-time inference of RNNs. Our approach core features two key innovations: a hierarchical RWKV encoder that builds multi-resolution feature representation, and a novel Spatial-Temporal Fusion Module (STFM) engineered to resolve spatial misalignments across scales while distilling fine-grained temporal discrepancies. ChangeRWKV not only achieves state-of-the-art performance on the LEVIR-CD benchmark, with an 85.46% IoU and 92.16% F1 score, but does so while drastically reducing parameters and FLOPs compared to previous leading methods. This work demonstrates a new, efficient, and powerful paradigm for operational-scale change detection. Our code and model are publicly available.
Efficiency Follows Global-Local Decoupling
Mar 20, 2026Modern vision models must capture image-level context without sacrificing local detail while remaining computationally affordable. We revisit this tradeoff and advance a simple principle: decouple the roles of global reasoning and local representation. To operationalize this principle, we introduce ConvNeur, a two-branch architecture in which a lightweight neural memory branch aggregates global context on a compact set of tokens, and a locality-preserving branch extracts fine structure. A learned gate lets global cues modulate local features without entangling their objectives. This separation yields subquadratic scaling with image size, retains inductive priors associated with local processing, and reduces overhead relative to fully global attention. On standard classification, detection, and segmentation benchmarks, ConvNeur matches or surpasses comparable alternatives at similar or lower compute and offers favorable accuracy versus latency trade-offs at similar budgets. These results support the view that efficiency follows global-local decoupling.
PCA-Seg: Revisiting Cost Aggregation for Open-Vocabulary Semantic and Part Segmentation
Mar 18, 2026Recent advances in vision-language models (VLMs) have garnered substantial attention in open-vocabulary semantic and part segmentation (OSPS). However, existing methods extract image-text alignment cues from cost volumes through a serial structure of spatial and class aggregations, leading to knowledge interference between class-level semantics and spatial context. Therefore, this paper proposes a simple yet effective parallel cost aggregation (PCA-Seg) paradigm to alleviate the above challenge, enabling the model to capture richer vision-language alignment information from cost volumes. Specifically, we design an expert-driven perceptual learning (EPL) module that efficiently integrates semantic and contextual streams. It incorporates a multi-expert parser to extract complementary features from multiple perspectives. In addition, a coefficient mapper is designed to adaptively learn pixel-specific weights for each feature, enabling the integration of complementary knowledge into a unified and robust feature embedding. Furthermore, we propose a feature orthogonalization decoupling (FOD) strategy to mitigate redundancy between the semantic and contextual streams, which allows the EPL module to learn diverse knowledge from orthogonalized features. Extensive experiments on eight benchmarks show that each parallel block in PCA-Seg adds merely 0.35M parameters while achieving state-of-the-art OSPS performance.
PKINet-v2: Towards Powerful and Efficient Poly-Kernel Remote Sensing Object Detection
Mar 17, 2026Object detection in remote sensing images (RSIs) is challenged by the coexistence of geometric and spatial complexity: targets may appear with diverse aspect ratios, while spanning a wide range of object sizes under varied contexts. Existing RSI backbones address the two challenges separately, either by adopting anisotropic strip kernels to model slender targets or by using isotropic large kernels to capture broader context. However, such isolated treatments lead to complementary drawbacks: the strip-only design can disrupt spatial coherence for regular-shaped objects and weaken tiny details, whereas isotropic large kernels often introduce severe background noise and geometric mismatch for slender structures. In this paper, we extend PKINet, and present a powerful and efficient backbone that jointly handles both challenges within a unified paradigm named Poly Kernel Inception Network v2 (PKINet-v2). PKINet-v2 synergizes anisotropic axial-strip convolutions with isotropic square kernels and builds a multi-scope receptive field, preserving fine-grained local textures while progressively aggregating long-range context across scales. To enable efficient deployment, we further introduce a Heterogeneous Kernel Re-parameterization (HKR) Strategy that fuses all heterogeneous branches into a single depth-wise convolution for inference, eliminating fragmented kernel launches without accuracy loss. Extensive experiments on four widely-used benchmarks, including DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R, demonstrate that PKINet-v2 achieves state-of-the-art accuracy while delivering a $\textbf{3.9}\times$ FPS acceleration compared to PKINet-v1, surpassing previous remote sensing backbones in both effectiveness and efficiency.
Iris: Bringing Real-World Priors into Diffusion Model for Monocular Depth Estimation
Mar 17, 2026In this paper, we propose \textbf{Iris}, a deterministic framework for Monocular Depth Estimation (MDE) that integrates real-world priors into the diffusion model. Conventional feed-forward methods rely on massive training data, yet still miss details. Previous diffusion-based methods leverage rich generative priors yet struggle with synthetic-to-real domain transfer. Iris, in contrast, preserves fine details, generalizes strongly from synthetic to real scenes, and remains efficient with limited training data. To this end, we introduce a two-stage Priors-to-Geometry Deterministic (PGD) schedule: the prior stage uses Spectral-Gated Distillation (SGD) to transfer low-frequency real priors while leaving high-frequency details unconstrained, and the geometry stage applies Spectral-Gated Consistency (SGC) to enforce high-frequency fidelity while refining with synthetic ground truth. The two stages share weights and are executed with a high-to-low timestep schedule. Extensive experimental results confirm that Iris achieves significant improvements in MDE performance with strong in-the-wild generalization.
Towards Remote Sensing Change Detection with Neural Memory
Feb 11, 2026Remote sensing change detection is essential for environmental monitoring, urban planning, and related applications. However, current methods often struggle to capture long-range dependencies while maintaining computational efficiency. Although Transformers can effectively model global context, their quadratic complexity poses scalability challenges, and existing linear attention approaches frequently fail to capture intricate spatiotemporal relationships. Drawing inspiration from the recent success of Titans in language tasks, we present ChangeTitans, the Titans-based framework for remote sensing change detection. Specifically, we propose VTitans, the first Titans-based vision backbone that integrates neural memory with segmented local attention, thereby capturing long-range dependencies while mitigating computational overhead. Next, we present a hierarchical VTitans-Adapter to refine multi-scale features across different network layers. Finally, we introduce TS-CBAM, a two-stream fusion module leveraging cross-temporal attention to suppress pseudo-changes and enhance detection accuracy. Experimental evaluations on four benchmark datasets (LEVIR-CD, WHU-CD, LEVIR-CD+, and SYSU-CD) demonstrate that ChangeTitans achieves state-of-the-art results, attaining \textbf{84.36\%} IoU and \textbf{91.52\%} F1-score on LEVIR-CD, while remaining computationally competitive.
Taming SAM3 in the Wild: A Concept Bank for Open-Vocabulary Segmentation
Feb 06, 2026The recent introduction of \texttt{SAM3} has revolutionized Open-Vocabulary Segmentation (OVS) through \textit{promptable concept segmentation}, which grounds pixel predictions in flexible concept prompts. However, this reliance on pre-defined concepts makes the model vulnerable: when visual distributions shift (\textit{data drift}) or conditional label distributions evolve (\textit{concept drift}) in the target domain, the alignment between visual evidence and prompts breaks down. In this work, we present \textsc{ConceptBank}, a parameter-free calibration framework to restore this alignment on the fly. Instead of adhering to static prompts, we construct a dataset-specific concept bank from the target statistics. Our approach (\textit{i}) anchors target-domain evidence via class-wise visual prototypes, (\textit{ii}) mines representative supports to suppress outliers under data drift, and (\textit{iii}) fuses candidate concepts to rectify concept drift. We demonstrate that \textsc{ConceptBank} effectively adapts \texttt{SAM3} to distribution drifts, including challenging natural-scene and remote-sensing scenarios, establishing a new baseline for robustness and efficiency in OVS. Code and model are available at https://github.com/pgsmall/ConceptBank.
Relating CNN-Transformer Fusion Network for Change Detection
Jul 03, 2024



While deep learning, particularly convolutional neural networks (CNNs), has revolutionized remote sensing (RS) change detection (CD), existing approaches often miss crucial features due to neglecting global context and incomplete change learning. Additionally, transformer networks struggle with low-level details. RCTNet addresses these limitations by introducing \textbf{(1)} an early fusion backbone to exploit both spatial and temporal features early on, \textbf{(2)} a Cross-Stage Aggregation (CSA) module for enhanced temporal representation, \textbf{(3)} a Multi-Scale Feature Fusion (MSF) module for enriched feature extraction in the decoder, and \textbf{(4)} an Efficient Self-deciphering Attention (ESA) module utilizing transformers to capture global information and fine-grained details for accurate change detection. Extensive experiments demonstrate RCTNet's clear superiority over traditional RS image CD methods, showing significant improvement and an optimal balance between accuracy and computational cost.
Knowledge Transfer with Simulated Inter-Image Erasing for Weakly Supervised Semantic Segmentation
Jul 03, 2024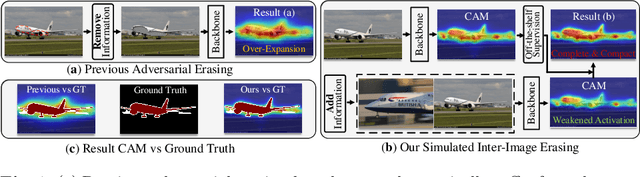
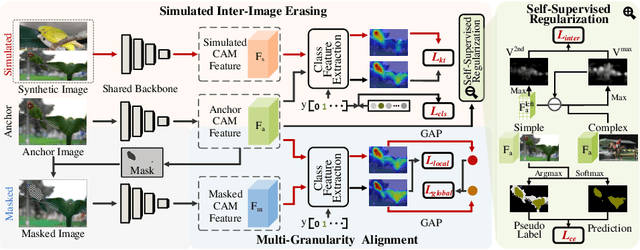
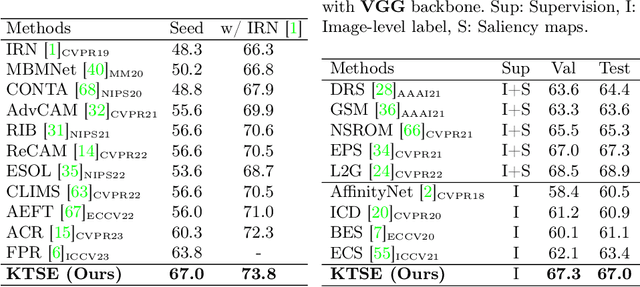
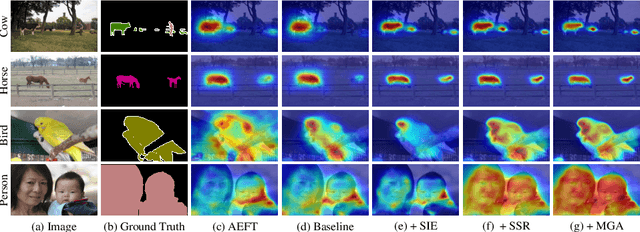
Though adversarial erasing has prevailed in weakly supervised semantic segmentation to help activate integral object regions, existing approaches still suffer from the dilemma of under-activation and over-expansion due to the difficulty in determining when to stop erasing. In this paper, we propose a \textbf{K}nowledge \textbf{T}ransfer with \textbf{S}imulated Inter-Image \textbf{E}rasing (KTSE) approach for weakly supervised semantic segmentation to alleviate the above problem. In contrast to existing erasing-based methods that remove the discriminative part for more object discovery, we propose a simulated inter-image erasing scenario to weaken the original activation by introducing extra object information. Then, object knowledge is transferred from the anchor image to the consequent less activated localization map to strengthen network localization ability. Considering the adopted bidirectional alignment will also weaken the anchor image activation if appropriate constraints are missing, we propose a self-supervised regularization module to maintain the reliable activation in discriminative regions and improve the inter-class object boundary recognition for complex images with multiple categories of objects. In addition, we resort to intra-image erasing and propose a multi-granularity alignment module to gently enlarge the object activation to boost the object knowledge transfer. Extensive experiments and ablation studies on PASCAL VOC 2012 and COCO datasets demonstrate the superiority of our proposed approach. Source codes and models are available at https://github.com/NUST-Machine-Intelligence-Laboratory/KTSE.