 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Feature Alignment Network for Unsupervised Video Object Segmentation
Jul 19, 2022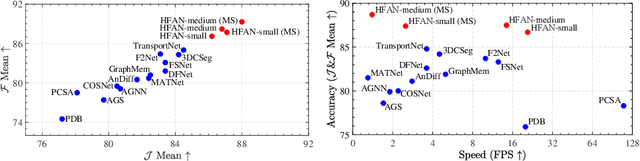

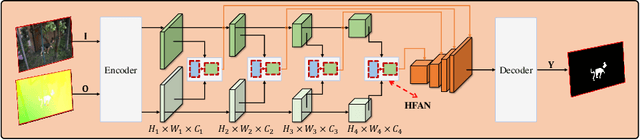
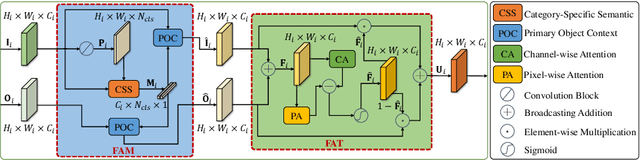
Optical flow is an easily conceived and precious cue for advancing unsupervised video object segmentation (UVOS). Most of the previous methods directly extract and fuse the motion and appearance features for segmenting target objects in the UVOS setting. However, optical flow is intrinsically an instantaneous velocity of all pixels among consecutive frames, thus making the motion features not aligned well with the primary objects among the corresponding frames. To solve the above challenge, we propose a concise, practical, and efficient architecture for appearance and motion feature alignment, dubbed hierarchical feature alignment network (HFAN). Specifically, the key merits in HFAN are the sequential Feature AlignMent (FAM) module and the Feature AdaptaTion (FAT) module, which are leveraged for processing the appearance and motion features hierarchically. FAM is capable of aligning both appearance and motion features with the primary object semantic representations, respectively. Further, FAT is explicitly designed for the adaptive fusion of appearance and motion features to achieve a desirable trade-off between cross-modal features. Extensive experiments demonstrate the effectiveness of the proposed HFAN, which reaches a new state-of-the-art performance on DAVIS-16, achieving 88.7 $\mathcal{J}\&\mathcal{F}$ Mean, i.e., a relative improvement of 3.5% over the best published result.
Rapid Person Re-Identification via Sub-space Consistency Regularization
Jul 13, 2022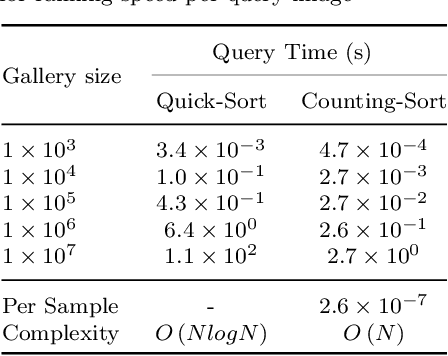
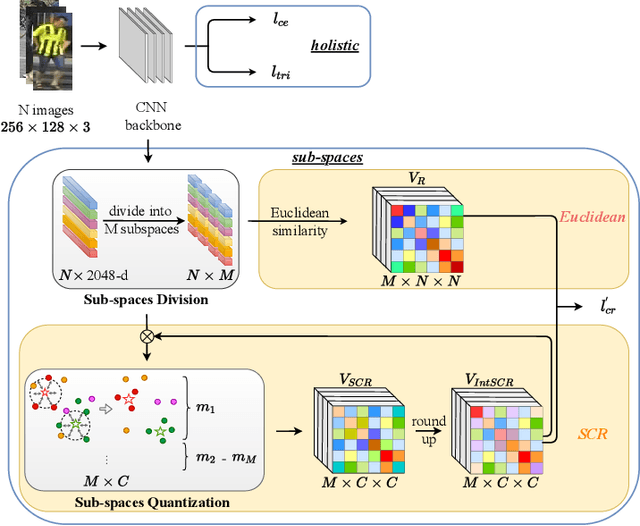
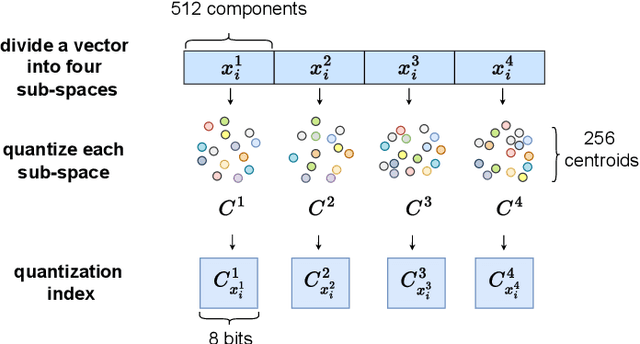
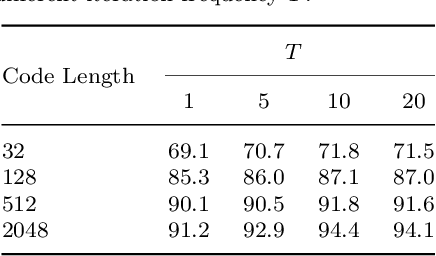
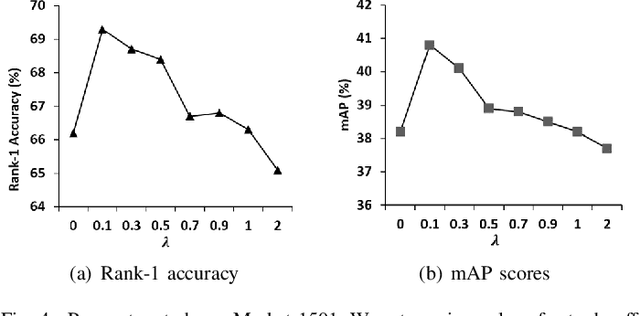
Person Re-Identification (ReID) matches pedestrians across disjoint cameras. Existing ReID methods adopting real-value feature descriptors have achieved high accuracy, but they are low in efficiency due to the slow Euclidean distance computation as well as complex quick-sort algorithms. Recently, some works propose to yield binary encoded person descriptors which instead only require fast Hamming distance computation and simple counting-sort algorithms. However, the performances of such binary encoded descriptors, especially with short code (e.g., 32 and 64 bits), are hardly satisfactory given the sparse binary space. To strike a balance between the model accuracy and efficiency, we propose a novel Sub-space Consistency Regularization (SCR) algorithm that can speed up the ReID procedure by $0.25$ times than real-value features under the same dimensions whilst maintaining a competitive accuracy, especially under short codes. SCR transforms real-value features vector (e.g., 2048 float32) with short binary codes (e.g., 64 bits) by first dividing real-value features vector into $M$ sub-spaces, each with $C$ clustered centroids. Thus the distance between two samples can be expressed as the summation of the respective distance to the centroids, which can be sped up by offline calculation and maintained via a look-up table. On the other side, these real-value centroids help to achieve significantly higher accuracy than using binary code. Lastly, we convert the distance look-up table to be integer and apply the counting-sort algorithm to speed up the ranking stage. We also propose a novel consistency regularization with an iterative framework. Experimental results on Market-1501 and DukeMTMC-reID show promising and exciting results. Under short code, our proposed SCR enjoys Real-value-level accuracy and Hashing-level speed.
Non-Salient Region Object Mining for Weakly Supervised Semantic Segmentation
Mar 26, 2021



Semantic segmentation aims to classify every pixel of an input image. Considering the difficulty of acquiring dense labels, researchers have recently been resorting to weak labels to alleviate the annotation burden of segmentation. However, existing works mainly concentrate on expanding the seed of pseudo labels within the image's salient region. In this work, we propose a non-salient region object mining approach for weakly supervised semantic segmentation. We introduce a graph-based global reasoning unit to strengthen the classification network's ability to capture global relations among disjoint and distant regions. This helps the network activate the object features outside the salient area. To further mine the non-salient region objects, we propose to exert the segmentation network's self-correction ability. Specifically, a potential object mining module is proposed to reduce the false-negative rate in pseudo labels. Moreover, we propose a non-salient region masking module for complex images to generate masked pseudo labels. Our non-salient region masking module helps further discover the objects in the non-salient region. Extensive experiments on the PASCAL VOC dataset demonstrate state-of-the-art results compared to current methods.
Jo-SRC: A Contrastive Approach for Combating Noisy Labels
Mar 24, 2021
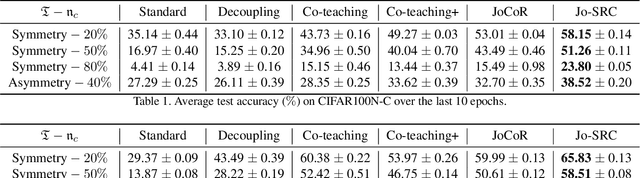
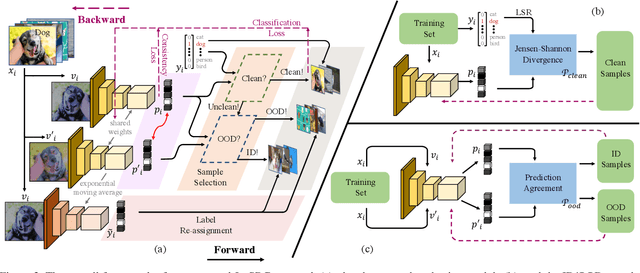
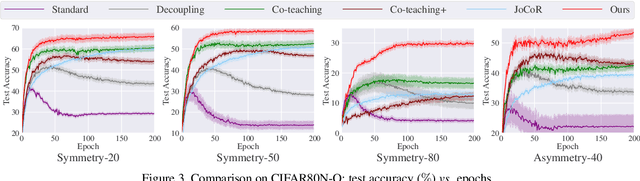
Due to the memorization effect in Deep Neural Networks (DNNs), training with noisy labels usually results in inferior model performance. Existing state-of-the-art methods primarily adopt a sample selection strategy, which selects small-loss samples for subsequent training. However, prior literature tends to perform sample selection within each mini-batch, neglecting the imbalance of noise ratios in different mini-batches. Moreover, valuable knowledge within high-loss samples is wasted. To this end, we propose a noise-robust approach named Jo-SRC (Joint Sample Selection and Model Regularization based on Consistency). Specifically, we train the network in a contrastive learning manner. Predictions from two different views of each sample are used to estimate its "likelihood" of being clean or out-of-distribution. Furthermore, we propose a joint loss to advance the model generalization performance by introducing consistency regularization. Extensive experiments have validated the superiority of our approach over existing state-of-the-art methods.
Semantically Meaningful Class Prototype Learning for One-Shot Image Semantic Segmentation
Feb 22, 2021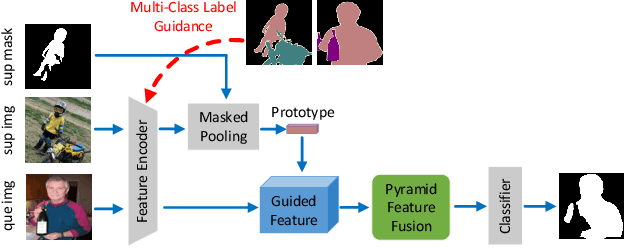
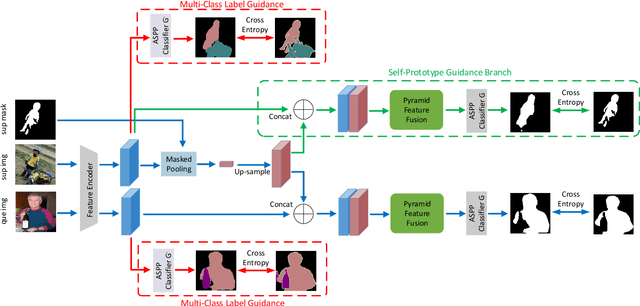
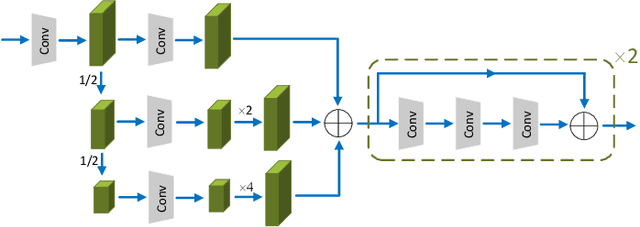
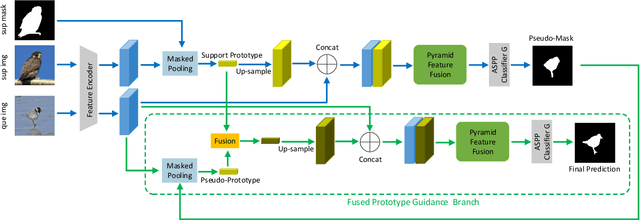
One-shot semantic image segmentation aims to segment the object regions for the novel class with only one annotated image. Recent works adopt the episodic training strategy to mimic the expected situation at testing time. However, these existing approaches simulate the test conditions too strictly during the training process, and thus cannot make full use of the given label information. Besides, these approaches mainly focus on the foreground-background target class segmentation setting. They only utilize binary mask labels for training. In this paper, we propose to leverage the multi-class label information during the episodic training. It will encourage the network to generate more semantically meaningful features for each category. After integrating the target class cues into the query features, we then propose a pyramid feature fusion module to mine the fused features for the final classifier. Furthermore, to take more advantage of the support image-mask pair, we propose a self-prototype guidance branch to support image segmentation. It can constrain the network for generating more compact features and a robust prototype for each semantic class. For inference, we propose a fused prototype guidance branch for the segmentation of the query image. Specifically, we leverage the prediction of the query image to extract the pseudo-prototype and combine it with the initial prototype. Then we utilize the fused prototype to guide the final segmentation of the query image. Extensive experiments demonstrate the superiority of our proposed approach.
Exploiting Web Images for Fine-Grained Visual Recognition by Eliminating Noisy Samples and Utilizing Hard Ones
Jan 23, 2021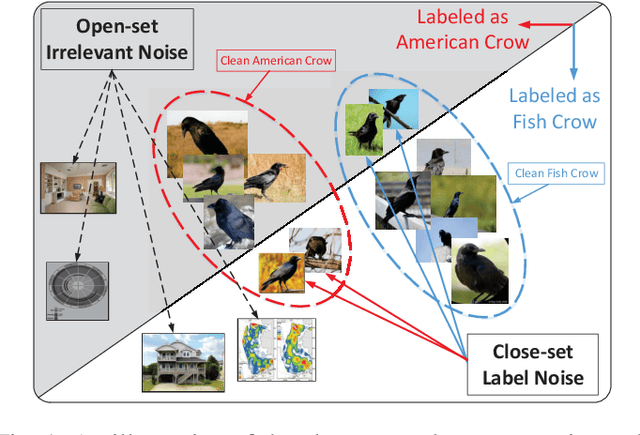



Labeling objects at a subordinate level typically requires expert knowledge, which is not always available when using random annotators. As such, learning directly from web images for fine-grained recognition has attracted broad attention. However, the presence of label noise and hard examples in web images are two obstacles for training robust fine-grained recognition models. Therefore, in this paper, we propose a novel approach for removing irrelevant samples from real-world web images during training, while employing useful hard examples to update the network. Thus, our approach can alleviate the harmful effects of irrelevant noisy web images and hard examples to achieve better performance. Extensive experiments on three commonly used fine-grained datasets demonstrate that our approach is far superior to current state-of-the-art web-supervised methods.
Data-driven Meta-set Based Fine-Grained Visual Classification
Aug 06, 2020
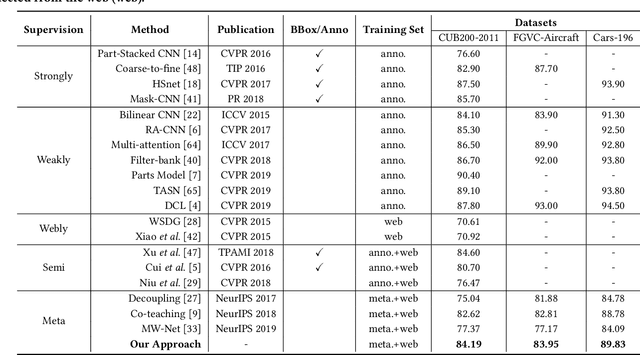
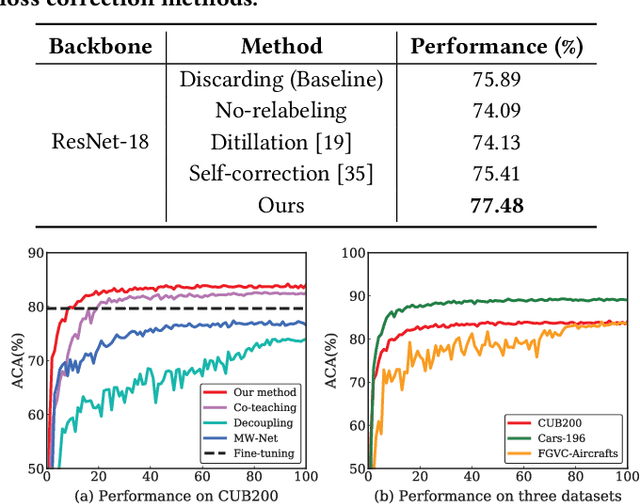
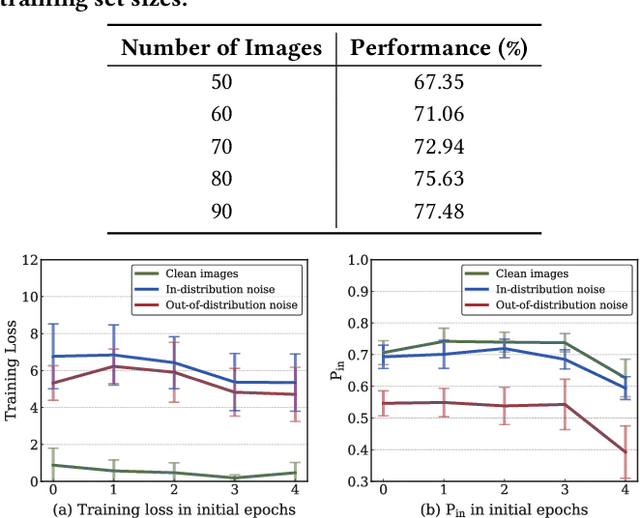
Constructing fine-grained image datasets typically requires domain-specific expert knowledge, which is not always available for crowd-sourcing platform annotators. Accordingly, learning directly from web images becomes an alternative method for fine-grained visual recognition. However, label noise in the web training set can severely degrade the model performance. To this end, we propose a data-driven meta-set based approach to deal with noisy web images for fine-grained recognition. Specifically, guided by a small amount of clean meta-set, we train a selection net in a meta-learning manner to distinguish in- and out-of-distribution noisy images. To further boost the robustness of model, we also learn a labeling net to correct the labels of in-distribution noisy data. In this way, our proposed method can alleviate the harmful effects caused by out-of-distribution noise and properly exploit the in-distribution noisy samples for training. Extensive experiments on three commonly used fine-grained datasets demonstrate that our approach is much superior to state-of-the-art noise-robust methods.
Extracting Visual Knowledge from the Internet: Making Sense of Image Data
Jun 07, 2019
Recent successes in visual recognition can be primarily attributed to feature representation, learning algorithms, and the ever-increasing size of labeled training data. Extensive research has been devoted to the first two, but much less attention has been paid to the third. Due to the high cost of manual labeling, the size of recent efforts such as ImageNet is still relatively small in respect to daily applications. In this work, we mainly focus on how to automatically generate identifying image data for a given visual concept on a vast scale. With the generated image data, we can train a robust recognition model for the given concept. We evaluate the proposed webly supervised approach on the benchmark Pascal VOC 2007 dataset and the results demonstrates the superiority of our proposed approach in image data collection.
Towards better Validity: Dispersion based Clustering for Unsupervised Person Re-identification
Jun 04, 2019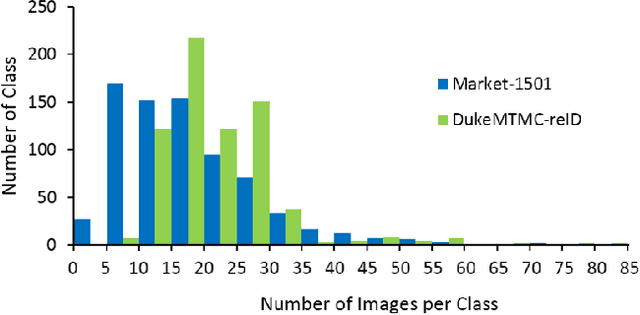
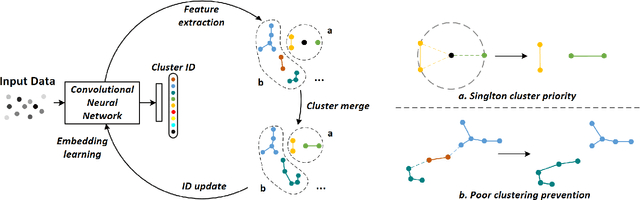

Person re-identification aims to establish the correct identity correspondences of a person moving through a non-overlapping multi-camera installation. Recent advances based on deep learning models for this task mainly focus on supervised learning scenarios where accurate annotations are assumed to be available for each setup. Annotating large scale datasets for person re-identification is demanding and burdensome, which renders the deployment of such supervised approaches to real-world applications infeasible. Therefore, it is necessary to train models without explicit supervision in an autonomous manner. In this paper, we propose an elegant and practical clustering approach for unsupervised person re-identification based on the cluster validity consideration. Concretely, we explore a fundamental concept in statistics, namely \emph{dispersion}, to achieve a robust clustering criterion. Dispersion reflects the compactness of a cluster when employed at the intra-cluster level and reveals the separation when measured at the inter-cluster level. With this insight, we design a novel Dispersion-based Clustering (DBC) approach which can discover the underlying patterns in data. This approach considers a wider context of sample-level pairwise relationships to achieve a robust cluster affinity assessment which handles the complications may arise due to prevalent imbalanced data distributions. Additionally, our solution can automatically prioritize standalone data points and prevents inferior clustering. Our extensive experimental analysis on image and video re-identification benchmarks demonstrate that our method outperforms the state-of-the-art unsupervised methods by a significant margin. Code is available at https://github.com/gddingcs/Dispersion-based-Clustering.git.
Road Segmentation with Image-LiDAR Data Fusion
May 26, 2019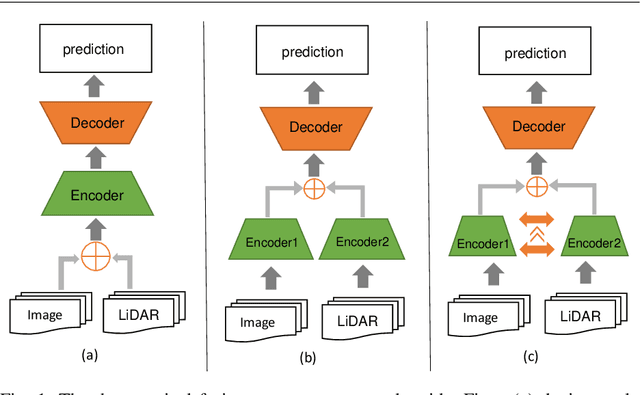
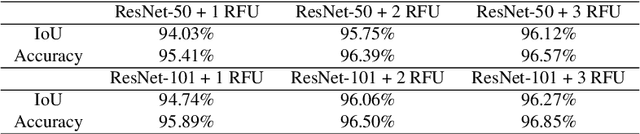
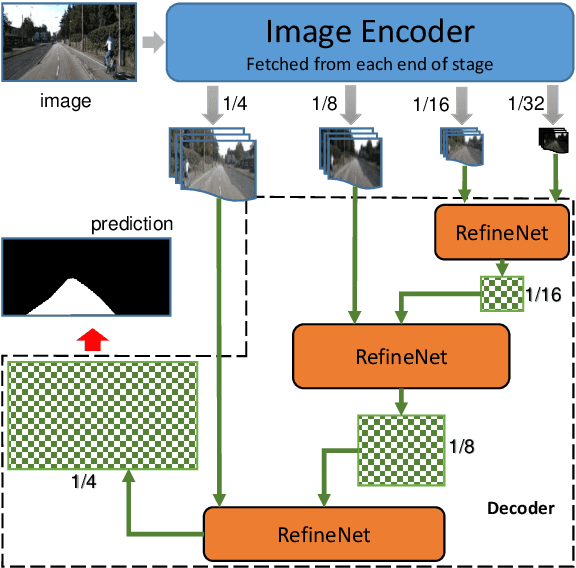
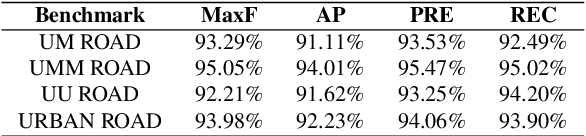
Robust road segmentation is a key challenge in self-driving research. Though many image-based methods have been studied and high performances in dataset evaluations have been reported, developing robust and reliable road segmentation is still a major challenge. Data fusion across different sensors to improve the performance of road segmentation is widely considered an important and irreplaceable solution. In this paper, we propose a novel structure to fuse image and LiDAR point cloud in an end-to-end semantic segmentation network, in which the fusion is performed at decoder stage instead of at, more commonly, encoder stage. During fusion, we improve the multi-scale LiDAR map generation to increase the precision of the multi-scale LiDAR map by introducing pyramid projection method. Additionally, we adapted the multi-path refinement network with our fusion strategy and improve the road prediction compared with transpose convolution with skip layers. Our approach has been tested on KITTI ROAD dataset and has competitive performance.