 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSDRL: Unified Skeleton-Based Dense Representation Learning with Multi-Grained Feature Decorrelation
Dec 12, 2024



Contrastive learning has achieved great success in skeleton-based representation learning recently. However, the prevailing methods are predominantly negative-based, necessitating additional momentum encoder and memory bank to get negative samples, which increases the difficulty of model training. Furthermore, these methods primarily concentrate on learning a global representation for recognition and retrieval tasks, while overlooking the rich and detailed local representations that are crucial for dense prediction tasks. To alleviate these issues, we introduce a Unified Skeleton-based Dense Representation Learning framework based on feature decorrelation, called USDRL, which employs feature decorrelation across temporal, spatial, and instance domains in a multi-grained manner to reduce redundancy among dimensions of the representations to maximize information extraction from features. Additionally, we design a Dense Spatio-Temporal Encoder (DSTE) to capture fine-grained action representations effectively, thereby enhancing the performance of dense prediction tasks. Comprehensive experiments, conducted on the benchmarks NTU-60, NTU-120, PKU-MMD I, and PKU-MMD II, across diverse downstream tasks including action recognition, action retrieval, and action detection, conclusively demonstrate that our approach significantly outperforms the current state-of-the-art (SOTA) approaches. Our code and models are available at https://github.com/wengwanjiang/USDRL.
UnitedVLN: Generalizable Gaussian Splatting for Continuous Vision-Language Navigation
Nov 25, 2024
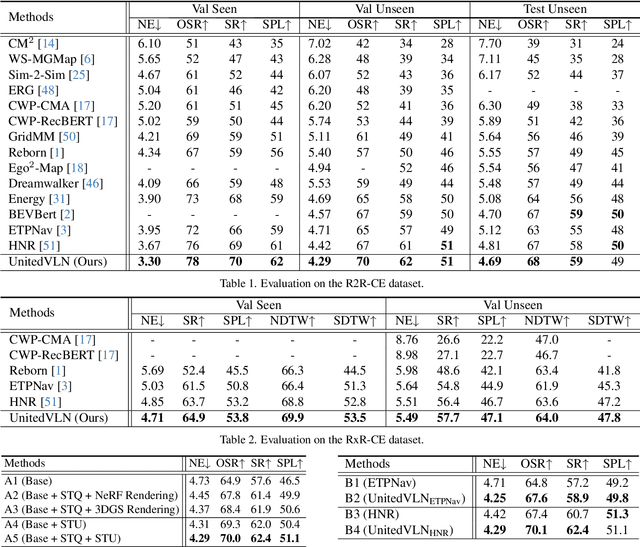
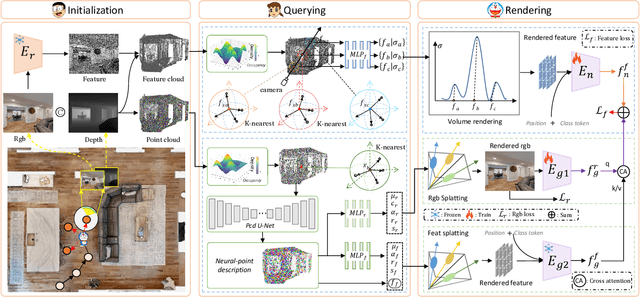
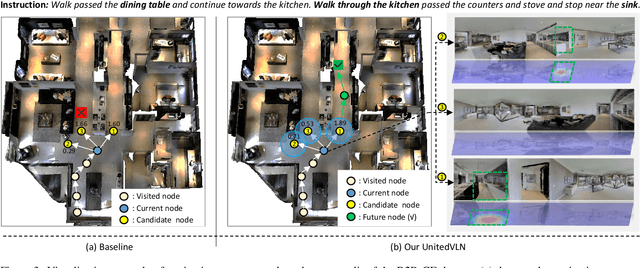
Vision-and-Language Navigation (VLN), where an agent follows instructions to reach a target destination, has recently seen significant advancements. In contrast to navigation in discrete environments with predefined trajectories, VLN in Continuous Environments (VLN-CE) presents greater challenges, as the agent is free to navigate any unobstructed location and is more vulnerable to visual occlusions or blind spots. Recent approaches have attempted to address this by imagining future environments, either through predicted future visual images or semantic features, rather than relying solely on current observations. However, these RGB-based and feature-based methods lack intuitive appearance-level information or high-level semantic complexity crucial for effective navigation. To overcome these limitations, we introduce a novel, generalizable 3DGS-based pre-training paradigm, called UnitedVLN, which enables agents to better explore future environments by unitedly rendering high-fidelity 360 visual images and semantic features. UnitedVLN employs two key schemes: search-then-query sampling and separate-then-united rendering, which facilitate efficient exploitation of neural primitives, helping to integrate both appearance and semantic information for more robust navigation. Extensive experiments demonstrate that UnitedVLN outperforms state-of-the-art methods on existing VLN-CE benchmarks.
FedMLLM: Federated Fine-tuning MLLM on Multimodal Heterogeneity Data
Nov 22, 2024



Multimodal Large Language Models (MLLMs) have made significant advancements, demonstrating powerful capabilities in processing and understanding multimodal data. Fine-tuning MLLMs with Federated Learning (FL) allows for expanding the training data scope by including private data sources, thereby enhancing their practical applicability in privacy-sensitive domains. However, current research remains in the early stage, particularly in addressing the \textbf{multimodal heterogeneities} in real-world applications. In this paper, we introduce a benchmark for evaluating various downstream tasks in the federated fine-tuning of MLLMs within multimodal heterogeneous scenarios, laying the groundwork for the research in the field. Our benchmark encompasses two datasets, five comparison baselines, and four multimodal scenarios, incorporating over ten types of modal heterogeneities. To address the challenges posed by modal heterogeneity, we develop a general FedMLLM framework that integrates four representative FL methods alongside two modality-agnostic strategies. Extensive experimental results show that our proposed FL paradigm improves the performance of MLLMs by broadening the range of training data and mitigating multimodal heterogeneity. Code is available at https://github.com/1xbq1/FedMLLM
Non-Salient Region Object Mining for Weakly Supervised Semantic Segmentation
Mar 26, 2021



Semantic segmentation aims to classify every pixel of an input image. Considering the difficulty of acquiring dense labels, researchers have recently been resorting to weak labels to alleviate the annotation burden of segmentation. However, existing works mainly concentrate on expanding the seed of pseudo labels within the image's salient region. In this work, we propose a non-salient region object mining approach for weakly supervised semantic segmentation. We introduce a graph-based global reasoning unit to strengthen the classification network's ability to capture global relations among disjoint and distant regions. This helps the network activate the object features outside the salient area. To further mine the non-salient region objects, we propose to exert the segmentation network's self-correction ability. Specifically, a potential object mining module is proposed to reduce the false-negative rate in pseudo labels. Moreover, we propose a non-salient region masking module for complex images to generate masked pseudo labels. Our non-salient region masking module helps further discover the objects in the non-salient region. Extensive experiments on the PASCAL VOC dataset demonstrate state-of-the-art results compared to current methods.
Semantically Meaningful Class Prototype Learning for One-Shot Image Semantic Segmentation
Feb 22, 2021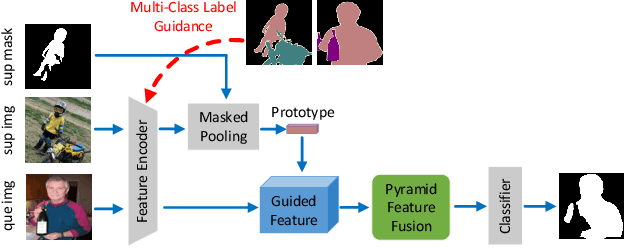
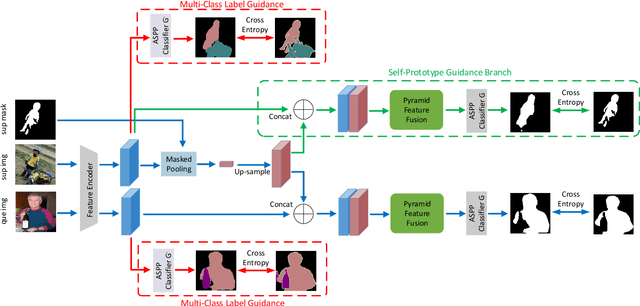
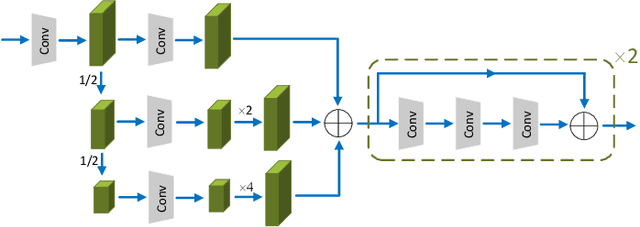
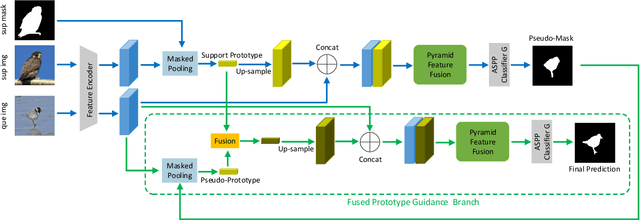
One-shot semantic image segmentation aims to segment the object regions for the novel class with only one annotated image. Recent works adopt the episodic training strategy to mimic the expected situation at testing time. However, these existing approaches simulate the test conditions too strictly during the training process, and thus cannot make full use of the given label information. Besides, these approaches mainly focus on the foreground-background target class segmentation setting. They only utilize binary mask labels for training. In this paper, we propose to leverage the multi-class label information during the episodic training. It will encourage the network to generate more semantically meaningful features for each category. After integrating the target class cues into the query features, we then propose a pyramid feature fusion module to mine the fused features for the final classifier. Furthermore, to take more advantage of the support image-mask pair, we propose a self-prototype guidance branch to support image segmentation. It can constrain the network for generating more compact features and a robust prototype for each semantic class. For inference, we propose a fused prototype guidance branch for the segmentation of the query image. Specifically, we leverage the prediction of the query image to extract the pseudo-prototype and combine it with the initial prototype. Then we utilize the fused prototype to guide the final segmentation of the query image. Extensive experiments demonstrate the superiority of our proposed approach.