 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Appearance Codes and Bilateral Grids for Driving Scene Gaussian Splatting
Jun 06, 2025Neural rendering techniques, including NeRF and Gaussian Splatting (GS), rely on photometric consistency to produce high-quality reconstructions. However, in real-world scenarios, it is challenging to guarantee perfect photometric consistency in acquired images. Appearance codes have been widely used to address this issue, but their modeling capability is limited, as a single code is applied to the entire image. Recently, the bilateral grid was introduced to perform pixel-wise color mapping, but it is difficult to optimize and constrain effectively. In this paper, we propose a novel multi-scale bilateral grid that unifies appearance codes and bilateral grids. We demonstrate that this approach significantly improves geometric accuracy in dynamic, decoupled autonomous driving scene reconstruction, outperforming both appearance codes and bilateral grids. This is crucial for autonomous driving, where accurate geometry is important for obstacle avoidance and control. Our method shows strong results across four datasets: Waymo, NuScenes, Argoverse, and PandaSet. We further demonstrate that the improvement in geometry is driven by the multi-scale bilateral grid, which effectively reduces floaters caused by photometric inconsistency.
PUGS: Zero-shot Physical Understanding with Gaussian Splatting
Feb 17, 2025
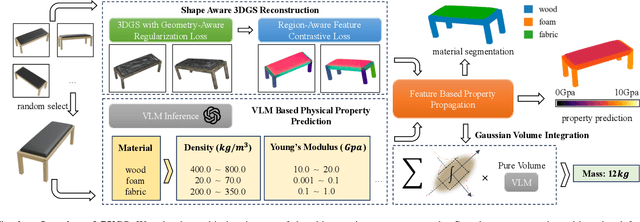


Current robotic systems can understand the categories and poses of objects well. But understanding physical properties like mass, friction, and hardness, in the wild, remains challenging. We propose a new method that reconstructs 3D objects using the Gaussian splatting representation and predicts various physical properties in a zero-shot manner. We propose two techniques during the reconstruction phase: a geometry-aware regularization loss function to improve the shape quality and a region-aware feature contrastive loss function to promote region affinity. Two other new techniques are designed during inference: a feature-based property propagation module and a volume integration module tailored for the Gaussian representation. Our framework is named as zero-shot physical understanding with Gaussian splatting, or PUGS. PUGS achieves new state-of-the-art results on the standard benchmark of ABO-500 mass prediction. We provide extensive quantitative ablations and qualitative visualization to demonstrate the mechanism of our designs. We show the proposed methodology can help address challenging real-world grasping tasks. Our codes, data, and models are available at https://github.com/EverNorif/PUGS
UnitedVLN: Generalizable Gaussian Splatting for Continuous Vision-Language Navigation
Nov 25, 2024
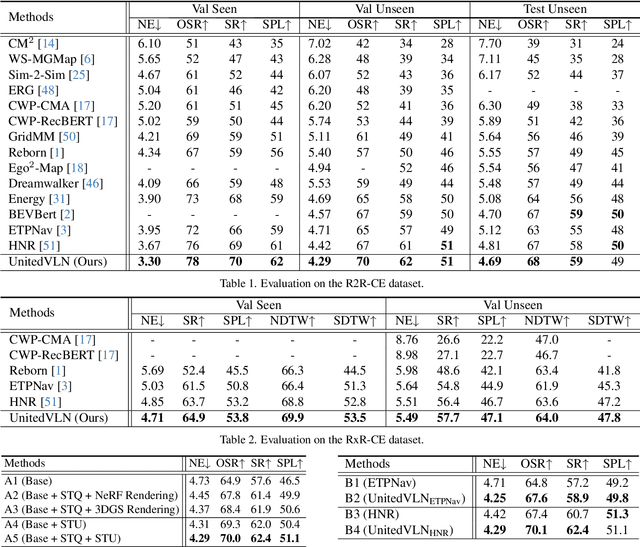
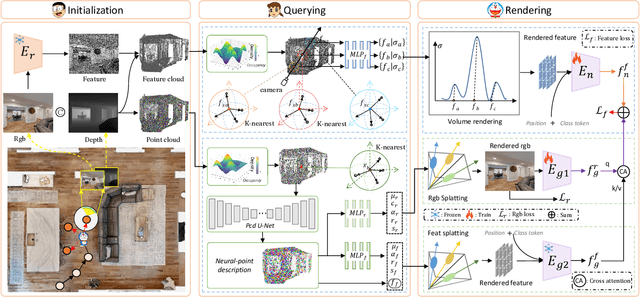
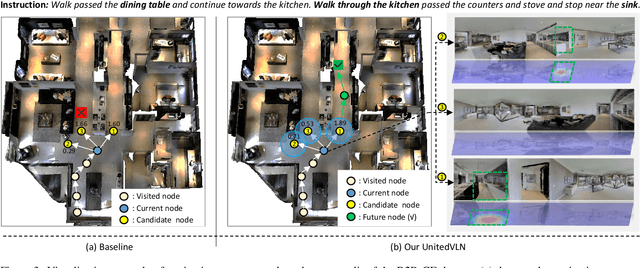
Vision-and-Language Navigation (VLN), where an agent follows instructions to reach a target destination, has recently seen significant advancements. In contrast to navigation in discrete environments with predefined trajectories, VLN in Continuous Environments (VLN-CE) presents greater challenges, as the agent is free to navigate any unobstructed location and is more vulnerable to visual occlusions or blind spots. Recent approaches have attempted to address this by imagining future environments, either through predicted future visual images or semantic features, rather than relying solely on current observations. However, these RGB-based and feature-based methods lack intuitive appearance-level information or high-level semantic complexity crucial for effective navigation. To overcome these limitations, we introduce a novel, generalizable 3DGS-based pre-training paradigm, called UnitedVLN, which enables agents to better explore future environments by unitedly rendering high-fidelity 360 visual images and semantic features. UnitedVLN employs two key schemes: search-then-query sampling and separate-then-united rendering, which facilitate efficient exploitation of neural primitives, helping to integrate both appearance and semantic information for more robust navigation. Extensive experiments demonstrate that UnitedVLN outperforms state-of-the-art methods on existing VLN-CE benchmarks.
Drone-assisted Road Gaussian Splatting with Cross-view Uncertainty
Aug 27, 2024
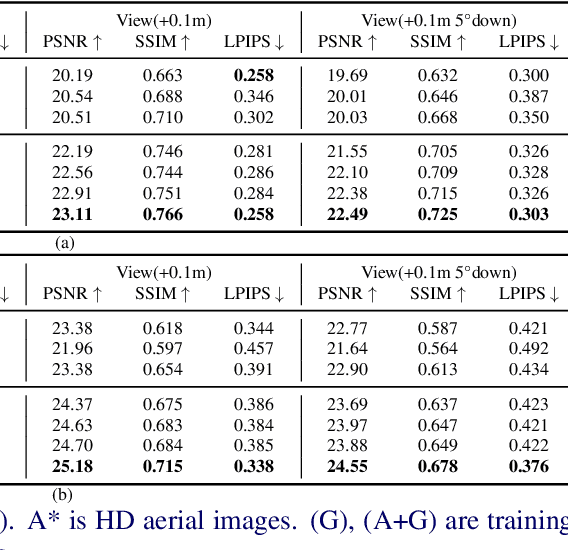
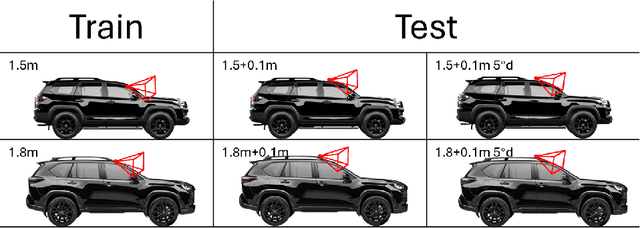
Robust and realistic rendering for large-scale road scenes is essential in autonomous driving simulation. Recently, 3D Gaussian Splatting (3D-GS) has made groundbreaking progress in neural rendering, but the general fidelity of large-scale road scene renderings is often limited by the input imagery, which usually has a narrow field of view and focuses mainly on the street-level local area. Intuitively, the data from the drone's perspective can provide a complementary viewpoint for the data from the ground vehicle's perspective, enhancing the completeness of scene reconstruction and rendering. However, training naively with aerial and ground images, which exhibit large view disparity, poses a significant convergence challenge for 3D-GS, and does not demonstrate remarkable improvements in performance on road views. In order to enhance the novel view synthesis of road views and to effectively use the aerial information, we design an uncertainty-aware training method that allows aerial images to assist in the synthesis of areas where ground images have poor learning outcomes instead of weighting all pixels equally in 3D-GS training like prior work did. We are the first to introduce the cross-view uncertainty to 3D-GS by matching the car-view ensemble-based rendering uncertainty to aerial images, weighting the contribution of each pixel to the training process. Additionally, to systematically quantify evaluation metrics, we assemble a high-quality synthesized dataset comprising both aerial and ground images for road scenes.
GaussReg: Fast 3D Registration with Gaussian Splatting
Jul 07, 2024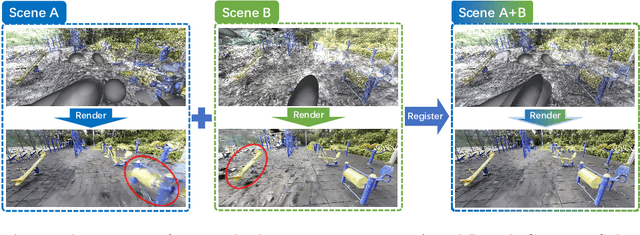
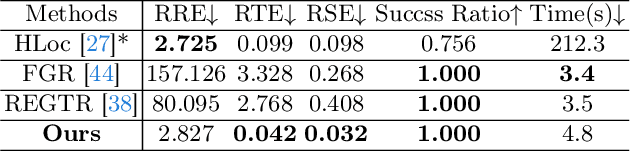
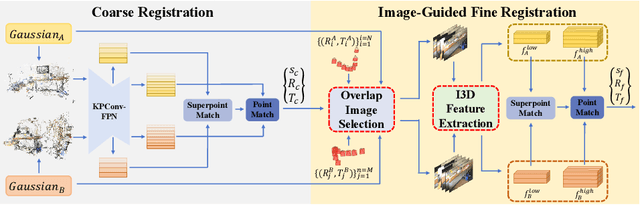
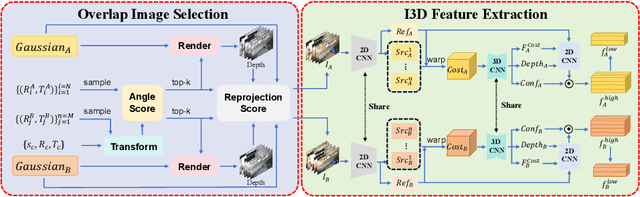
Point cloud registration is a fundamental problem for large-scale 3D scene scanning and reconstruction. With the help of deep learning, registration methods have evolved significantly, reaching a nearly-mature stage. As the introduction of Neural Radiance Fields (NeRF), it has become the most popular 3D scene representation as its powerful view synthesis capabilities. Regarding NeRF representation, its registration is also required for large-scale scene reconstruction. However, this topic extremly lacks exploration. This is due to the inherent challenge to model the geometric relationship among two scenes with implicit representations. The existing methods usually convert the implicit representation to explicit representation for further registration. Most recently, Gaussian Splatting (GS) is introduced, employing explicit 3D Gaussian. This method significantly enhances rendering speed while maintaining high rendering quality. Given two scenes with explicit GS representations, in this work, we explore the 3D registration task between them. To this end, we propose GaussReg, a novel coarse-to-fine framework, both fast and accurate. The coarse stage follows existing point cloud registration methods and estimates a rough alignment for point clouds from GS. We further newly present an image-guided fine registration approach, which renders images from GS to provide more detailed geometric information for precise alignment. To support comprehensive evaluation, we carefully build a scene-level dataset called ScanNet-GSReg with 1379 scenes obtained from the ScanNet dataset and collect an in-the-wild dataset called GSReg. Experimental results demonstrate our method achieves state-of-the-art performance on multiple datasets. Our GaussReg is 44 times faster than HLoc (SuperPoint as the feature extractor and SuperGlue as the matcher) with comparable accuracy.
Camera Relocalization in Shadow-free Neural Radiance Fields
May 23, 2024



Camera relocalization is a crucial problem in computer vision and robotics. Recent advancements in neural radiance fields (NeRFs) have shown promise in synthesizing photo-realistic images. Several works have utilized NeRFs for refining camera poses, but they do not account for lighting changes that can affect scene appearance and shadow regions, causing a degraded pose optimization process. In this paper, we propose a two-staged pipeline that normalizes images with varying lighting and shadow conditions to improve camera relocalization. We implement our scene representation upon a hash-encoded NeRF which significantly boosts up the pose optimization process. To account for the noisy image gradient computing problem in grid-based NeRFs, we further propose a re-devised truncated dynamic low-pass filter (TDLF) and a numerical gradient averaging technique to smoothen the process. Experimental results on several datasets with varying lighting conditions demonstrate that our method achieves state-of-the-art results in camera relocalization under varying lighting conditions. Code and data will be made publicly available.
Blending Distributed NeRFs with Tri-stage Robust Pose Optimization
May 05, 2024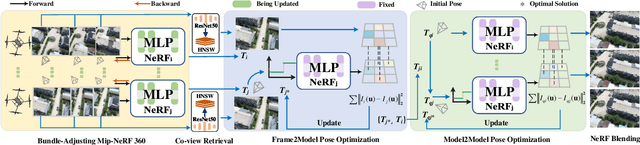
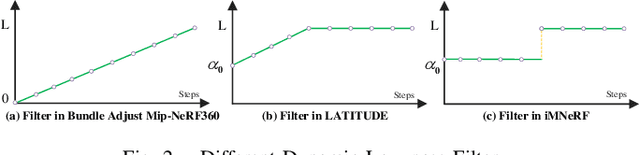

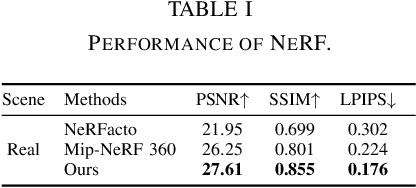
Due to the limited model capacity, leveraging distributed Neural Radiance Fields (NeRFs) for modeling extensive urban environments has become a necessity. However, current distributed NeRF registration approaches encounter aliasing artifacts, arising from discrepancies in rendering resolutions and suboptimal pose precision. These factors collectively deteriorate the fidelity of pose estimation within NeRF frameworks, resulting in occlusion artifacts during the NeRF blending stage. In this paper, we present a distributed NeRF system with tri-stage pose optimization. In the first stage, precise poses of images are achieved by bundle adjusting Mip-NeRF 360 with a coarse-to-fine strategy. In the second stage, we incorporate the inverting Mip-NeRF 360, coupled with the truncated dynamic low-pass filter, to enable the achievement of robust and precise poses, termed Frame2Model optimization. On top of this, we obtain a coarse transformation between NeRFs in different coordinate systems. In the third stage, we fine-tune the transformation between NeRFs by Model2Model pose optimization. After obtaining precise transformation parameters, we proceed to implement NeRF blending, showcasing superior performance metrics in both real-world and simulation scenarios. Codes and data will be publicly available at https://github.com/boilcy/Distributed-NeRF.
Spectrally Pruned Gaussian Fields with Neural Compensation
May 01, 2024Recently, 3D Gaussian Splatting, as a novel 3D representation, has garnered attention for its fast rendering speed and high rendering quality. However, this comes with high memory consumption, e.g., a well-trained Gaussian field may utilize three million Gaussian primitives and over 700 MB of memory. We credit this high memory footprint to the lack of consideration for the relationship between primitives. In this paper, we propose a memory-efficient Gaussian field named SUNDAE with spectral pruning and neural compensation. On one hand, we construct a graph on the set of Gaussian primitives to model their relationship and design a spectral down-sampling module to prune out primitives while preserving desired signals. On the other hand, to compensate for the quality loss of pruning Gaussians, we exploit a lightweight neural network head to mix splatted features, which effectively compensates for quality losses while capturing the relationship between primitives in its weights. We demonstrate the performance of SUNDAE with extensive results. For example, SUNDAE can achieve 26.80 PSNR at 145 FPS using 104 MB memory while the vanilla Gaussian splatting algorithm achieves 25.60 PSNR at 160 FPS using 523 MB memory, on the Mip-NeRF360 dataset. Codes are publicly available at https://runyiyang.github.io/projects/SUNDAE/.
GauStudio: A Modular Framework for 3D Gaussian Splatting and Beyond
Mar 28, 2024We present GauStudio, a novel modular framework for modeling 3D Gaussian Splatting (3DGS) to provide standardized, plug-and-play components for users to easily customize and implement a 3DGS pipeline. Supported by our framework, we propose a hybrid Gaussian representation with foreground and skyball background models. Experiments demonstrate this representation reduces artifacts in unbounded outdoor scenes and improves novel view synthesis. Finally, we propose Gaussian Splatting Surface Reconstruction (GauS), a novel render-then-fuse approach for high-fidelity mesh reconstruction from 3DGS inputs without fine-tuning. Overall, our GauStudio framework, hybrid representation, and GauS approach enhance 3DGS modeling and rendering capabilities, enabling higher-quality novel view synthesis and surface reconstruction.
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving
Jul 27, 2023Nowadays, autonomous cars can drive smoothly in ordinary cases, and it is widely recognized that realistic sensor simulation will play a critical role in solving remaining corner cases by simulating them. To this end, we propose an autonomous driving simulator based upon neural radiance fields (NeRFs). Compared with existing works, ours has three notable features: (1) Instance-aware. Our simulator models the foreground instances and background environments separately with independent networks so that the static (e.g., size and appearance) and dynamic (e.g., trajectory) properties of instances can be controlled separately. (2) Modular. Our simulator allows flexible switching between different modern NeRF-related backbones, sampling strategies, input modalities, etc. We expect this modular design to boost academic progress and industrial deployment of NeRF-based autonomous driving simulation. (3) Realistic. Our simulator set new state-of-the-art photo-realism results given the best module selection. Our simulator will be open-sourced while most of our counterparts are not. Project page: https://open-air-sun.github.io/mars/.