 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamOn: Diffusion Language Models For Code Infilling Beyond Fixed-size Canvas
Feb 01, 2026Diffusion Language Models (DLMs) present a compelling alternative to autoregressive models, offering flexible, any-order infilling without specialized prompting design. However, their practical utility is blocked by a critical limitation: the requirement of a fixed-length masked sequence for generation. This constraint severely degrades code infilling performance when the predefined mask size mismatches the ideal completion length. To address this, we propose DreamOn, a novel diffusion framework that enables dynamic, variable-length generation. DreamOn augments the diffusion process with two length control states, allowing the model to autonomously expand or contract the output length based solely on its own predictions. We integrate this mechanism into existing DLMs with minimal modifications to the training objective and no architectural changes. Built upon Dream-Coder-7B and DiffuCoder-7B, DreamOn achieves infilling performance on par with state-of-the-art autoregressive models on HumanEval-Infilling and SantaCoder-FIM and matches oracle performance achieved with ground-truth length. Our work removes a fundamental barrier to the practical deployment of DLMs, significantly advancing their flexibility and applicability for variable-length generation. Our code is available at https://github.com/DreamLM/DreamOn.
From Rays to Projections: Better Inputs for Feed-Forward View Synthesis
Jan 08, 2026Feed-forward view synthesis models predict a novel view in a single pass with minimal 3D inductive bias. Existing works encode cameras as Plücker ray maps, which tie predictions to the arbitrary world coordinate gauge and make them sensitive to small camera transformations, thereby undermining geometric consistency. In this paper, we ask what inputs best condition a model for robust and consistent view synthesis. We propose projective conditioning, which replaces raw camera parameters with a target-view projective cue that provides a stable 2D input. This reframes the task from a brittle geometric regression problem in ray space to a well-conditioned target-view image-to-image translation problem. Additionally, we introduce a masked autoencoding pretraining strategy tailored to this cue, enabling the use of large-scale uncalibrated data for pretraining. Our method shows improved fidelity and stronger cross-view consistency compared to ray-conditioned baselines on our view-consistency benchmark. It also achieves state-of-the-art quality on standard novel view synthesis benchmarks.
Accelerating Diffusion LLM Inference via Local Determinism Propagation
Oct 08, 2025Diffusion large language models (dLLMs) represent a significant advancement in text generation, offering parallel token decoding capabilities. However, existing open-source implementations suffer from quality-speed trade-offs that impede their practical deployment. Conservative sampling strategies typically decode only the most confident token per step to ensure quality (i.e., greedy decoding), at the cost of inference efficiency due to repeated redundant refinement iterations--a phenomenon we term delayed decoding. Through systematic analysis of dLLM decoding dynamics, we characterize this delayed decoding behavior and propose a training-free adaptive parallel decoding strategy, named LocalLeap, to address these inefficiencies. LocalLeap is built on two fundamental empirical principles: local determinism propagation centered on high-confidence anchors and progressive spatial consistency decay. By applying these principles, LocalLeap identifies anchors and performs localized relaxed parallel decoding within bounded neighborhoods, achieving substantial inference step reduction through early commitment of already-determined tokens without compromising output quality. Comprehensive evaluation on various benchmarks demonstrates that LocalLeap achieves 6.94$\times$ throughput improvements and reduces decoding steps to just 14.2\% of the original requirement, achieving these gains with negligible performance impact. The source codes are available at: https://github.com/friedrichor/LocalLeap.
RefTool: Enhancing Model Reasoning with Reference-Guided Tool Creation
May 27, 2025Tools enhance the reasoning capabilities of large language models (LLMs) in complex problem-solving tasks, but not all tasks have available tools. In the absence of predefined tools, prior works have explored instructing LLMs to generate tools on their own. However, such approaches rely heavily on the models' internal knowledge and would fail in domains beyond the LLMs' knowledge scope. To address this limitation, we propose RefTool, a reference-guided framework for automatic tool creation that leverages structured external materials such as textbooks. RefTool consists of two modules: (1) tool creation, where LLMs generate executable tools from reference content, validate them using illustrative examples, and organize them hierarchically into a toolbox; and (2) tool utilization, where LLMs navigate the toolbox structure to select and apply the appropriate tools to solve problems. Experiments on causality, physics, and chemistry benchmarks demonstrate that RefTool outperforms existing tool-creation and domain-specific reasoning methods by 11.3% on average accuracy, while being cost-efficient and broadly generalizable. Analyses reveal that grounding tool creation in references produces accurate and faithful tools, and that the hierarchical structure facilitates effective tool selection. RefTool enables LLMs to overcome knowledge limitations, demonstrating the value of grounding tool creation in external references for enhanced and generalizable reasoning.
3D Gaussian Inverse Rendering with Approximated Global Illumination
Apr 02, 20253D Gaussian Splatting shows great potential in reconstructing photo-realistic 3D scenes. However, these methods typically bake illumination into their representations, limiting their use for physically-based rendering and scene editing. Although recent inverse rendering approaches aim to decompose scenes into material and lighting components, they often rely on simplifying assumptions that fail when editing. We present a novel approach that enables efficient global illumination for 3D Gaussians Splatting through screen-space ray tracing. Our key insight is that a substantial amount of indirect light can be traced back to surfaces visible within the current view frustum. Leveraging this observation, we augment the direct shading computed by 3D Gaussians with Monte-Carlo screen-space ray-tracing to capture one-bounce indirect illumination. In this way, our method enables realistic global illumination without sacrificing the computational efficiency and editability benefits of 3D Gaussians. Through experiments, we show that the screen-space approximation we utilize allows for indirect illumination and supports real-time rendering and editing. Code, data, and models will be made available at our project page: https://wuzirui.github.io/gs-ssr.
Haste Makes Waste: Evaluating Planning Abilities of LLMs for Efficient and Feasible Multitasking with Time Constraints Between Actions
Mar 04, 2025While Large Language Model-based agents have demonstrated substantial progress in task completion, existing evaluation benchmarks tend to overemphasize single-task performance, with insufficient attention given to the crucial aspects of multitask planning and execution efficiency required in real-world scenarios. To bridge this gap, we present Recipe2Plan, a novel benchmark framework based on real-world cooking scenarios. Unlike conventional benchmarks, Recipe2Plan challenges agents to optimize cooking time through parallel task execution while respecting temporal constraints i.e. specific actions need to be performed within a particular time intervals following the preceding steps. Overly aggressive local parallelization may disrupt this constraint, potentially compromising the entire cooking process. This strict time constraint between actions raises a unique challenge for agents to balance between maximizing concurrent operations and adhering to critical timing constraints. Extensive experiments with state-of-the-art models reveal challenges in maintaining this balance between efficiency and feasibility. The results highlight the need for improved temporal awareness and global multitasking capabilities in large language models. We open-source our benchmark and code at https://github.com/WilliamZR/Recipe2Plan.
Automated Annotation of Evolving Corpora for Augmenting Longitudinal Network Data: A Framework Integrating Large Language Models and Expert Knowledge
Mar 03, 2025Longitudinal network data are essential for analyzing political, economic, and social systems and processes. In political science, these datasets are often generated through human annotation or supervised machine learning applied to evolving corpora. However, as semantic contexts shift over time, inferring dynamic interaction types on emerging issues among a diverse set of entities poses significant challenges, particularly in maintaining timely and consistent annotations. This paper presents the Expert-Augmented LLM Annotation (EALA) approach, which leverages Large Language Models (LLMs) in combination with historically annotated data and expert-constructed codebooks to extrapolate and extend datasets into future periods. We evaluate the performance and reliability of EALA using a dataset of climate negotiations. Our findings demonstrate that EALA effectively predicts nuanced interactions between negotiation parties and captures the evolution of topics over time. At the same time, we identify several limitations inherent to LLM-based annotation, highlighting areas for further improvement. Given the wide availability of codebooks and annotated datasets, EALA holds substantial promise for advancing research in political science and beyond.
ProTrix: Building Models for Planning and Reasoning over Tables with Sentence Context
Mar 04, 2024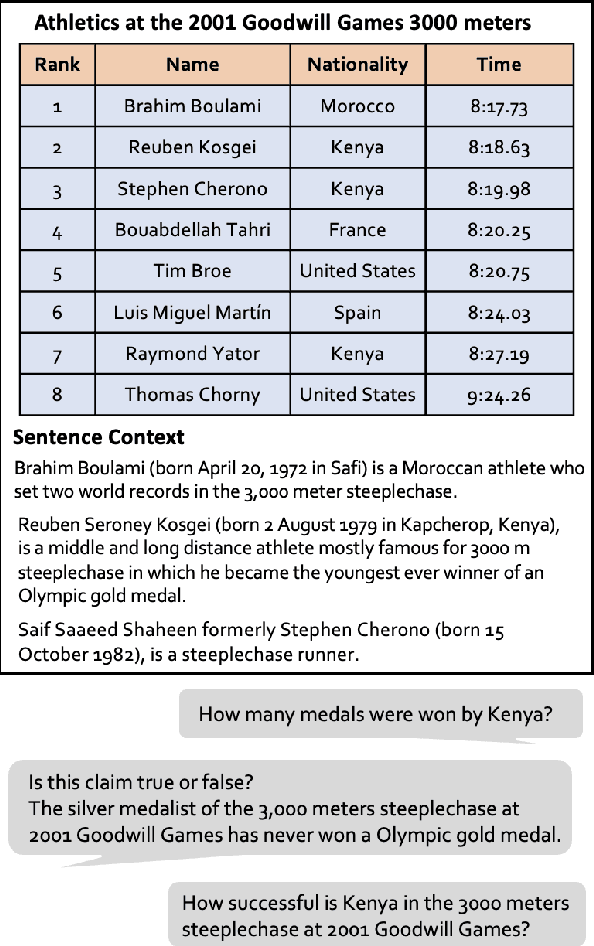
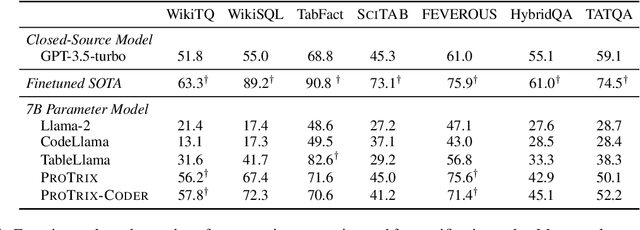
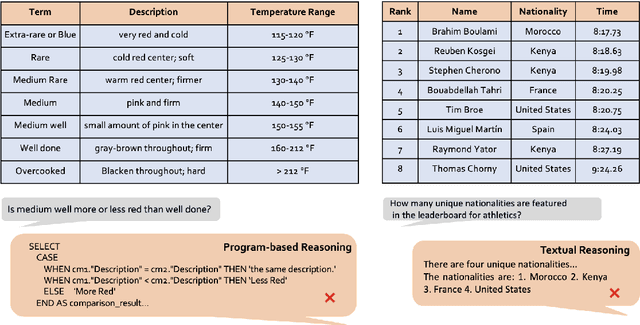
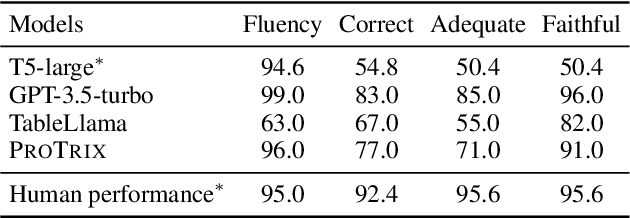
Tables play a crucial role in conveying information in various domains, serving as indispensable tools for organizing and presenting data in a structured manner. We propose a Plan-then-Reason framework to answer different types of user queries over tables with sentence context. The framework first plans the reasoning paths over the context, then assigns each step to program-based or textual reasoning to reach the final answer. We construct an instruction tuning set TrixInstruct following the framework. Our dataset cover queries that are program-unsolvable or need combining information from tables and sentences to obtain planning and reasoning abilities. We present ProTrix by finetuning Llama-2-7B on TrixInstruct. Our experiments show that ProTrix generalizes to diverse tabular tasks and achieves comparable performance to GPT-3.5-turbo. We further demonstrate that ProTrix can generate accurate and faithful explanations to answer complex free-form questions. Our work underscores the importance of the planning and reasoning abilities towards a model over tabular tasks with generalizability and interpretability. We will release our dataset and model at https://github.com/WilliamZR/ProTrix.
Are LLMs Capable of Data-based Statistical and Causal Reasoning? Benchmarking Advanced Quantitative Reasoning with Data
Feb 27, 2024


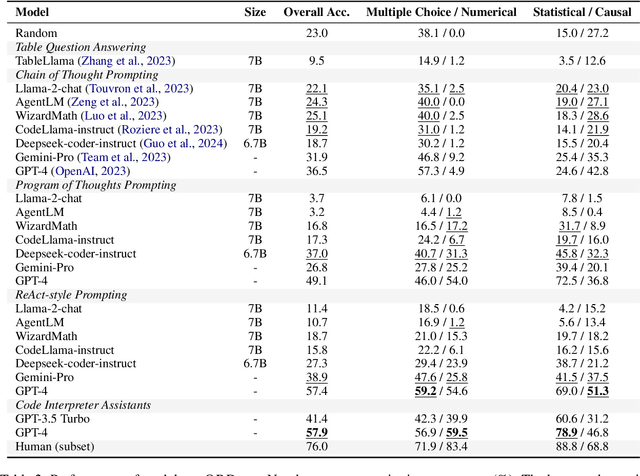
Quantitative reasoning is a critical skill to analyze data, yet the assessment of such ability remains limited. To address this gap, we introduce the Quantitative Reasoning with Data (QRData) benchmark, aiming to evaluate Large Language Models' capability in statistical and causal reasoning with real-world data. The benchmark comprises a carefully constructed dataset of 411 questions accompanied by data sheets from textbooks, online learning materials, and academic papers. To compare models' quantitative reasoning abilities on data and text, we enrich the benchmark with an auxiliary set of 290 text-only questions, namely QRText. We evaluate natural language reasoning, program-based reasoning, and agent reasoning methods including Chain-of-Thought, Program-of-Thoughts, ReAct, and code interpreter assistants on diverse models. The strongest model GPT-4 achieves an accuracy of 58%, which has a large room for improvement. Among open-source models, Deepseek-coder-instruct, a code LLM pretrained on 2T tokens, gets the highest accuracy of 37%. Analysis reveals that models encounter difficulties in data analysis and causal reasoning, and struggle in using causal knowledge and provided data simultaneously. Code and data are in https://github.com/xxxiaol/QRData.
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving
Jul 27, 2023Nowadays, autonomous cars can drive smoothly in ordinary cases, and it is widely recognized that realistic sensor simulation will play a critical role in solving remaining corner cases by simulating them. To this end, we propose an autonomous driving simulator based upon neural radiance fields (NeRFs). Compared with existing works, ours has three notable features: (1) Instance-aware. Our simulator models the foreground instances and background environments separately with independent networks so that the static (e.g., size and appearance) and dynamic (e.g., trajectory) properties of instances can be controlled separately. (2) Modular. Our simulator allows flexible switching between different modern NeRF-related backbones, sampling strategies, input modalities, etc. We expect this modular design to boost academic progress and industrial deployment of NeRF-based autonomous driving simulation. (3) Realistic. Our simulator set new state-of-the-art photo-realism results given the best module selection. Our simulator will be open-sourced while most of our counterparts are not. Project page: https://open-air-sun.github.io/mars/.