 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSOTA: An End-to-End Automated Research System for State-of-the-Art AI Model Discovery
Apr 07, 2026Artificial intelligence research increasingly depends on prolonged cycles of reproduction, debugging, and iterative refinement to achieve State-Of-The-Art (SOTA) performance, creating a growing need for systems that can accelerate the full pipeline of empirical model optimization. In this work, we introduce AutoSOTA, an end-to-end automated research system that advances the latest SOTA models published in top-tier AI papers to reproducible and empirically improved new SOTA models. We formulate this problem through three tightly coupled stages: resource preparation and goal setting; experiment evaluation; and reflection and ideation. To tackle this problem, AutoSOTA adopts a multi-agent architecture with eight specialized agents that collaboratively ground papers to code and dependencies, initialize and repair execution environments, track long-horizon experiments, generate and schedule optimization ideas, and supervise validity to avoid spurious gains. We evaluate AutoSOTA on recent research papers collected from eight top-tier AI conferences under filters for code availability and execution cost. Across these papers, AutoSOTA achieves strong end-to-end performance in both automated replication and subsequent optimization. Specifically, it successfully discovers 105 new SOTA models that surpass the original reported methods, averaging approximately five hours per paper. Case studies spanning LLM, NLP, computer vision, time series, and optimization further show that the system can move beyond routine hyperparameter tuning to identify architectural innovation, algorithmic redesigns, and workflow-level improvements. These results suggest that end-to-end research automation can serve not only as a performance optimizer, but also as a new form of research infrastructure that reduces repetitive experimental burden and helps redirect human attention toward higher-level scientific creativity.
Deep Semi-Supervised Survival Analysis for Predicting Cancer Prognosis
Jan 28, 2026The Cox Proportional Hazards (PH) model is widely used in survival analysis. Recently, artificial neural network (ANN)-based Cox-PH models have been developed. However, training these Cox models with high-dimensional features typically requires a substantial number of labeled samples containing information about time-to-event. The limited availability of labeled data for training often constrains the performance of ANN-based Cox models. To address this issue, we employed a deep semi-supervised learning (DSSL) approach to develop single- and multi-modal ANN-based Cox models based on the Mean Teacher (MT) framework, which utilizes both labeled and unlabeled data for training. We applied our model, named Cox-MT, to predict the prognosis of several types of cancer using data from The Cancer Genome Atlas (TCGA). Our single-modal Cox-MT models, utilizing TCGA RNA-seq data or whole slide images, significantly outperformed the existing ANN-based Cox model, Cox-nnet, using the same data set across four types of cancer considered. As the number of unlabeled samples increased, the performance of Cox-MT significantly improved with a given set of labeled data. Furthermore, our multi-modal Cox-MT model demonstrated considerably better performance than the single-modal model. In summary, the Cox-MT model effectively leverages both labeled and unlabeled data to significantly enhance prediction accuracy compared to existing ANN-based Cox models trained solely on labeled data.
A Comprehensive Framework for Automated Segmentation of Perivascular Spaces in Brain MRI with the nnU-Net
Nov 29, 2024Background: Enlargement of perivascular spaces (PVS) is common in neurodegenerative disorders including cerebral small vessel disease, Alzheimer's disease, and Parkinson's disease. PVS enlargement may indicate impaired clearance pathways and there is a need for reliable PVS detection methods which are currently lacking. Aim: To optimise a widely used deep learning model, the no-new-UNet (nnU-Net), for PVS segmentation. Methods: In 30 healthy participants (mean$\pm$SD age: 50$\pm$18.9 years; 13 females), T1-weighted MRI images were acquired using three different protocols on three MRI scanners (3T Siemens Tim Trio, 3T Philips Achieva, and 7T Siemens Magnetom). PVS were manually segmented across ten axial slices in each participant. Segmentations were completed using a sparse annotation strategy. In total, 11 models were compared using various strategies for image handling, preprocessing and semi-supervised learning with pseudo-labels. Model performance was evaluated using 5-fold cross validation (5FCV). The main performance metric was the Dice Similarity Coefficient (DSC). Results: The voxel-spacing agnostic model (mean$\pm$SD DSC=64.3$\pm$3.3%) outperformed models which resampled images to a common resolution (DSC=40.5-55%). Model performance improved substantially following iterative label cleaning (DSC=85.7$\pm$1.2%). Semi-supervised learning with pseudo-labels (n=12,740) from 18 additional datasets improved the agreement between raw and predicted PVS cluster counts (Lin's concordance correlation coefficient=0.89, 95%CI=0.82-0.94). We extended the model to enable PVS segmentation in the midbrain (DSC=64.3$\pm$6.5%) and hippocampus (DSC=67.8$\pm$5%). Conclusions: Our deep learning models provide a robust and holistic framework for the automated quantification of PVS in brain MRI.
Diffeomorphism Neural Operator for various domains and parameters of partial differential equations
Feb 19, 2024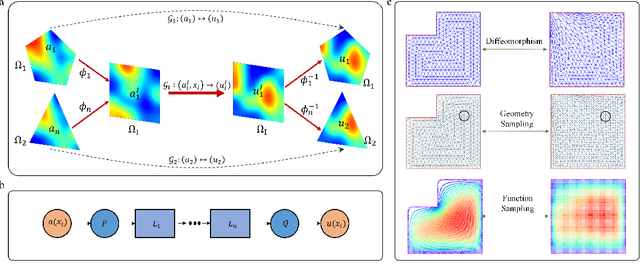
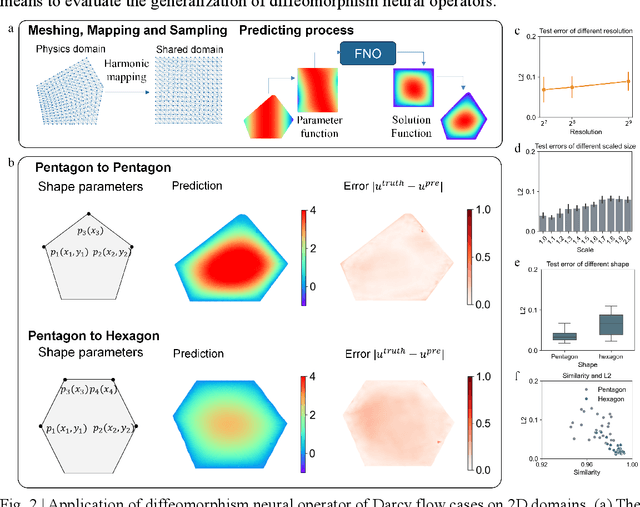
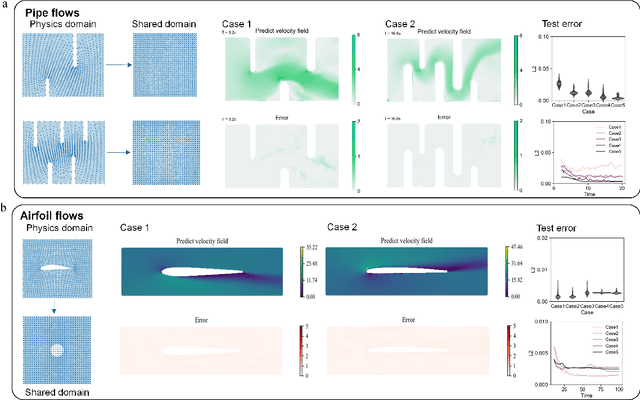
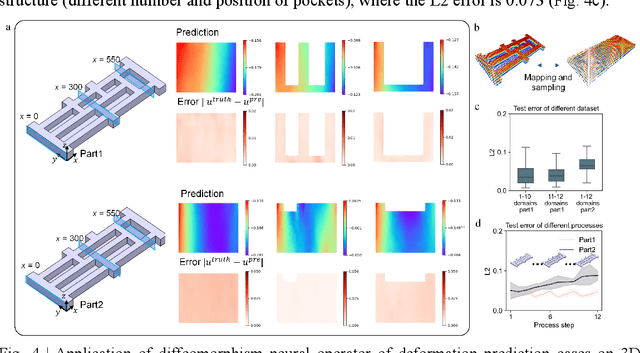
Many science and engineering applications demand partial differential equations (PDE) evaluations that are traditionally computed with resource-intensive numerical solvers. Neural operator models provide an efficient alternative by learning the governing physical laws directly from data in a class of PDEs with different parameters, but constrained in a fixed boundary (domain). Many applications, such as design and manufacturing, would benefit from neural operators with flexible domains when studied at scale. Here we present a diffeomorphism neural operator learning framework towards developing domain-flexible models for physical systems with various and complex domains. Specifically, a neural operator trained in a shared domain mapped from various domains of fields by diffeomorphism is proposed, which transformed the problem of learning function mappings in varying domains (spaces) into the problem of learning operators on a shared diffeomorphic domain. Meanwhile, an index is provided to evaluate the generalization of diffeomorphism neural operators in different domains by the domain diffeomorphism similarity. Experiments on statics scenarios (Darcy flow, mechanics) and dynamic scenarios (pipe flow, airfoil flow) demonstrate the advantages of our approach for neural operator learning under various domains, where harmonic and volume parameterization are used as the diffeomorphism for 2D and 3D domains. Our diffeomorphism neural operator approach enables strong learning capability and robust generalization across varying domains and parameters.
MC^2: A Multilingual Corpus of Minority Languages in China
Nov 14, 2023



Large-scale corpora play a vital role in the construction of large language models (LLMs). However, existing LLMs exhibit limited abilities in understanding low-resource languages, including the minority languages in China, due to a lack of training data. To improve the accessibility of these languages, we present MC^2, a Multilingual Corpus of Minority Languages in China, which is the largest open-source corpus so far. It encompasses four underrepresented languages, i.e., Tibetan, Uyghur, Kazakh in the Kazakh Arabic script, and Mongolian in the traditional Mongolian script. Notably, two writing systems in MC^2 are long neglected in previous corpora. As we identify serious contamination in the low-resource language split in the existing multilingual corpora, we propose a quality-centric solution for collecting MC^2, prioritizing quality and accuracy while enhancing representativeness and diversity. By in-depth analysis, we demonstrate the new research challenges MC^2 brings, such as long-text modeling and multiplicity of writing systems. We hope MC^2 can help enhance the equity of the underrepresented languages in China and provide a reliable data foundation for further research on low-resource languages.
The Multi-trip Autonomous Mobile Robots Scheduling Problem with Time Windows in a Stochastic Environment at Smart Hospitals
Jul 30, 2023



Autonomous Mobile Robots (AMRs) play a crucial role in transportation and service tasks at hospitals, contributing to enhanced efficiency and meeting medical demands. This paper investigates the optimization problem of scheduling strategies for AMRs at smart hospitals, where the service and travel times of AMRs are stochastic. We formulate a stochastic mixed integer programming model to minimize the total cost of the hospital by reducing the number of AMRs and travel distance while satisfying constraints such as AMR battery state of charge, AMR capacity, and time windows for medical requests. To address this objective, we identify several properties for generating high-quality solutions efficiently. We improve the Variable Neighborhood Search (VNS) algorithm by incorporating the properties of the AMR scheduling problem to solve the model. Experimental results demonstrate that VNS generates higher-quality solutions compared to existing methods. By intelligently arranging the driving routes of AMRs for both charging and service requests, we achieve substantial cost reductions for hospitals, enhancing the utilization of medical resources.
Contrastive Learning for Predicting Cancer Prognosis Using Gene Expression Values
Jun 09, 2023
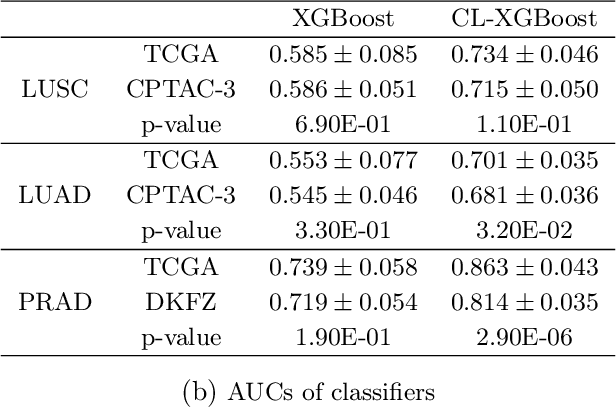


Several artificial neural networks (ANNs) have recently been developed as the Cox proportional hazard model for predicting cancer prognosis based on tumor transcriptome. However, they have not demonstrated significantly better performance than the traditional Cox regression with regularization. Training an ANN with high prediction power is challenging in the presence of a limited number of data samples and a high-dimensional feature space. Recent advancements in image classification have shown that contrastive learning can facilitate further learning tasks by learning good feature representation from a limited number of data samples. In this paper, we applied supervised contrastive learning to tumor gene expression and clinical data to learn feature representations in a low-dimensional space. We then used these learned features to train the Cox model for predicting cancer prognosis. Using data from The Cancer Genome Atlas (TCGA), we demonstrated that our contrastive learning-based Cox model (CLCox) significantly outperformed existing methods in predicting the prognosis of 18 types of cancer under consideration. We also developed contrastive learning-based classifiers to classify tumors into different risk groups and showed that contrastive learning can significantly improve classification accuracy.
From the One, Judge of the Whole: Typed Entailment Graph Construction with Predicate Generation
Jun 07, 2023Entailment Graphs (EGs) have been constructed based on extracted corpora as a strong and explainable form to indicate context-independent entailment relations in natural languages. However, EGs built by previous methods often suffer from the severe sparsity issues, due to limited corpora available and the long-tail phenomenon of predicate distributions. In this paper, we propose a multi-stage method, Typed Predicate-Entailment Graph Generator (TP-EGG), to tackle this problem. Given several seed predicates, TP-EGG builds the graphs by generating new predicates and detecting entailment relations among them. The generative nature of TP-EGG helps us leverage the recent advances from large pretrained language models (PLMs), while avoiding the reliance on carefully prepared corpora. Experiments on benchmark datasets show that TP-EGG can generate high-quality and scale-controllable entailment graphs, achieving significant in-domain improvement over state-of-the-art EGs and boosting the performance of down-stream inference tasks.
Lawyer LLaMA Technical Report
May 24, 2023



Large Language Models (LLMs), like LLaMA, have exhibited remarkable performances across various tasks. Nevertheless, when deployed to specific domains such as law or medicine, the models still confront the challenge of a deficiency in domain-specific knowledge and an inadequate capability to leverage that knowledge to resolve domain-related problems. In this paper, we focus on the legal domain and explore how to inject domain knowledge during the continual training stage and how to design proper supervised finetune tasks to help the model tackle practical issues. Moreover, to alleviate the hallucination problem during model's generation, we add a retrieval module and extract relevant articles before the model answers any queries. Augmenting with the extracted evidence, our model could generate more reliable responses. We release our data and model at https://github.com/AndrewZhe/lawyer-llama.
Entailment Graph Learning with Textual Entailment and Soft Transitivity
Apr 07, 2022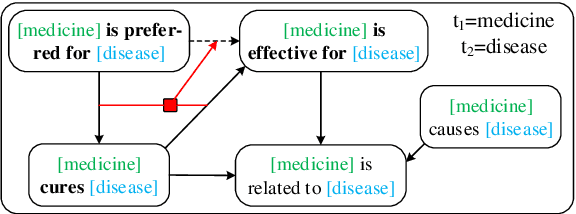
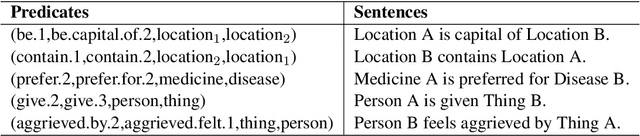
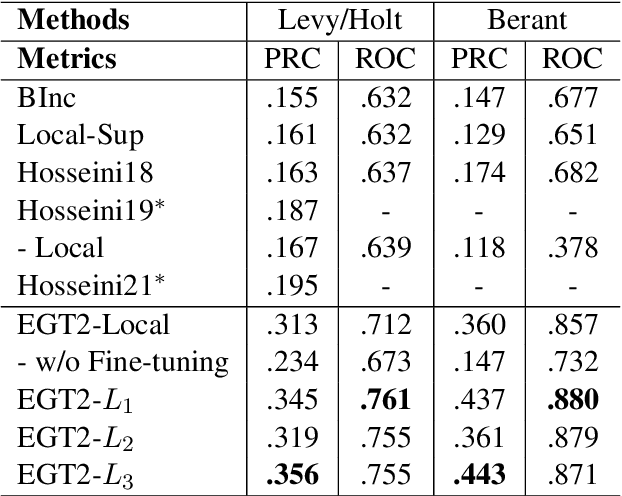
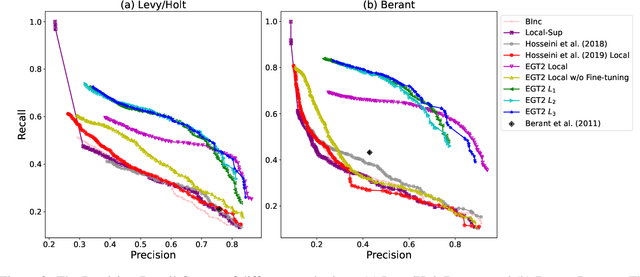
Typed entailment graphs try to learn the entailment relations between predicates from text and model them as edges between predicate nodes. The construction of entailment graphs usually suffers from severe sparsity and unreliability of distributional similarity. We propose a two-stage method, Entailment Graph with Textual Entailment and Transitivity (EGT2). EGT2 learns local entailment relations by recognizing possible textual entailment between template sentences formed by typed CCG-parsed predicates. Based on the generated local graph, EGT2 then uses three novel soft transitivity constraints to consider the logical transitivity in entailment structures. Experiments on benchmark datasets show that EGT2 can well model the transitivity in entailment graph to alleviate the sparsity issue, and lead to significant improvement over current state-of-the-art methods.